Webアプリケーションの仕組み
清水川貴之氏(以下、清水川):よろしくお願いします。清水川です。「Webアプリケーションの仕組み」ということで、サブタイトル「寄り道しよう、仕組みの理解でさらに加速しよう」というスライドを用意しました。
スライドのURLがボケていて見辛いと思うので、Twitterにツイートしてあります。よろしければそちらを見ながら聞いてもらえればと思います。
自己紹介をさせていただきます。清水川貴之です。所属はBeProudと一般社団法人PyCon JP会計理事というのもやっています。

活動としては、2003年ぐらいからPythonを使い始めて、Sphinxのコミッターと、PyCampというPyCon JPの一般社団法人でやっている、日本全国を回ってPythonを教えるチュートリアルの会の講師をやっています。あとはPython関連書籍の翻訳と執筆です。
みなさん今日登録して、参加していただいていると思いますが、BeProudはconnpassのサービスを運営している会社です。あとはPyQというPythonの入門から仕事ができるようになるまでのサポートをする自学自習のサービスをやっています。
下はPythonのカンファレンスなどのロゴです。今日は子どもを託児所に置いてきたんですが、荷物がすごいことになって大変でした。でも託児所があるのはありがたいですね。
ということで、アジェンダを進めさせていただきます。

最近のWebアプリケーション開発、Webサーバーの動作を観察、Webサーバーを作ってみようということで、やっていきます。この資料は、Scrapboxというサービスを使っていて、みなさんリンクをクリックして開くと分かると思いますが、それぞれキーワードがリンクになっています。
キーワードのリンク先をそれぞれ見ると、モノによっては詳細な説明が書いてあります。
今回、時間が45分なので、30分ぐらいで話を一回切り上げて、そこから先は質問をいただきながら、あるいは説明が足りなかったところを、ほかのページを見ながら紹介していきたいと思っています。
最近のWebアプリ開発
最近のWebアプリ開発には、上から下までけっこう幅広い範囲の知識が必要になってきています。リンク先にWebアプリケーション開発に必要なスキルというのがあって、だーっとすごくたくさん書いてあるんですけれども、Webフレームワークを使えれば、Webの基礎技術、例えば、「TCP/IP」や「HTTP」を知らなくてもWebサービスを作れるよ、という感じになってきてはいます。
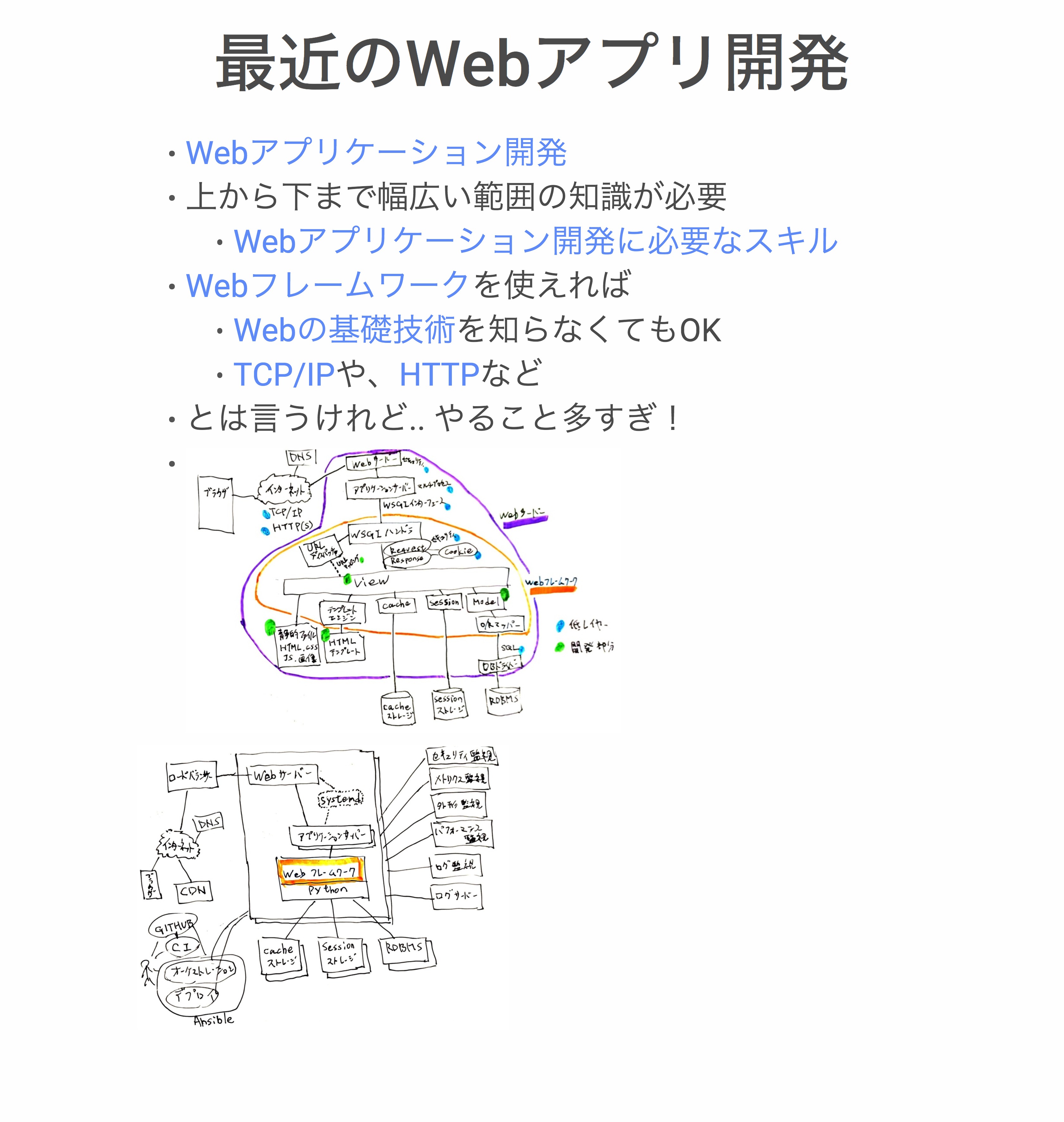
それでもやることがだいぶ多いなということで、絵を描いてみました。ブラウザから「TCP/IP」経由でだーっときて、Webサーバーを経由してアプリケーションサーバーを経由して、WSGIハンドラを通ってViewにたどりついて、ということをやって。その裏にHTMLファイル、テンプレ、cache、session、model、データベースなどがありますね、という絵です。
紫色で枠を囲ってあるのがWebサーバーと呼ばれるものです。オレンジ色で囲っている部分がWebフレームワーク。全部入り系のWebフレームワークの範囲だと思います。青い水色のマルを付けてある部分が低レイヤー。基礎技術と呼ばれているような部分で、グリーンの部分が自分たちでサービスを作ろうと思ったら開発をしなければいけない部分になります。
フレームワークがあるおかげで、やらなきゃいけないところの一部だけを開発すればいいということになっています。
次は、紫で囲ったWebサーバー、Webフレームワークの、もっと外側の絵です。Webサーバーを配置してサービスを運営するにはどうなるか、という絵です。実際にはブラウザからインターネット経由でリクエストがくるときに、DNSを引いたりCDNに行ったり、ロードランサー経由でWebサーバーにきたり。
アプリケーションサーバーやWebフレームワークとPythonが協調動作して、裏にはcache、session、RDBがあります。そこにデプロイするぞ、環境を作るぞというのでオーケストレーション、デプロイ、CIでGITHUBで回して開発をしたり、デプロイ周りは手動でやっていると大変なのでAnsibleを使ったり。
それで、サーバーが動きました、リリースしました、ヤッター! で終わりではなくて、今度は日々発生するセキュリティリスクに対応するセキュリティ監視、メトリクス監視、外形監視。
あとサーバーパフォーマンス。すごく遅いページがないか、パフォーマンス監視、ログ監視、ログサーバーなど、いろんな要素があります。
Webフレームワークを使うと、すごく楽になると言いつつ、けっこう幅が広いなということで、こんな状況にWebをやるのはけっこう大変と思われる方もいるんじゃないかなと思っています。
Webフレームワークの機能
話が広がりすぎるので、いったんWebフレームワークの機能に絞ります。一般的なWebフレームワークの機能の全体像として、さっきの絵の中にあった、こんなものがありますよ、ということです。
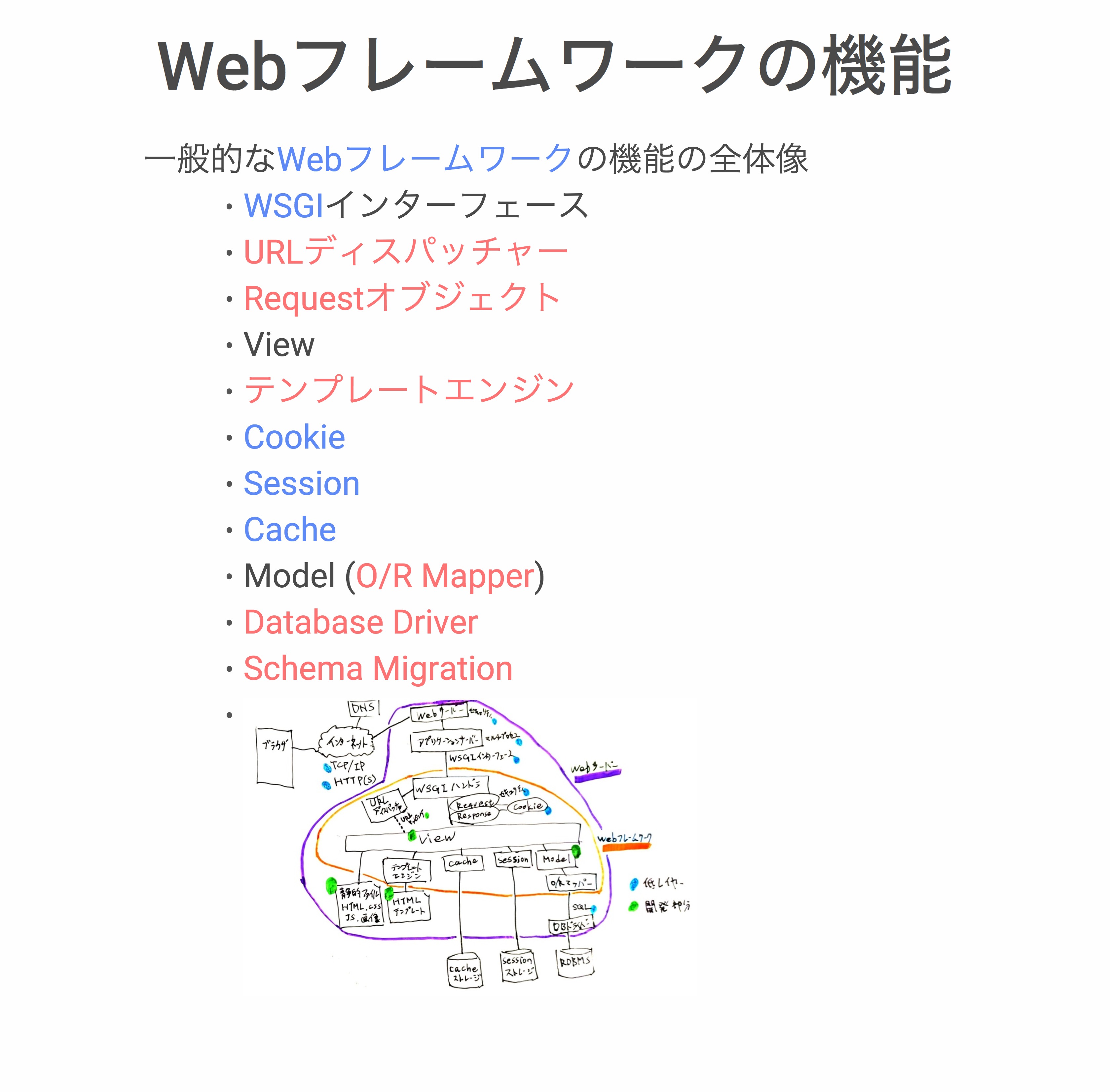
これは最初に紹介した絵です。Webフレームワークはけっこういろんな機能をオレンジ色の内側にもっていますという話になります。
ここでちょっと質問させていただきたいんですけれども、Pythonの Webフレームワークを使っている方で、みなさんは何を使ってるんだろうというのが気になっていまして……。
Djangoを使ってる方は、どのぐらいいらっしゃいますか? けっこういらっしゃいますね。ありがとうございます。
あとはFlaskを使っていますという方は? 意外とFlaskが少ない。Djangoが50人でFlaskが40人ぐらいですね。ありがとうございます。
それ以外の何かを使っているよという方は……? チラホラ。1番前の方、すみません、何を使われていますか?
Bottle。もう1個うしろの方もBottle。Bottleがけっこう多いですね。Bottle以外を使っているという方は……?
Tornado。なるほど非同期系ですね。わかりました。ありがとうございました。Djangoが50人でFlaskが40人でその他が5人ぐらいと。

もう1個、質問です。Webフレームワークを使っていますと手を挙げていただいた方は、機能についてどのぐらい把握されているものなんでしょう。だいたい把握していますという方……。
勇気のある方が1人、手を挙げてくださいました。ありがとうございます。少し把握しています(という方)……あんなに手が挙がっていたのに、けっこう少なくなりましたね。20人弱ぐらいですかね。ありがとうございます。
全然わからない、雰囲気で使っている……なんでこんなに手が挙がるんですか。大丈夫ですか(笑)。ありがとうございます。今、50人以上いましたね。1人、5人、50人以上ということですね。

さっき、絵を描いて紹介しましたが、もう1回同じ絵でDjangoはこういうのを持っているよね、というところを紹介したいと思います。
DjangoやFlaskの機能範囲
簡単な比較です。さっきの絵に対して、Adminという部分が追加されまして、Django Adminはマスターメンテナンスに使うデータベースの管理用のWeb画面です。
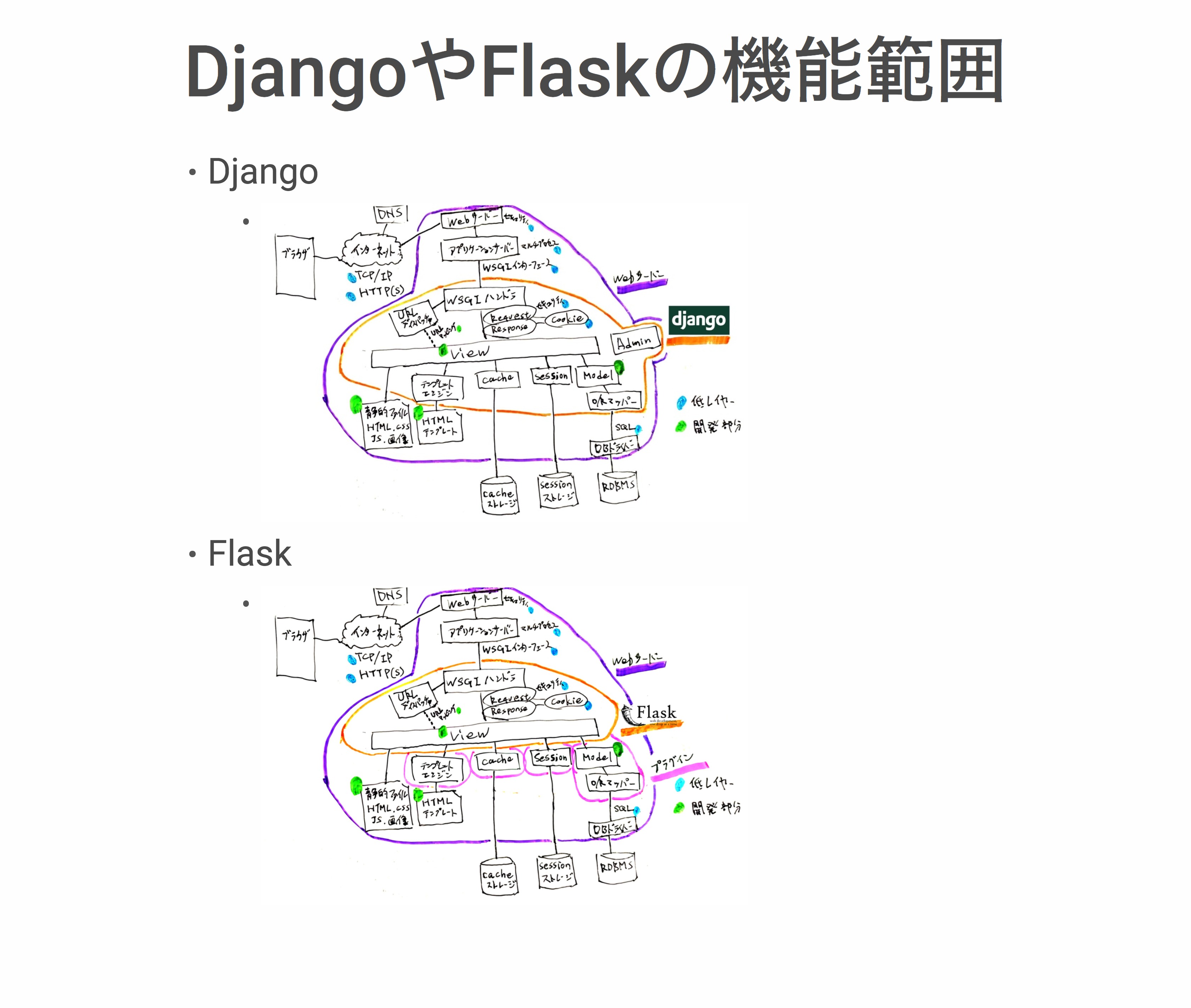
Djangoが持っているたくさん機能の中で、とくに「Djangoイイよね」と言われるときに、この話題が上がることが多いです。
Djangoだとテンプレートエンジン、cache、session、model、O/Rマッパーは持っているんですが、Flaskだとテンプレートエンジン、cache、session、O/Rマッパーはプラグインになります。
Flask自体はもうちょっと小さい範囲を持っています。Django Admin的なプラグインがあるかどうかは、私は把握していませんが、こんな感じです。
とはいえ、代表的な機能の差だけでは測れないだろうということで、ドキュメントをPDFファイルに変換して、ページ数を測ってみました。

Flaskは346ページでDjangoは1,888ページでした。ということで、DjangoはFlaskの5倍ぐらい機能が多いのかというと、多分そんなことはないんですけれども、この膨大なドキュメントを読んで把握することは難しいので、全部読んだ人はたぶん作者……(ほかに)いるのかな、という感じです。
把握は難しいと言っても、ドキュメントの量イコール難易度ではないとは思っていて、チュートリアルが充実していたり、そういうこともあると思います。
ただ、ドキュメントが多いので機能がすごく多くて、全体像が把握しきれないので、Djangoを使い始められないんですよ、なので……。というような話もたまに聞いたりします。
把握できないと比較もできません。
「Djangoって便利だよ」と言うけれど、機能が多くて覚えるので手一杯みたいな感じがあるのかな、ということを考えたのが、今回のこの発表をやるきっかけでした。
これだけの機能を持つWebフレームワークはなんで生まれたんだろうというところを考えてみたいと思います。
Webフレームワーク登場以前の世界
というわけで、機能を把握するために何をすればいいのかなというところで、ゼロから自作して開発を追体験しようということを、今回やってみたいと思います。
Webフレームワークを使わずにWebアプリケーションを作ってみる。なにも無かった時代に倣えばいいのかなというところで、昔はフレームワークはなかったわけですが、そういう時代はどうやって作っていたのかということを考えました。
フレームワークのない時代はいつだかと言うと、2000年頃かなという感じです。2000年頃はどういう時代かと言うと、Web黎明期のシンプルな世界というスライドに、ちょっとまとめてみました。

2000年頃、Web黎明期にはいろいろなかったんです。AmazonのAWSが登場したのは2006年です。Djangoの登場は2005年ぐらい。さくらインターネットのレンタルサーバーが開始したのは2004年。
インターネットプロバイダが提供するCGIサーバーや自宅サーバーで、サーバーを立てるというのが一般的でした。
HTMLは4.01というバージョンが最新で、CSS 1.0が使えるブラウザがやっと登場しはじめたかなという頃です。
あと、JavaScriptは画面上に猫がいて、マウスカーソルを追いかける目的のために使われる言語でした。というのが2000年頃という感じですか。
「Webサイトの要件(現在)」です。現在は動的ページ、Webフレームワークの利用が前提。ないとやってられないということで、そうなっていると思います。

同時アクセスについては、HTML、CSS、画像と1ページ表示するのにも、多くのファイルをリクエストするので、サーバーは多数のリクエストをさばく必要があります。
性能については、単純にサイト、URLにアクセスした人から送られてきたデータを処理すればいいかと言うと、そんな時代ではなくなってしまっていて、セキュリティーチェックや、ページを組み立てる、組み合わせて表示するなど、やることがすごく多いのが現状です。
なので、性能はいくらあってもいいだろうと言いたくなります。
可用性、サイトが落ちているとTwitterで話題になります。クジラが……というような話が出たりします。
黎明期のWebサイトの要件
黎明期は、動的ページについては、URLが実行プログラムと1対1になっていたし、CGIというものを使っていた時代がけっこう長かったかなと思います。 同時アクセス数については、同時1接続でもなんとかなるんじゃないかと。性能が遅くなるほど複雑なことをそもそもサーバーでやっていないよね、ということです。 あとは可用性。たまにサイトが落ちていても、「今日つながらないね、また明日つなごう」というような。
個人サイトだったら「あぁ1週間くらい落ちてるね」という感じのことがぜんぜんあったりもしました。
ということで、実際にこの「Webサイトの要件(黎明期)」の要件を使って、ブラウザの動作を確認したり、Webサーバーの動作を確認したりということを、これからやっていきたいと思います。
まずはブラウザの動作を確認ですね。ブラウザからWebサーバーにアクセスして、サイトを表示するまで、何が起きているだろう? 最近SNSでこういう質問が話題になっているそうですが、それとはぜんぜん関係なく進めていきます。

内部ではいろんな通信が発生しています。ブラウザでサーバーにHTTPリクエストを送信するとHTTPレスポンスが返ってくる。ということで、ブラウザのデバッガーでちょっと確認してみたいと思います。
Webサーバーの動作観察
example.comにアクセスをすると、(ブラウザを指して)こんなページが表示されるわけです。example.comというのは、みんなが使って大丈夫な、誰のものでもない生きているサイト、ということになっています。「詳しくはこちら」と書いていますが、ちょっと割愛します。
最近のブラウザだったらF12キーでデバッガーが起動します。Chromeなので、ネットワークタブをクリックしてリロードすると、example.comに200レスポンス、OK、というのが返ってきて、クリックすると、Webサーバーに対して、リクエストヘッダーがこういうもので……つまり「このブラウザは何者ですよ」「こういうホストに接続したいと思っているんですが」「言語はこうですよ」というような情報を送っています。
それに対してレスポンスヘッダーというものがこんな感じに書いてあって、コンテンツのタイプはtext/htmlで、エンコードはutf-8で、ファイルサイズは606バイトで、というような情報が返ってきています。
そして、Responseを見ると、HTMLで、こんなデータが返ってきていますと。サイトにアクセスすると、デバッガーでこのような動きをいろいろと見ることができます。
Webサーバーの動作観察ということで、telnetを使ってやってみたいと思います。telnetとは、任意のTCP/IPポートに接続をして、テキスト通信を相互にやりとりするプロトコル、コマンドです。
サーバーにアクセスしてHTTPリクエストを送信すると、HTTPレスポンスが返ってくるということで、実際にやってみます。

「$ telnet example.com」、80番ポートに接続をして、GETメソッドで、スラッシュで、「ルートのhtmlファイルを取りたいです」、「HTTPプロトコルは1.1でお願いします」、「ホストとして接続しようとしてるのはexample.comです」、ということでenterを2回押すと、だーっとテキストが返ってきました。
向こうからのレスポンスは、「HTTP/1.1 200 OK」で、内容がこうで、という感じで。HTMLのファイルも全部取れてきていますね。
こんな感じで、telnetコマンドを使って簡単にサーバーに接続をして、確認ができます。この内容を、スライドの続きに書いてあるので、よろしければ見てください。
Pythonでexample.comへアクセスする
では、telnetはこのくらいにします。みなさんはPythonに興味があって今日来ていると思うので、Pythonからやってみます。
Pythonには「urllib.request.urlopen」というライブラリがありますので、これを使ってexample.comにアクセスしたいと思います。

Pythonを起動して、「import urllib.request」。で、「urllib.request.urlopen(‘http://example.com’)」。これを変数「uo」に入れておいて(urlopenの略)、uoのstatusを見ると、200が返ってきていますね。
こんな感じで、urlopenを使ってサイトにアクセスをして、statusを見て、ヘッダーデータを取得できました。これなら、プログラムとして処理しやすい感じですね。
HTTPステータスが200というのは、「OK」の意味です。Content-Typeというのは、ファイルが何の種類なのか。text/htmlならhtmlだし、image/jpegならjpegです、という情報です。そういうのがヘッダーに入っています。
もう1つ、動作確認。本文はどうなったんだということで、レスポンスボディを確認してみたいと思います。

「print(uo.read()...」でファイルから読む感じにして、decodeですね。バイト列を、decodeでutf-8に変換してprintします。すると、こんな感じで本文もちゃんと届いていることがわかりました。
これ、だいぶ原始的なHTTP通信のサンプルという感じですね。urllib.request.urlopenを使ってスクレイピングする人は今少ないと思いますけれども、Webスクレイピングしてデータ収集しよう、データ収集してデータ分析しよう、という人にとっては……スクレイピングという分野で、サーバーのHTMLを取ってきて、なんてことをやるときには、こういったライブラリのお世話になります。