競馬×データサイエンス
貫井駿氏(以下、貫井):「実践・競馬データサイエンス」と題しまして、AlphaImpactの貫井が発表します。今回の資料は後日公開する予定なので、写真は撮らなくても大丈夫です。
まず自己紹介ですが、貫井駿と申します。

専門は機械学習をやっていまして、仕事は、まず本業でFringe81という会社でアドテックとHRテック領域のデータサイエンティストとして働いてます。その裏で、AIを使った競馬予想家としての活動も行っています。
競馬歴のほうは、中学の時に観た2005年の有馬記念、ディープインパクトが初めて負けたレースなんですけど、それ以来ずっと競馬を観続けていまして、競馬歴でいうと12年、一応「馬券は20歳から」と書いてあります。はい。好きな馬はハーツクライです。
競馬AI開発に関してなんですけど、今AlphaImpactという名前のプロジェクトとして活動を行っていて、もう2年ちょい過ぎぐらいになってます。

現在メンバーは貫井、大元、原の3人でやってまして、私は機械学習のモデル作成のところと、競馬のドメイン知識があるので、それをもとに特徴量エンジニアリングなどをするというところを担当しております。
ちなみにAlphaImpactメンバーの大元のほうは、LightGBMのコミッターで、あと、PyCon JPの明日の発表者にもなっているので、お時間ある方はそちらもぜひ。AlphaImpactの活動としては、いまnetkeiba.comの「ウマい馬券」というコーナーで予想の販売を行っているので、興味ある方はぜひよろしくお願いします。
本日の内容ですが、競馬というテーマを通して、機械学習を実践するうえでのエッセンスを紹介していきたいと思っています。まずは競馬データについてお話していきます。
この会場で競馬をやったことある、もしくは競馬が好きだという方は、どれぐらいいらっしゃるでしょうか?
(会場挙手)
あ、意外に少ないですね(笑)。なるほど。まあ、そう思ったので、まず「そもそも競馬とは何か?」というところから説明していきます。
競馬予測がデータサイエンスに適している理由
競馬っていうのは、騎手の乗った馬が人馬一体となって着順を競い合う熱いスポーツです。

それと同時にその結果を予想するギャンブルでもあります。スポーツとして見てもギャンブルとして見ても非常におもしろい、データサイエンスが関係なくても魅力的な競技であるというのが、まずポイントです。
そんな競馬という競技とデータサイエンスの組み合わせがなぜいいか、というところなんですけど、競馬というのは毎週、あるいは毎日、解くべき問題が、新しく常に追加されていきます。
例えば、データコンペのKaggleとかだと、一度問題が出ると2、3ヶ月それっきりで、最後に答えがピョンと出て、それで終わりみたいになっちゃうんですけど、競馬の場合、JRAが崩壊しないかぎりは、常に毎週新しいデータが提供されてくるので、鮮度の高いデータを常に触り続けることができるというところが、メリットの1つです。
あと、結果が出る過程をリアルタイムに映像で見ることができるということも、大きなメリットです。
例えば、機械学習の問題としての株価予測とか、Web上のユーザーの行動予測といったものは、結果に至る過程を直接目で見ることは基本的に難しいんですけど、競馬は、映像としてその着順になった過程をリアルタイムで見ることができるというところで、他の分析対象とはかなり一線を画すのかなと思っています。
あと、エンジニアリングのしがいのある豊富なデータというところなんですけど、競馬のデータは非常に種類が多いです。我々は2年以上も競馬AI開発をやってきているんですけど、今だにアイデアが全部尽きることがなくて、本当に底なしの可能性があるなと感じています。
それから、一番大事なのはやっぱり楽しいというところですね。競馬を知らない人でこれぐらいの数の方が見に来てくださってるっていうのも、1個の証拠だと思うんですけど、競馬自体が楽しいものなので、さらにデータサイエンスを掛け合わせたらもっと楽しいというところで、もし「これからデータサイエンスを始めたい」という人で、「何を解いていいかわかんないな」という人は、ぜひ競馬をおすすめします。
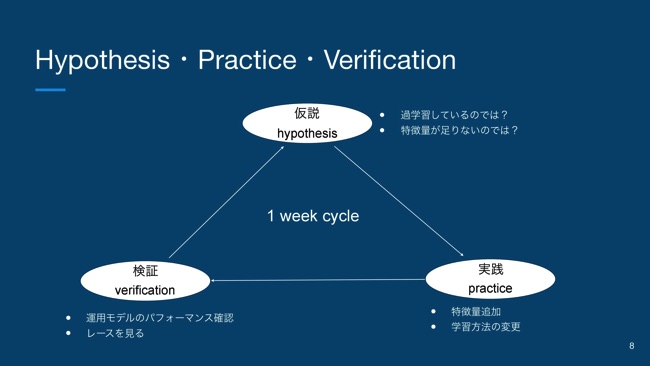
競馬予測が機械学習の対象として適しているということについてもう少し補足していくと、機械学習は仮説・実践・検証のサイクルを回していくのが基本になってくると思うんですけど、さっきも言ったように、競馬は基本的に毎週末開催されているので、1週間に1回データが追加されます。
なので、例えば「予測モデルが過学習してそうだな」とか、「特徴量が表現力足りてないな」という仮説があったとして、それをすぐに実戦投入して運用してみます。そのレースを実際に観ながら、どういうパフォーマンスなのかを確認して、また新しい仮説を立ててっていう。これを1週間という規則正しいサイクルで回し続けることができるので、非常に機械学習と相性がいいテーマです。
目的変数のエンジニアリング
次に、目的変数の設計についてお話していきます。競馬予測の基本の問題設定としては、あるレースに出走しているN頭の馬、その1頭1頭が1個のデータに対応しています。その1頭の馬に対して、どれぐらいのパフォーマンスだったかを予測する問題として考えます。
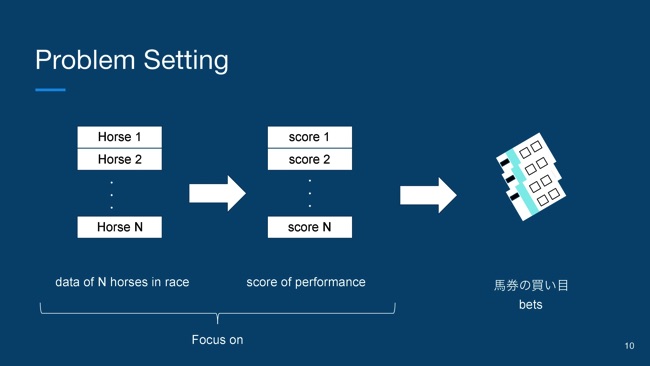
実際には、(スライドを指して)この予測されたパフォーマンスのスコアをベースにして、馬券の買い目を決定するっていうところなんですけど、そこまでいくとちょっと複雑になってしまうので、今回は1頭のパフォーマンスを予測するという部分にフォーカスしてお話していきたいと思います。
「競走馬のパフォーマンスって何だ?」っていう話なんですけど、競走馬のパフォーマンスの指標として何を選ぶべきかというのが、機械学習でいうところの目的変数を選ぶというフェーズです。
目的変数の選択というのは、つまり、どんな問題を解くかを決めることと等しいんですけど、この何を解くかという部分は、次に説明する特徴量の作成だったりモデル選択よりも非常に重要で、モデルの性能により大きな影響を与えるところなので、非常に重要な作業で、意外にここが盲点になりやすいところなので、「目的変数ってこれでいいんだっけ?」というのは、常に確認しておいたほうがいいかなと思います。
競馬において目的変数に使える基本的な変数としては、着順や走破タイム、あとは1着からの秒差や賞金といったところが基本的なパフォーマンスの指標になります。もちろんこれらのなかからどれかを選んで、目的変数に設定して予測していくのは可能ではあります。ただ、それだけだと満足のいく精度はなかなか出なくて、これらをもとにしてエンジニアリングをしていく必要があります。
目的変数のエンジニアリングをするためには、競馬予測だったら競馬というドメイン知識と、その問題設定をよく理解している必要があります。
例としては、レース内標準化というエンジニアリングなんですけど、例えば走破タイムって、1,200メートルと2,400メートルだったら、単純に2倍ぐらい時間がかかりますし、あとはその馬場状態。すごいドロドロの馬場だったら時間がかかるとか、そういった外部的なものに依存するところが大きいので、走破タイムをピッタリ当てるのはかなり難しい問題です。
でも最終的に我々が今ほしいのは、要は馬券を作るための「どれが一番強いか?」という順番なので、標準化してそういう環境バイアスを消すことによって、より解きやすい問題にすることができると。
あとは、馬券外の馬のパフォーマンスを同じくみなすというところなんですけど、競馬をやっている方だったらわかるかもしれませんが、WIN5は除いて、馬券は最大でも3着までしか考慮されなくて、それ以下は全部負けなんですね。
なので、例えば「10着と12着を正確に予測できるモデルができました」と言っても、ぜんぜん馬券的にはおもしろくなくて、その部分って別にどうでもいいんですよね。なので、もう馬券外の馬はみんな負けというかたちで処理をしてあげる、というエンジニアリングも効いてきます。
こういったことは、言われてみると「確かにな」という感じなんですけど、ちゃんと問題設定を理解して、その競馬というドメインを理解していないと、なかなか気が付けないところなので、競馬にかぎらず、機械学習に取り組む時は、「何が本当にほしい情報なんだっけ?」というのに気を付けると、その精度が伸びるのかなと思います。
特徴量の作成について
次に、特徴量の作成という話です。まず特徴量のもとになる競馬のデータについて説明したいと思います。よく競馬新聞や競馬の予想サイトだと、予想するための情報として、(スライドを指して)こういった馬柱と呼ばれる、情報が集約されたテーブルでデータが提供されます。
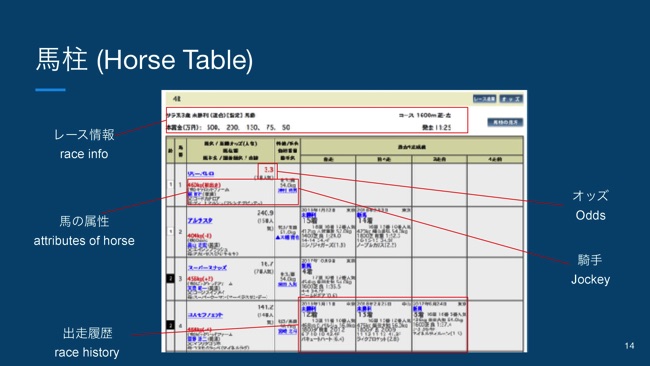
なので、一般人はこういった馬柱をもとにして、自分の予想を組み立てていきます。
こちらの馬柱を見ていただくと、レース情報だったり、馬の属性、出走履歴、オッズ、騎手など、1個の馬に紐付く情報が非常に多くて、複雑なデータ構造だなというのがわかると思います。
特徴量を作るために、適当なデータソースからデータを収集してくると思うんですけど、それをDB化した時に、当然いろんな種類のデータがあるので、たくさんのテーブルができるわけです。こういったたくさんのテーブルから、個別に1個1個特徴量を直接作るというような設計にしてしまうと、どんどんコードが汚くなって、保守性が悪化してしまうわけです。
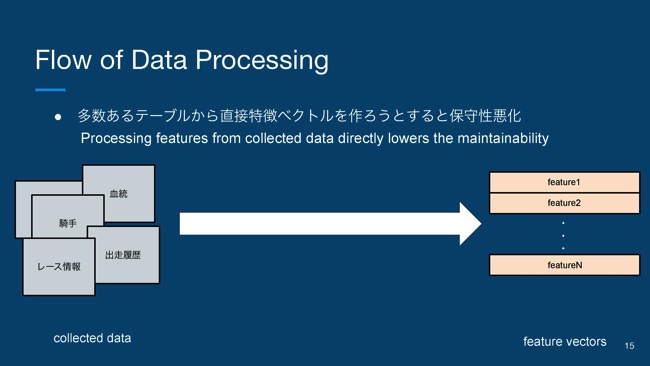
それを解決するために、この馬柱という概念をコードのなかでもモデル化してあげる。そうすることによって、散乱しているたくさんのテーブルを、HorseTableという抽象化された1個のデータとしてみなすことができるので、インターフェースが簡潔に記述できます。
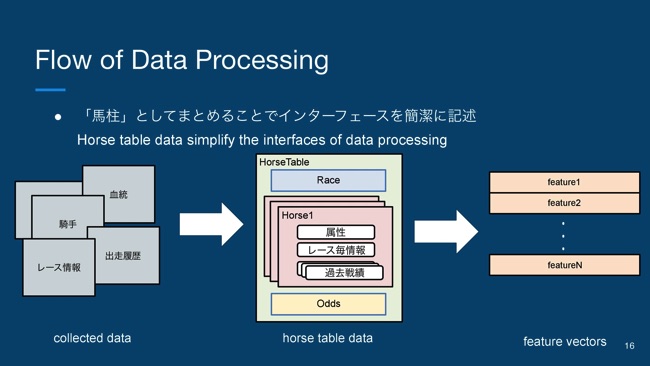
このデータ処理の部分だけじゃなくて、例えば予測だったり、他の運用のコードなどのなかでも、基本的にはこのHorseTableという1つのデータ構造でインターフェースを統一することによって、可読性もすごく上がって、いいコードが書けるといったところです。
特徴量のエンジニアリング
今まで設計寄りの話だったんですけど、「じゃあ、実際にどういう特徴量のエンジニアリングをしていくか?」という話に入っていきます。
競馬のデータのなかで一番癖のあるのが、この出走履歴のデータです。(スライドを指して)先ほどの馬柱でいうとこの部分。
「この出走履歴をどう特徴量にしていくのか?」というのが、ここでの問題です。

一番簡単なのは、過去X走、例えば過去5走まで見るといったことを決めて、その情報をそのまま横に並べて特徴量に加えるという方法が考えられます。例えば過去2走前の馬体重とか、過去3走前の走破タイムみたいなかたちで、特徴量として加えていきます。
このやり方の問題点としては、非常に簡単ではあるんですけど、何走前まで見るかを決めるところで、その「何走前まで」というのが大きくなりすぎると、欠損データがどんどん増えて、すごいスパースなデータになっていきます。すると計算コストが無駄に増えていって、なかなか学習が進まないということになります。
別のやり方としては、その過去X走の成績を集計するという方法が考えられます。例えば過去5走で何回勝ったかとか、どれぐらい賞金稼いだか、賞金の平均とか、そういった感じですね。
このやり方だと、次元数がこの何走前まで見るかっていう部分に依存しないので、次元爆発みたいなことは抑えられると。ただ、なにかしらの統計値に丸めてしまうので、情報の欠損が生じてしまうっていうのが1個の問題です。
それと似てるんですけど、過去X走じゃなくて期間、過去1年間とか半年間みたいなかたちで、期間を指定して成績を集計するっていう方法もあって、それも同じような感じです。
このなかで、じゃあどのやり方がいいのかっていう話なんですけど、それぞれいいところと悪いところがあって、どれか1つを選ばなきゃいけないわけじゃないので、とくに予測モデルの制約がなければ、思い付いたものは全部入れてくっていうのが、一番いいやり方なのかなと思います。
次に、カテゴリカルデータの話です。競馬にはいろいろなカテゴリがあります。例えば馬名もそうですし、騎手とか調教師、血統に関するものや、コース、どの競馬場なのか、芝なのかダートなのかみたいな、そういうのは全部カテゴリカルなデータです。

さらに、競馬には数値特徴量として扱うべきか、カテゴリとして扱うべきか、けっこう微妙に迷うのがあって。例えば馬番とか、レース番号、距離みたいなやつですね。距離って、ただ単純に「長ければ長いほど……」みたいなよりは、例えば「東京・芝・2,000」は特殊な形状だから、この「2,000」という数字自体に意味がある、みたいな。そういった場合は、例えばカテゴリとして表したほうがいいと。
なので、けっこう迷うことはあるんですけど、迷ったらさっきと同じように両方入れてしまうっていうのが、一番いい方法になります。
カテゴリカルデータを数値化する方法
次に、カテゴリデータっていうのは、基本的になにかしらの数値化をするんですけど、もっとも一般的に行われてるのはOne-Hot-Encodingと呼ばれる方法で、そのカテゴリ数分だけの0・1ベクトルを用意して、対応する次元だけ1を立てて、あとは0というようなベクトルにするというやり方ですね。これはカテゴリ数が多いと非常に次元数が増えてしまうので、出現回数とかで足切るなどの工夫が必要になってきます。

あとは、Target Encodingというやり方があるんですけど、過去のデータから該当カテゴリの目的変数を集計して特徴量とする、というやり方があります。例えば同父馬の平均着順みたいなかたちに、ある馬と同じお父さんの馬のデータを取ってきて、そのデータの平均の着順を取るとか、なにか勝率を取るとか、そういったかたちで特徴量化することができます。
基本的には目的変数を集計するっていうのがTarget Encodingなんですけど、目的変数にかぎらずに、的中率とか回収率とか、いろいろな数値指標で集計することが可能となります。
いまのTarget Encodingの考え方をもう少し一般化していくと、大量の特徴量を機械的に作成することができるようになります。集計する時は、考え方としては、「誰が」「どんなレース条件で」「どのような統計値になったか」という3つの組み合わせで特徴量は表現できます。
なので、この掛け合わせで機械的に特徴量を生成できるので、我々はこういうやり方で、1,500ぐらいの特徴量を予測に使っています。

けっこうこれを入れただけでも、予測モデルの性能がかなり飛躍的に上がったりするので、まあ良質な特徴量を入れていくのも大事なんですけど、とりあえず……何ですかね、力で殴れるところは殴っとくみたいな感じでやっていくのも、1個の戦略としてはありかなと思います。
Smoothingとは何か
しかし、こういった集計値を使う特徴量には、ちょっと問題があって。このように組み合わせていくと、「誰が」と「どのレース条件で」の組み合わせが、非常にレアなケースが生じてくると。その集計対象の数が少なくなると、当然統計値の自信度、確信度が低くなってしまうので、そういったところでガタつきが出てしまいます。
例えば的中率50パーセントといった時に、2回走っただけで1回勝った場合の50パーセントと、1,000回走って500回勝った場合の50パーセントっていうのは、確度としては後者のほうが高いだろうと。
そういった直感を実現するためにSmoothingという後処理があります。
該当カテゴリが少ない場合は、集計値の全体平均に近づけるような処理をするという、割とシンプルな処理なんですけど、計算式としてはこちらに書いてある通りになります。

「R」が該当カテゴリの集計値で「Raverage」が全体平均、「N」がそのカテゴリの出現頻度だとすると「N」が限りなく十分大きくなれば、左のケースが1になって、0だと完全に全体平均と一致するような処理になっています。
この「α」はカテゴリごとに最適値を選択する必要があるので、例えば、目的変数との相互情報量だったり、そういうのを見てカテゴリごとに最適値を選択していく必要があります。
こちらの例としては、的中率がAが50パーセント、Bが40パーセント。これだけ見るとAのほうが的中率が高いのかなと思うんですが、カウントが2、カウントが100としたときに「α」を0.1と置いて計算すると、Bのほうがやっぱり強いよねという計算結果になります。
これは非常に直感に適しているので、これを入れても基本的には悪くなることはないと思います。
少し趣向を変えて、今までに説明してきたことと比べると地味になりますが、季節特徴量の特徴量エンジニアリングもやっています。

例えば、競馬だと暑い時期は牝馬が強くなるけど、春の時期だと発情期とかでその牝馬が急に弱くなったりということがあって、季節は1つの大きなファクターとして考えられています。
そういう季節を入れるときに、1月から12月を普通のカテゴリとして入れていくのももちろんあるんですが、もう少し賢いやり方として、この円周上に1月から12月を並べてサイン・コサインで表すことによって、もう少し賢いエンコーディングができるようになります。
季節だけでなく、基本的に周期性のある特徴量変数だったら、基本的にこのやり方でできると思うので、もし使えるところがあったらぜひ使ってみることをオススメします。
予測モデルの学習について
次に予測モデルの話です。我々は予測モデルとして、LightGBMと言われるライブラリを使っています。これは勾配ブースティングというアルゴリズムの高速で軽量で高精度な実装になっています。

世間だと一昔前だと「XGBoost」がすごく流行っていたんですが、最近はそれを抜いて1番人気のある勾配ブースティングの実装になっているように感じます。
LightGBMの良いところとしては、カテゴリ変数をカテゴリ変数として扱うことができるんですが、先ほどカテゴリデータのエンコーディングという話があったんですが、それをしなくてもカテゴリ変数として入力に受け付けてくれるのが良いところで、この機能は「XGBoost」には今のところ実装されてない機能です。
あとは、欠損値を欠損値として扱うことができる。これは競馬予測においてかなり重要な、というかマストな機能なんです。
競馬は先ほど言ったように過去の出走履歴の欠損値や、普通にそもそもデータが取得されてないみたいな欠損値がたくさんあるので、要は欠損値をどうするか問題は非常に大きな問題です。
LightGBMだったらその欠損値を、欠損しているという情報の特徴として普通に学習してくれるので、非常に助かる。欠損値埋めをする心配もありません。
あと、AlphaImpactの大元がLightGBMのコミッターになっているので、例えば、我々のプロジェクトで不都合な変更が入りそうだったら、全力で止めるみたいな。そういった力技とかもできるという感じです。
モデル学習のアーキテクチャ
モデル学習のアーキテクチャとしては、一応こんな感じの図になっています。
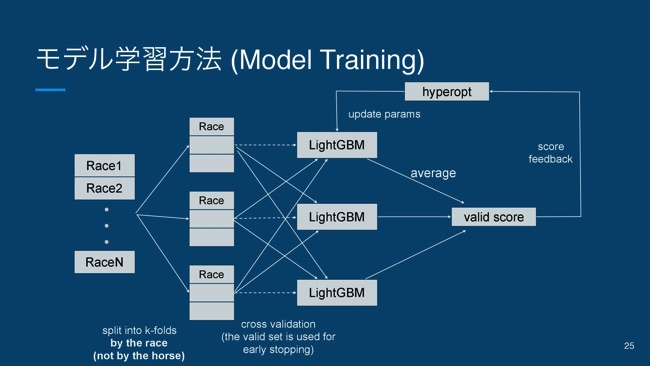
基本的にはクロスバリデーションでやっているんですが、競馬独特なところとしてはk個のfoldsに分けるときに、サンプルごとじゃなくて、レースごとにスプリットしています。
どうしてこうするかと言うと、サンプルごとに分けてしまうと、異なるフォールドに同じレースのデータが入ってしまうので、そこにリークが生じてしまう恐れがあります。それを避けるために、レースごとにスプリットをしています。
あとはクロスバリデーション。普通にやっていくんですけども、バリデーションデータはLightGBMのEarly stopping、過学習する前に止める機能を使うために利用して、最終的にそのバリデーションのスコアをhyperoptに入れて学習していく。
このhyperoptと言うのはパラメータを探索するための探索アルゴリズムになっていて、こちらのhyperoptについて説明すると、これは「ベイズ最適化」と呼ばれる探索方法で、その中でもTree-structured Parzen Estimator(TPE)と呼ばれるアルゴリズムが非常に優秀です。

このTPEは普通のgrid searchとかrandom searchに比べて、非常に少ない回数の探索で良いパラメータを見つけることができます。そのパラメータの探索と、まだ探索してない部分の探索と活用を効率良く行ってくれるアルゴリズムになっています。
ですが、LightGBMがそもそもハイパーパラメータが非常に多いので、hyperoptを使ったとしても100回とか200回ぐらいの探索をしていかないといけません。なので、LightGBMも軽量なんですが、やっぱりトータルだと時間はかかってしまいます。
一応我々は競馬AI開発用に自前の計算サーバーを持ってはいるんですが、いろいろな特徴量でエンジニアリングして、特徴量次元数が馬鹿でかくなってきたときに、計算が回しきれなくなってしまうので、最近はGCE(Google Compute Engine)を使ってやっています。
それもコストがかかってしまうので、そうしないためにプリエンティブインスタンスを活用しています。これはGCEの計算余剰資源を利用しているので、だいたい70パーセントオフぐらいで使えて、非常にお買い得です。
LightGBMのチューニングにおけるTips
なんですが、もちろん悪いこともあります。予告なくインスタンスが切られ、しかも最大24時間という制約があるので、結構困り者なんです。ですが、どうしてもこのプリエンティブでhyperoptを回したいときには、hyperoptの探索の中間状態がTraialsオブジェクトというのがあって、それに保持することができます。
なので1探索回すたびに、それをpklかなにかで保存しておけば、万が一切れた場合でも途中から再開することができ、いつ切れても安心して回すことができるようになるので、これは結構おすすめのやり方だなと思います。
あと、LightGBMのチューニングのTips的なところなんですが、カテゴリ変数をカテゴリ変数として扱えると言ったんですが、やはりダミー化したほうが精度が出ることが多いなというところはあります。
カテゴリの数が大きくなりすぎると、あまり精度が出ないということはドキュメントにも確かに書いてあったんですが、どうやらダミー化したほうが精度は出ます。あと、Early stoppingは入れないとすぐに過学習してしまうので、これは必須だなというところです。
あと、random_stateによっても精度が変わるということもあり、colsample_bytreeとかsubsampleルみたいなのをやっていると、学習の度に学習結果に影響してくるので、random_stateを同じパラメータで変えてみたり、複数のrandom_stateをやって平均を取るみたいなことは必要かなと思います。
モデル学習は直接関係ないんですけど、LightGBMは特徴量の分析をすることもできます。1番よくやられているのは、feature importanceを見てどの特徴量が効いているかというところの分析だと思うんです。
ある入力データに対する予測で、どれぐらい特徴量が効いたのかについてもすることができます。こういったミクロの特徴量分析もできるツールで、例えばあるレースにおいて、どのファクターが効いて、その予測に至ったかというのがわかるようになります。これはビジュアル的にやれるSHAPというのもあるんですが、これも同じ考え方でできます。
こちらも一応参考程度に載せたので、もし興味のある方は見てください。
この入力データにおける予測の根拠。予測の寄与度を応用すると、ちょっと見にくいかもしれないんですが、こんな感じです。これは去年のジャパンカップの予測になっていて、例えば、騎手とか血統とか調子みたいな特徴量が、何千の特徴量を6個とか7個ぐらいに分類して、各貢献度を合計したものをここに表示しています。
そうすることによって、こういうチャートを出すことができます。
このチャートを見て、とくに何かすごく分かるわけじゃないんですが、こういうの出すとなんかテンションが上がるなという感じです。
予測モデルの評価について
最後に予測モデルの評価について紹介していきたいと思います。我々はモデルの評価指標としてnDCGと呼ばれるものを使っています。nDCGというのは、検索やレコメンドなどのランキング問題でよく使われる指標になっていて、関連度の高いデータをより上位に予測できたときに値が大きくなる。最大値が1という指標になっています。
この関連度とは何かという話なんですが、これは1つである必要はなくて、なるべくいろいろな関連度を定義して、モデルの性格を掴んでいくのが大事になってきます。

具体的に、関連度はどういったことが挙げられるかというと、実際に使っているものの例をいくつか挙げてます。

基本的にnDCGの関連度は非負の値で、大きければ大きいほど良いというルールを満たしていれば適用することができます。1番はじめに思いつくのは、多分着順です。着順の、大きければ大きいほど良いという条件を満たすために、逆数を取って着順の逆数を関連度として定義できます。
この場合は、着順の全体を評価していることになるので、結構馬券とかに絡まない部分も評価してしまっているnDCGになっています。
それではちょっと微妙なので賞金というのが結構オススメなnDCGの関連度になっています。賞金というのは、5着まで与えられる報酬なので、惜しくも馬券に絡まなかったぐらいが5着なんです。
その5着分のところを正しく予測できたか評価するには、結構prizeが良いかなという感じです。
あと、一応ちゃんと馬券内に絞るために、4~5着はゼロとして、3着までの賞金にしたり、あとはどれぐらい収益性が良かったかを調べるために、複勝の払い戻しだったり、オッズとどれぐらい似ていたかという単勝支持率。こういったところが競馬におけるnDCGの評価指標としては使えるかなという感じです。
実際に評価の比較例なんですが、ちょっと遠くて見えないかもしれませんが、AとBという2つのモデルの性能指標があって、これを見るとAのほうが着順やprizeのnDCGが高くなっていて、Aのほうが的中精度が高いのが分かります。

ですが、1番下の単勝支持率のnDCGはBのほうが高くなっています。一見Bも良さそうに見えるのですが、単勝支持率のnDCGはオッズにいかに近いかを表しているので、Bは人気どおりの予測をしているにも関わらず、Aよりも的中精度が低いのでBはダメダメだなというのが、ここで分かります。
こんな感じで1つの精度だとなかなか読み取れないことも、複数のnDCGの観点を与えることによって、そういったことが読み取れるようになります。
競馬は機械学習のテーマとして最高である
やっぱり競馬なので、nDCGだけじゃなくて、簡単な馬券の買い方のルールにおける馬券の成績というのも、1個見といたほうが良いということで、ここだとTop-NをBox買いです。
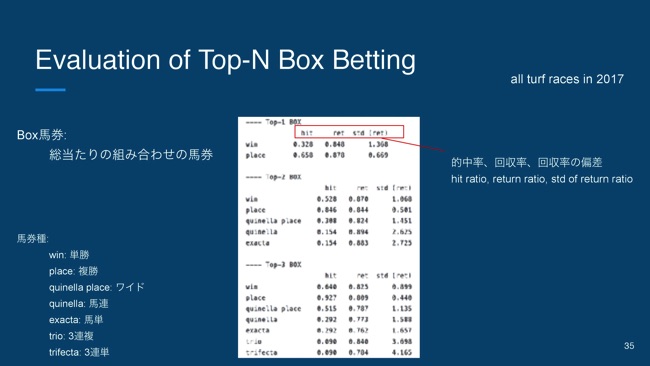
Box馬券というのは、与えた馬の総当たりの組み合わせの馬券になっています。例えばこの表だと、左から的中率と回収率と回収率の偏差というのが出ていて、つまりすべてのレースで上位1頭の単勝を買うと、的中率が32.8パーセントで回収率は84パーセントぐらいになるのが分かります。
ちなみにさっきのモデル。2017年のすべての芝のレースの評価結果で、だいたい1,600レースぐらいあります。これと同じ学習データで、目的変数と特徴量エンジニアリングとして変えて作ったモデルの性能がこちらになります。
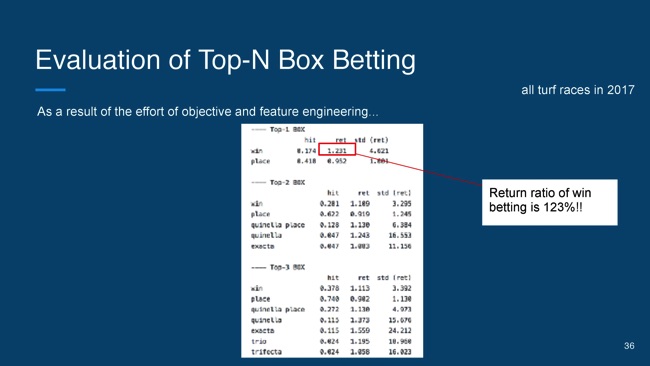
Top1の単勝の的中率は17パーセントとやや低めなんですが、回収率は123パーセントという感じです。1,600レースのTop1の単勝だけ買い続けるだけで、123パーセントの回収率になります。
同じデータを使っていても、目的変数のエンジニアリングだったり、特徴量を変えたりするだけで、ここまで伸ばすことができる。この結果を見たときは1週間ぐらいはすごいハッピーな気持ちになりました。
あと定量評価のほかに定性評価も重要です。定性評価というのは、つまり実際に予測結果を目で見てみることなんですけど、評価データの中から代表的な数レースとかをピックアップして、実際に予測で見てみます。
おおむねまともな予測になっているかどうかだったり、例えば、競馬だと海外から出走してくる馬もたまにいるんですが、そういったエッジケースに対して予測ができているかとか、なかなかnDCGみたいな、マクロな評価だけだと気づけないような、そういった予測モデルの弱点みたいなものがここで気付けるようになるので、定性評価は必ずやっていたほうがいいかなと思います。
ただ、その目で見た評価にあまり過信してしまうとモデルの過適合になってしまったりするので、それはほどほどにしておいたほうが良いかなと思います。
あと実際に、自分が手塩に育てた予測モデルが出す結果というのは、一段と感慨深いものがあるので、そういったものを見るとこれもテンションが上がって、そのあとのモチベーションにつながってくるので、定性評価はぜひやったほうが良いと思います。
まとめとなります。

競馬は機械学習のテーマとして最高である。あと目的変数と特徴量のエンジニアリングは精度の改善のために必須なので、そこはすごく力を入れる。LightGBMは競馬予測においても非常に有効な予測モデルである。
最後に、モデル性能は定量だけではなくて、定性評価。その両方で評価するのが良いということです。
以上で発表は終わります。
(会場拍手)