コロナ対策の全国調査システムを開発
小川拡氏:「2500万ユーザーから回答を集めた新型コロナ対策のための全国調査を1週間で作った話」と題して、小川拡が発表いたします。よろしくお願いいたします。
最初に私自身について簡単に紹介します。私は2015年に新卒でLINEに入社し、現在6年目です。サーバーサイドのソフトウェアエンジニアとしてLINE公式アカウントの管理画面「LINE Official Account Manager」の開発に携わっています。過去にはSmart Channel、LINE広告、LINEポイントなどの開発にも参加していました。

みなさんは(スライドを指して)こちらのメッセージをご覧になったことがありますか? これはLINEが実施した新型コロナ対策のための全国調査への回答をお願いするメッセージです。

本日はこの調査の裏側についてお話したいと思います。新型コロナ対策のための全国調査ではLINEユーザーのみなさんの体調やCOVID-19への感染予防について伺いました。
これまでに5回にわたって調査を実施しており、回答データは個人を特定できないかたちで厚生労働省に提供され、感染拡大防止のための有効な対策検討に役立てられています。ここで本調査に関する3つの数字をしたいと思います。

1つ目は8,300万です。これは全国調査への回答をお願いするために送信したメッセージの件数です。日本国内のLINEの月間アクティブユーザーの約8,300万人(※調査実施時点)全員に対してメッセージを送信しました。
2つ目は約2,500万。これはいただいた回答の件数です。多くのユーザーにご協力いただいたことで絶対数としてもユーザー数に対する割合としても驚異的な数の回答を集めることができました。
さて3つ目の数字は6です。これは先ほどの2つと比べると小さな数字です。この数字はプロジェクトがスタートしてから調査を実施するまでの準備期間の日数を示しています。

6日間で回答システムを開発した経緯
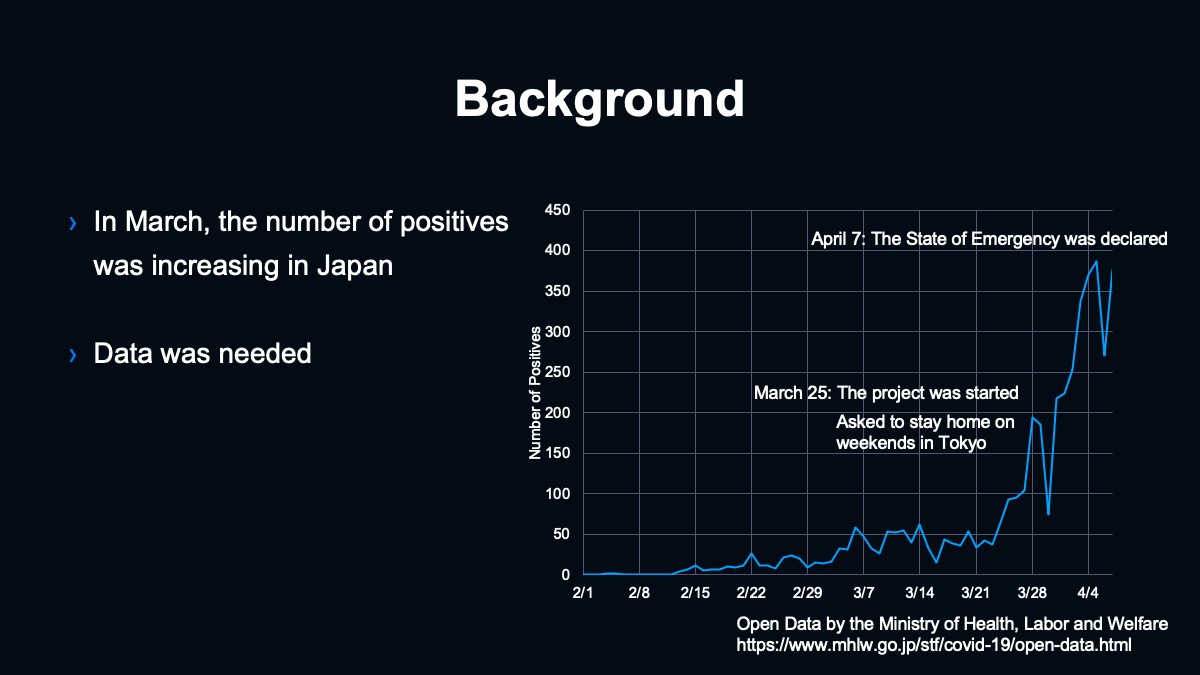
ここからはなぜ6日という短い期間で調査を実施する必要があったのか。その背景についてお話します。第1回の調査を実施した2020年3月には日本国内でCOVID-19の感染者数が増加しつつありました。そんな中、厚生労働省のクラスター対策班の中では対策に利用可能なデータを必要としていました。
加えて4月7日に7都府県で緊急事態宣言の発令に至ったように、とくに3月下旬から感染者数の増加が加速していました。プロジェクトを開始したのは3月25日だったのですが、同日に東京都では週末の不要不急の外出自粛が呼びかけられており、我々としてはとにかく何らかのかたちでクラスター対策班に協力したいという思いがありました。
感染拡大対策のためにデータが求められている中、我々としてできることを検討した結果、全国調査を実施することにしました。多くのユーザーと接点を持っているLINEの強みを活かし、我々がLINEを通じてクラスター対策に必要な調査を実施することによって、短期間に多くの回答データを集めることができると考えました。前例のない取り組みで失敗するリスクもありました。しかし、我々にしかできない取り組みで社会的な責任を果たすべきと考え、厚生労働省からの受託ではなく我々が主体となって調査を実施しました。

調査を実施するにあたってどのような方法で実現するのがよいか検討したところ、大きく3つの方法が候補に上がりました。
1つ目は、我々がすでに提供している調査プラットフォームであるLINEリサーチを利用する方法です。既存のシステムを利用できれば素早く調査を実施できます。しかし、LINEリサーチのサービス特性上、10万人規模の調査を柔軟かつスピーディに行うのには適しているものの、今回のような全国規模の調査を想定したものではないため、負荷対策に時間が必要でした。
2つ目は、アンケートシステムを提供されている他の企業と協力して調査を実施する方法です。(スライドを指して)こちらは詳細な検討まで至らなかったのですが、社内のコミュニケーションと比べると、他社さまとのコミュニケーションには時間がかかることが想定されました。今回は、できる限り早く調査を実施したかったためこの方法は見送りました。
3つ目は、まったく新しいシステムを開発する方法です。当然ですが、これも簡単なことではありません。しかし、すでにあるシステムに何らかの改修を行うのと比べると、既存の実装に制約を受けることがありませんし、今回の調査のために特化したものを作ることができます。結果として最速で調査を実現できると考え、この方法を選択しました。

少数精鋭で素早い開発スピードを可能に
(スライドを指して)こちらがプロジェクト開始から調査実施までのタイムラインです。6日間の準備期間には仕様や調査内容の策定から、リリース前に必要なQAまでのすべての作業を含んでいます。そのためシステムを構築するための開発期間という意味だと実質的には3日間しかありませんでした。
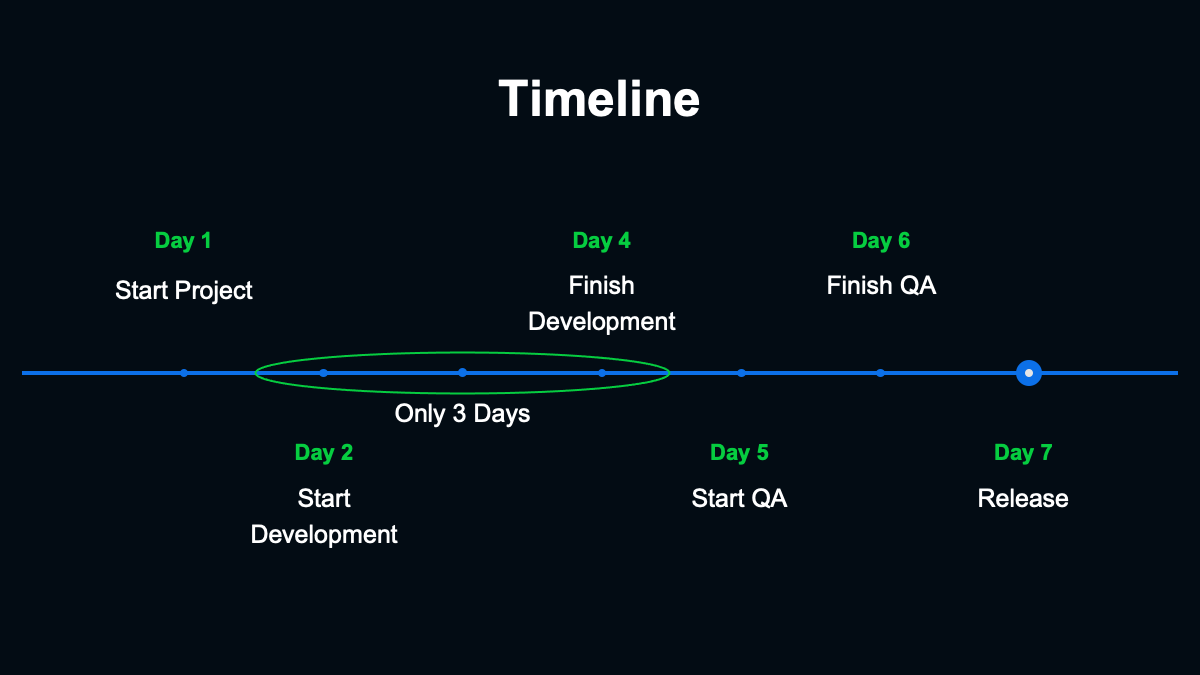
開発に取り組んだチームを紹介します。開発に主に取り組んだのがサーバーサイドエンジニアが1人、フロントエンドエンジニアが1人、プランナーが1人の合計3人です。もちろん3人だけで開発できたわけではなくインフラ、セキュリティ、データサイエンティスト、DBA、連携するサービスのエンジニアなど多くの人たちの協力があって実現しています。

コアメンバーを少人数とすることで、開発を素早く進行できると考えました。なお本プロジェクトのプロダクトマネジメントやフロントエンド開発については、すでにインタビュー記事やプレゼンテーションが公開されています。興味のある方はそちらもぜひご覧ください。

本日はこれまで詳細を公開していなかったサーバーサイドの開発を中心にお話したいと思います。開発にあたっては多くのチャレンジがありました。まず感染拡大の状況に対していち早くデータを集める必要があったため、可能な限り早くシステムを構築しなければなりませんでした。
それに加えて全国のLINEユーザーを対象に調査を行うため、非常に多くの回答が寄せられると想定されます。これを処理できるシステムを構築する必要があります。その際システムトラブルによって停止することがないようにしなければなりません。
システムトラブルが発生した場合、調査にご協力いただいているユーザーのみなさまにご迷惑をおかけしてしまうことになります。それによって、我々が信頼を失うのはもちろんですが、それだけにとどまらず、社会に対するネガティブな影響も大きなものになる恐れがありました。紹介したようなチャレンジがある中で、確実にシステムを完成させてリリースするというのは容易なことではありません。
開発にあたって心がけた3つのポイント
この難しい状況で、我々は3つのポイントを意識して開発を進めました。1つ目に必要最小限の仕様のみを実装し、極力シンプルなシステムを作ることにしました。限られた期間での開発ではできることには限界があります。そんな中でシステムをかたちにするために、まずは実装するものを絞り込むことが必要でした。
2つ目に段階的に開発を進めることにしました。システムが動作可能な状態を維持しつつ段階的に拡張していくことで、不確定要素の多い開発でも柔軟に対応できます。
本プロジェクトでは開発スタートの時点で仕様が固まっておらず、仕様の確定を待っている時間もありませんでした。そのため開発と並行して仕様を決めていき、開発の進行状況を見ながらどこまで仕様を盛り込むかを決めていくかたちにならざるを得ませんでした。
3つ目にシステムトラブルをできる限り設計段階で回避するようにしました。短期間での開発ということもあって、各コンポーネントを十分に作り込めない可能性は通常よりも高いと想像できます。そんな中でも目に見えるかたちでのシステムトラブルは回避できるように設計を工夫しておくことが重要です。

当初のシステム開発と回答フロー
ここからは実際に開発したシステムを紹介します。まず、第一段階として調査ページを表示する仕組みと回答データを保存する仕組みを実装しました。作成したシステムを紹介する前にユーザーが調査に回答する際のフローを簡単にご説明します。まず、ユーザーは左のようなメッセージを受け取ります。このメッセージには調査への回答のお願いに加えて最初の設問が含まれています。
トークで最初の設問に回答すると調査ページが表示され、続きの設問に回答できます。調査ページはLINEアプリ内のIn-Appブラウザで、アプリの機能かのように使えるようにしました。この仕組みはLIFFというプラットフォームで提供されているもので、アプリについてとくに追加の開発は行っていません。調査ページで回答を終えて最後に回答を送信すると、Thanksページが表示されます。
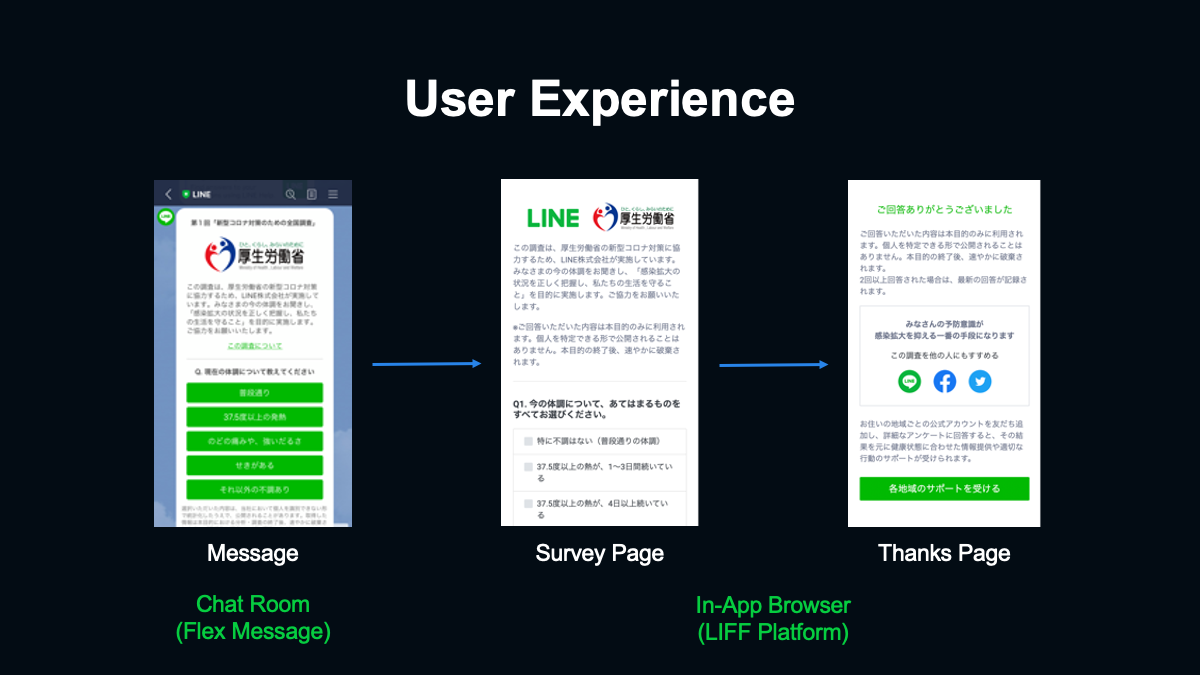
以上がユーザーが回答する際のフローです。これらの機能を実現するために最初に考えたのが、(スライドを指して)こちらのようなシステムです。設問のマスターデータを基に調査ページを表示し、回答を受け取って何らかのストレージに保存する機能を持ったアプリケーションを実装するというものです。
ただこの構成には懸念がありました。まず時間内にアプリケーションを実装できるかどうかわかりませんでした。加えて短時間で実装したアプリケーションが高トラフィックに対応できることを保証するのも難しそうでした。
限られた時間でかたちにすることを考えると、実装量を減らす必要がありました。これは実装にかかる時間を減らすという意味もありますし、新しいコードが減れば予期せぬ挙動に遭遇する確率を減らすことにもなります。

nginxを中心にシステム構築
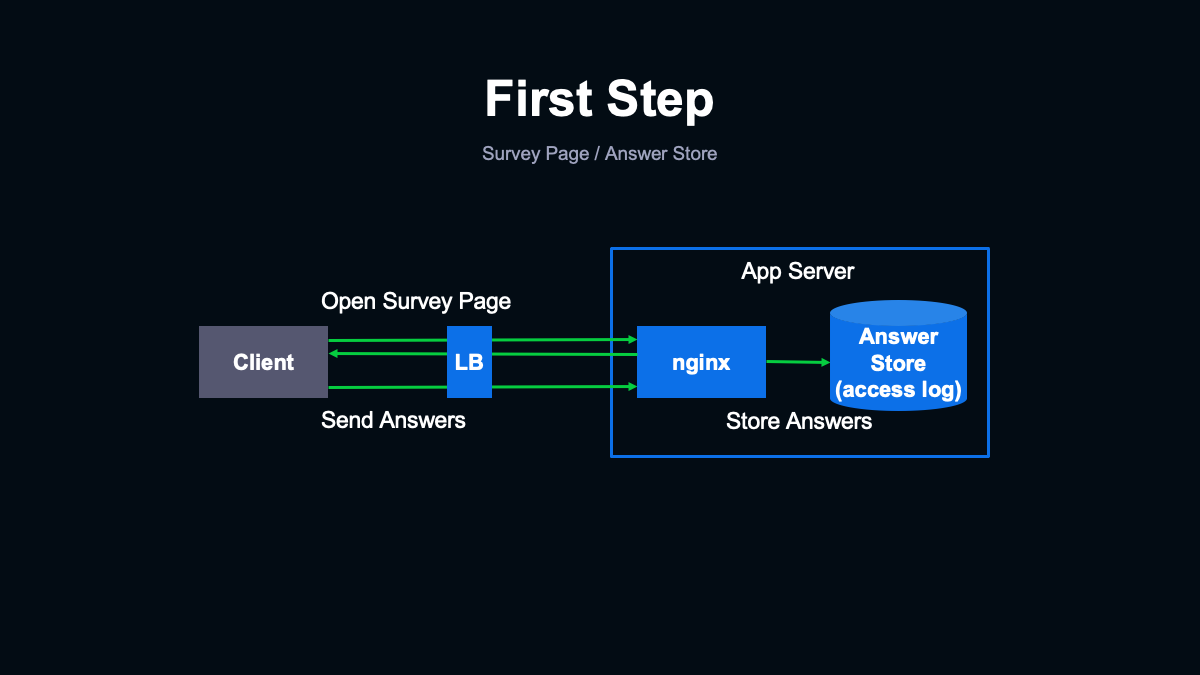
実際に作成した第一段階のシステムが(スライドを指して)こちらです。できるだけ短期間で準備でき、多くのトラフィックを確実に安定して処理できる構成を検討した結果、nginxを中心にシステムを構築することにしました。
これまでnginxを利用してきた実績から、最小限の検証でも高トラフィックを安定して処理できると考えました。まず回答フォームの設置された調査ページは、サーバーからは単に静的なHTMLとして返すようにしました。設問の内容についても、とくにデータベースなどには格納せず、ページ内にハードコードすることにしました。
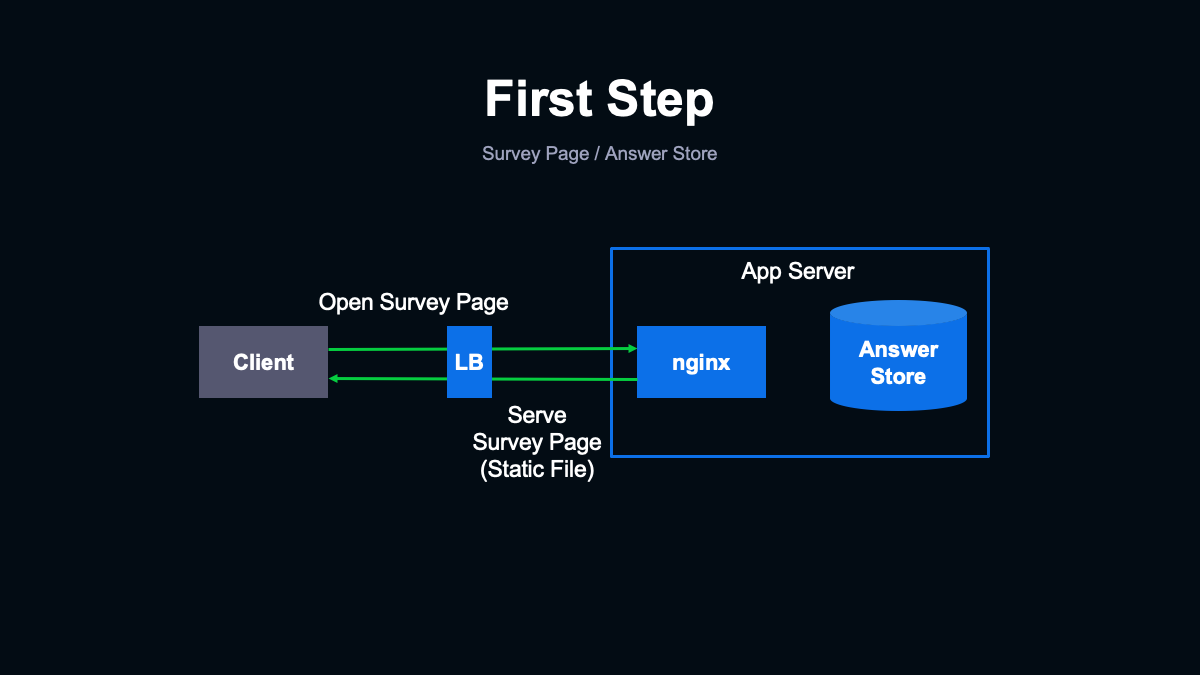
今回はメッセージ内で回答した内容によって調査ページの設問を切り替える仕様がありましたが、そのような処理はJSで行うことにして、サーバー側ではユーザーによるページの出し分けが必要ないかたちにしています。ユーザーが回答を終えると回答内容をサーバーに送るリクエストが発生します。
この回答の送信処理は2段階で行うようにしました。まず、調査ページを開くタイミングでメッセージ内の設問への回答を送信し、すべての設問に回答したタイミングですべての回答を送信しています。これによりユーザーが途中で離脱してしまったとしても最初の設問の回答だけは集計できるようにしています。

調査ページの送信と回答データの保存を行う仕組み
回答を受け取って保存する部分についてもnginxを利用して実現しました。nginxで回答を保存するのはどのように行うのか、疑問に思うかもしれません。
今回は回答内容をアクセスログの一部として書き出すようにしました。もともとすべてのリクエストでアクセスログを出力しているため、静的なファイルを配信する場合と比べて追加のオーバーヘッドはほとんどありません。このような使い方はしたことがない方も多いと思います。
しかし、社内では広告プラットフォームのイベントログを受け取るサーバーなどが同様のアプローチを取っていて、実績のある仕組みだったため採用しました。
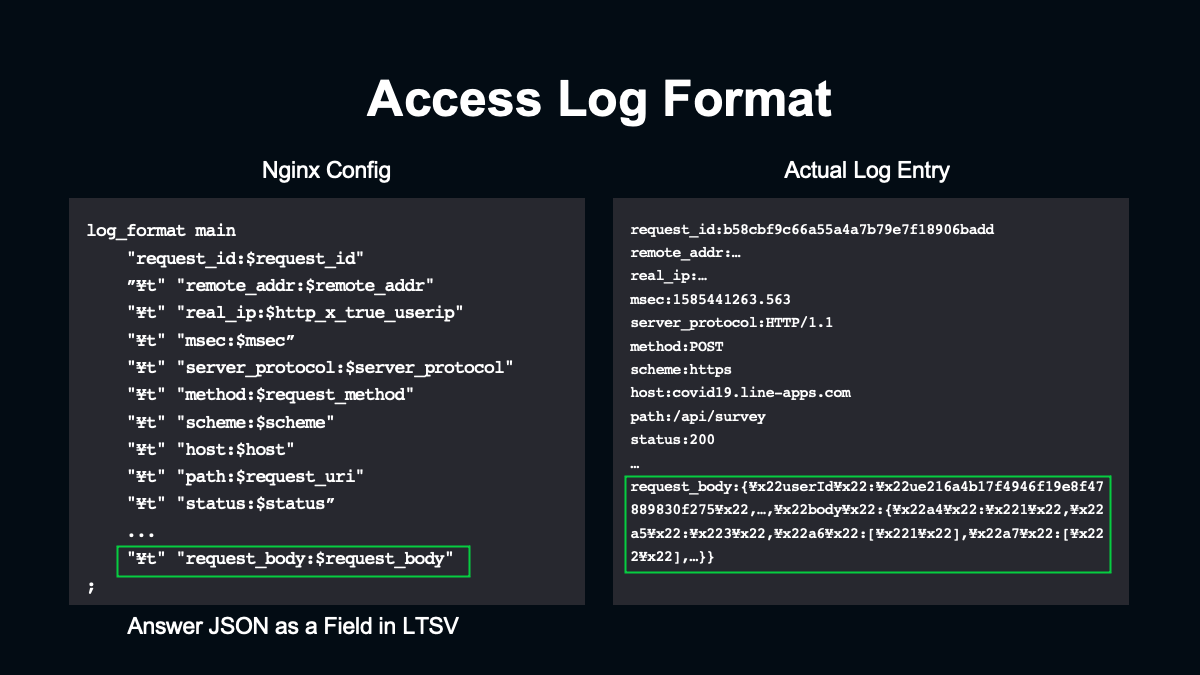
nginxのアクセスログは後の集計で扱いやすくするために、LTSV形式で出力しました。この中でもポイントになるのがrequest_bodyを保存している部分です。クライアントからのリクエストではPOSTリクエストのボディにJSON形式で回答データを詰め込んでいます。これをLTSVのフィールドの1つとしてそのまま保存しています。
実際のログを見てみると一部の記号がエスケープされていますが、JSONがそのまま保存されていることが確認できます。このようにすることで設問の内容が変わったとしてもnginxの設定を更新する必要がありません。
設問の内容は開発と並行してギリギリまで検討が続けられていたため、サーバーサイドとしては設問の変更に影響されない設定にしておき、クライアントと分析側のみで対応できるようにしています。ここまででnginxを中心として調査ページの送信と回答データの保存を行う仕組みを実現することができました。
ログ収集はfluentd、ログ集約はMySQL
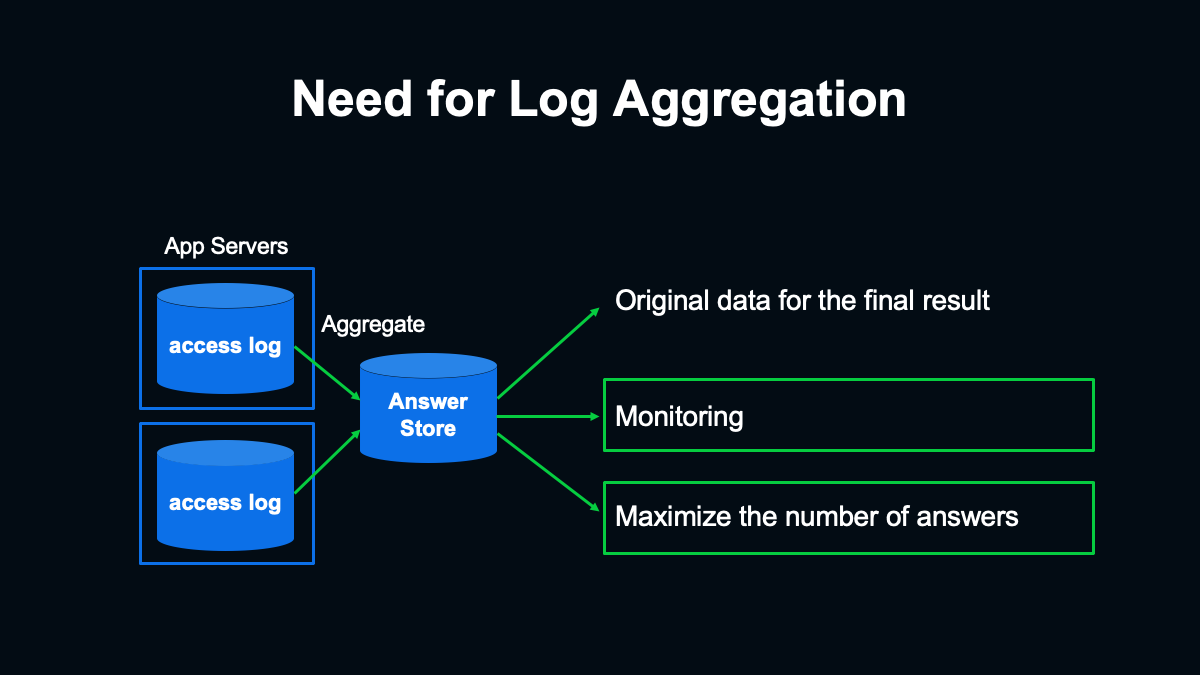
次に回答ログの集約部分を実装しました。第一段階では、回答データであるアクセスログはアプリケーションサーバーの各ホストのディスク内に書き込まれています。
最終的に調査結果としてまとめるためには、一度何らかの方法で各ホストのログを1ヶ所に集約する必要があります。ログの集約は調査期間のあとで行うこともできるため、第一段階で構築したシステムだけで調査を行うことも検討していました。
しかし仕様を検討していく中で、調査の進行中にリアルタイムに近いかたちで回答ログを集約すべきだと判断し、実装することにしました。
その目的は大きく2つあります。1つ目がモニタリングです。ログの蓄積状況を随時確認できるようにすることでシステムトラブルを検知できるようになり、より安定した調査の実施につながります。
2つ目は回答数を最大化する施策への活用です。ログを分析したり回答がまだのユーザーにだけ別の経路で回答をお願いするといった施策を実現できるようになります。
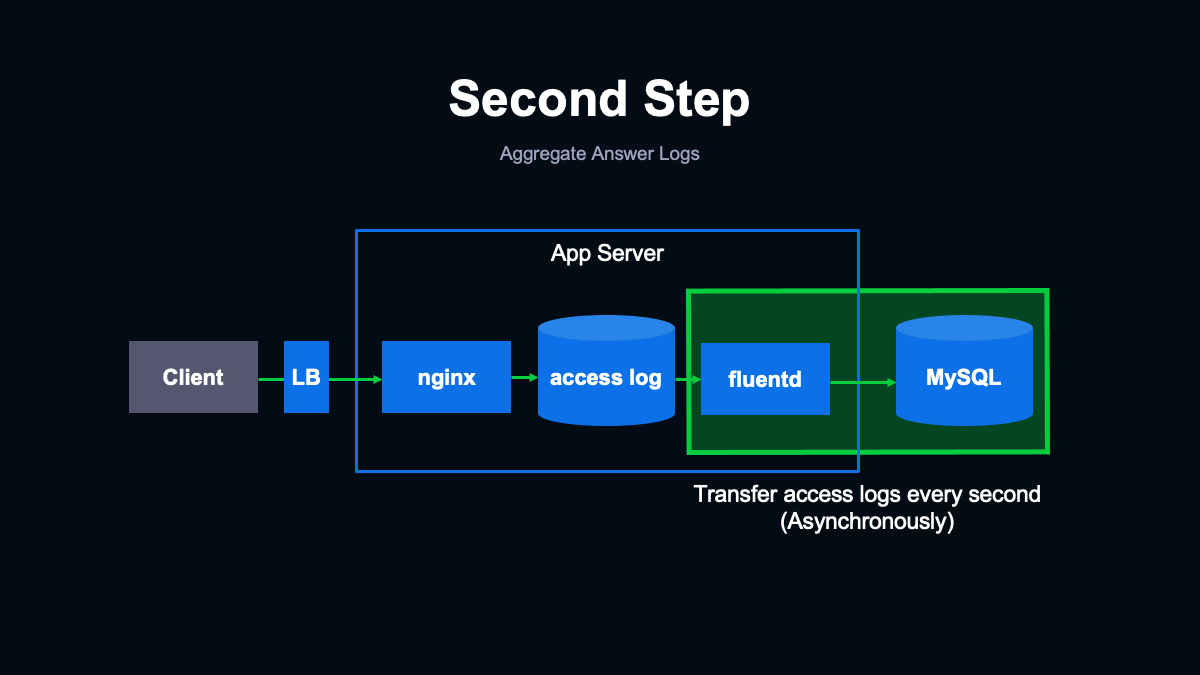
リアルタイムなログ収集を実現するために我々はfluentdを利用しました。また、ログの集約先はMySQLとしました。これはMySQLであればSQLを書くだけで簡単な集計が可能で、モニタリングに役立つと考えたためです。
アプリケーションサーバーの各ホストに導入されたfluentdはアクセスログの更新を監視しており、追記されたログを1秒に1回、MySQLのテーブルにインサートします。fluentdを利用してアクセスログを呼び出すことで、ログの集約処理をユーザーからのリクエストに対する処理とは非同期に行うことができます。非同期にすることでログの集約部分で問題があった際にユーザーが調査に回答できなくなるリスクを低減しています。
fluentdの設定では(スライドを指して)こちらのようなパイプラインを構築しています。まずtailプラグインでアクセスログを読み込み、各行のLTSVをパースします。次にrecord_transformerというFilterプラグインで、リクエストボディの一部の記号がエスケープされているのを元に戻します。さらにparserというフィルターでリクエストボディのJSONをパースします。
最後にfluent-plugin-mysqlというプラグインでLTSVとJSONの中から必要なフィールドをインサートします。リクエストボディにはユーザーIDなどの回答以外のデータも含まれており、ここでJSONをパースしているのはそのような回答以外のデータを取り出して専用のカラムに格納するのが目的です。
回答データとしては、引き続きシリアライズされたJSONをそのままインサートしています。これによりfluentdからMySQLにインサートする部分についてもアクセスログを保存する部分と同様に設問内容の変更に強くなっています。

ほぼリアルタイムで検証する方針に決定
第3のステップとしてログを検証してフィルターする処理を実装しました。先ほどまででアクセスログを集めることができましたが、この段階では受け取ったリクエストをまったく検証せずに保存・集約しているだけの状態です。最終的な調査結果としては各ログのリクエストが正規のものであるかを確認し、不正なリクエストについてはフィルターする必要があります。
加えて、本調査ではユーザーは調査に何回でも回答でき、回答を複数回した場合には最後の回答を有効なものとして扱う仕様にしていました。
これは回答を受け取る際にnginxでアクセスログとして回答を保存する仕様上、保存する前にそのユーザーが回答済みかどうかチェックすることができないためです。そのため保存された回答データに対して後からチェックすることで同じユーザーからの重複した回答をフィルターする必要がありました。
ログの検証についてはリアルタイムに近いかたちで実現することは必須ではありませんでした。しかしモニタリングを正確にできるメリットがあったことと、実装がそれほど難しくなかったことからリアルタイムに近いかたちで検証する方針に決めました。

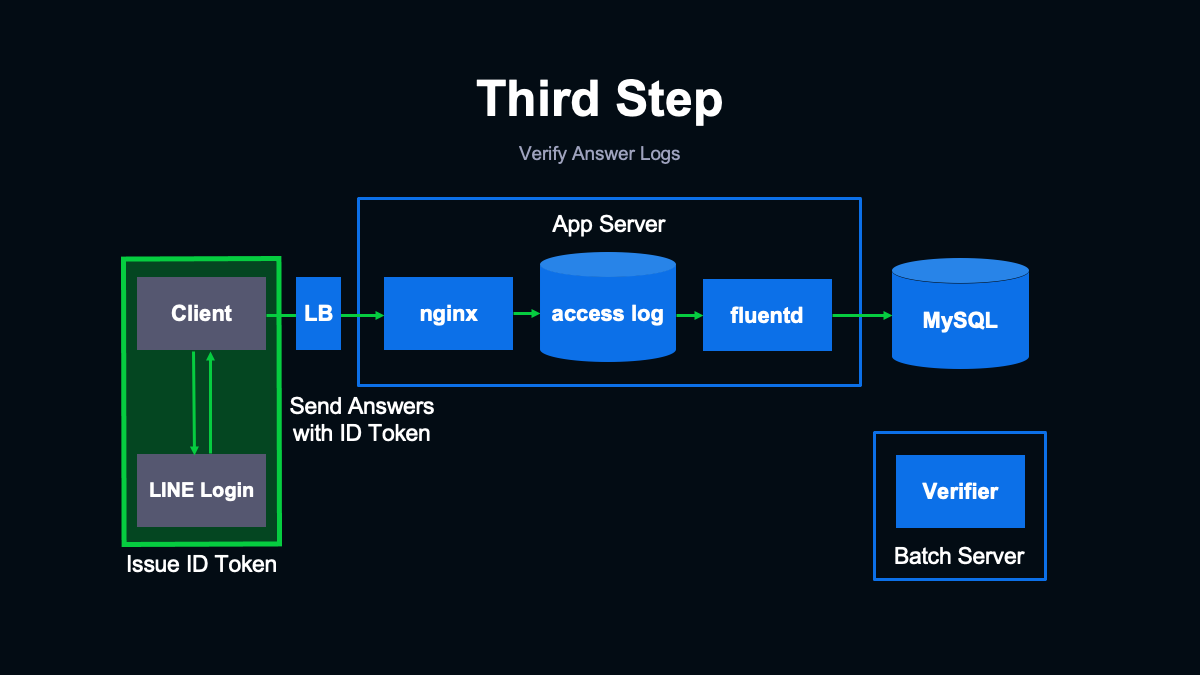
IDトークンを駆使したシステム構成
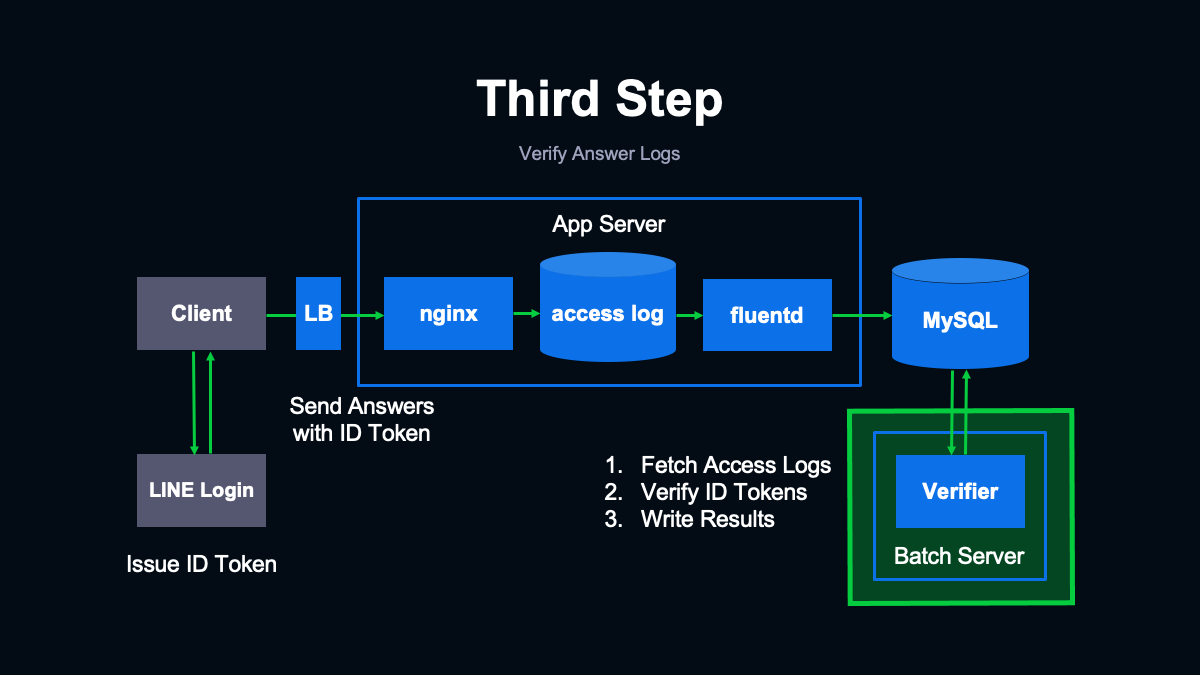
(スライドを指して)こちらが第3段階の機能を組み込んだシステムの構成です。まず回答を行ったユーザーを識別できるようにするため、クライアント側でLINEログインを利用して認証するようにしました。
LIFFを利用したWebアプリケーションは一般的なブラウザでも開くことが可能なのですが、LINEアプリ内で開く場合については、アプリと連携して自動でログインされるため、ユーザーはとくに操作することなくログインした状態で調査に回答できます。
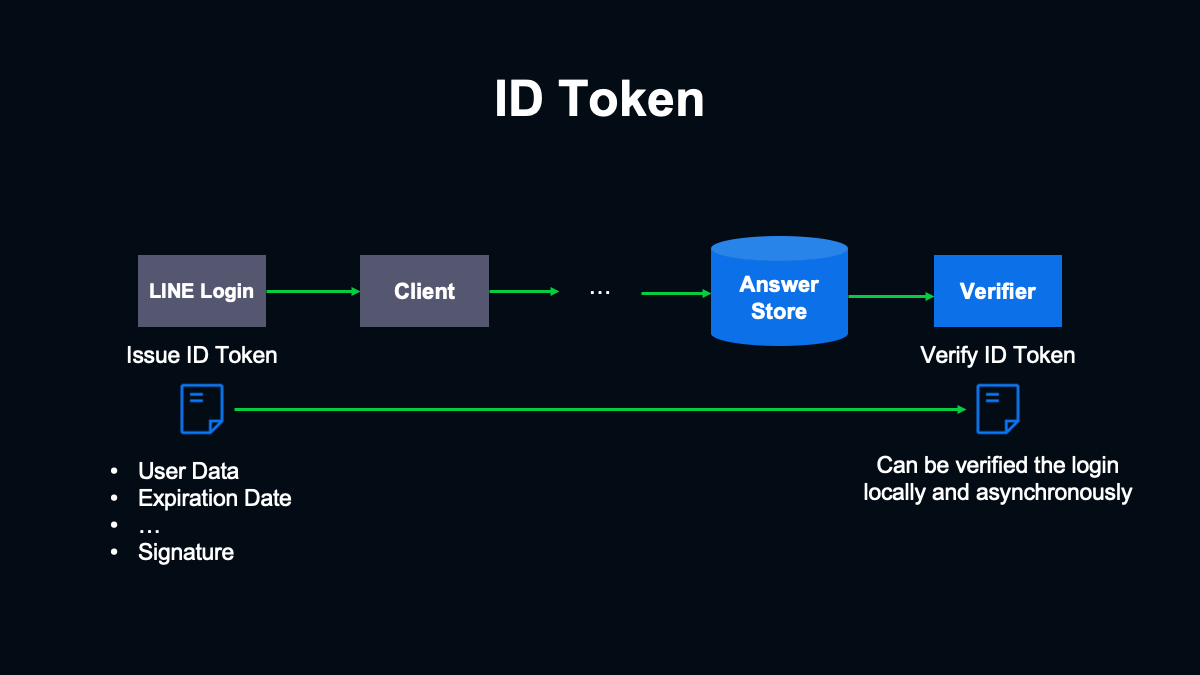
LINEログインのシステムではログイン時にIDトークンというものを発行して返します。これをイベント送信時にリクエストに含めてサーバーに送るようにします。
IDトークンは、ユーザーデータと署名を含んだJSON Webトークンです。発行されたIDトークンは公開鍵を使って内容を検証することで、正規の発行元から発行されたトークンかどうかわかります。
IDトークンは発行されてから一定期間有効なので、少し遅れて検証することも可能です。加えて一度IDトークンの発行元から公開鍵を取得しておけば、署名の確認は手元での計算のみで完結します。こうした特徴により、発行されたIDトークンをデータベースにいったん保存しておき、保存されているIDトークンを非同期に検証する構成を取ることが可能です。
クライアントから送られてきたIDトークンを検証するためにバッチサーバーを用意し、その上で検証を行うアプリケーションを動作させました。このアプリケーションはMySQLに格納されたアクセスログをフェッチし、アクセスログに含まれるIDトークンを検証した上で結果をMySQLの別のテーブルに書き戻します。
書き戻す際にはユーザーがすでに回答済みかどうかをチェックし、すでに回答済みであれば元の回答に上書きするかたちで保存します。ログの検証はCPUに負荷のかかる処理であるため、アプリケーションサーバーで同期的に行うのではなく、別のサーバーで非同期に行うことで、ユーザーからのリクエストに影響が出にくいように配慮しています。
ここまでの3段階で必要な機能の実装は完了しました。