本セッションの流れ
ダンヒョンジュン氏(以下、ダン):それでは、私のから発表させていただきます。「dieselを活用してSQLを作成しよう」という話題として、ORMの1つである「Diesel」を紹介したいと思っています。
では、パイオニア株式会社のダンヒョンジュンから発表します。簡単な流れです。自己紹介はもう終わっているので飛ばしますね。次はDieselとは何かということと、Dieselで開発して良かったこと、辛かったこと。あとはDieselの実装の簡単な例。あとは最後の一言という流れになります。

言っておきたいことです。私は2023年4月から初めてRustを使ってDieselを経験してきたので、短い経験ですが、「私でもこういうのを感じた」ということを伝えられたらと思います。

RustのORMライブラリの1つ「Diesel」
まず「Dieselとは何か?」というと、RustのORMライブラリの1つです。「ORMとは何か?」というと、Object-Relational Mapping、つまりRustでSQLを扱うためのツールの1つです。
RustにはいろいろなORMのライブラリが存在しますが、その中でDieselは一番の割合を示しているものです。それによって得られる良いこととしては、ドキュメントが世の中にいっぱい存在する、参考になるものがものすごく多いことが1つの良いところではないかなと、信頼性がある程度あるのではないかなということですね。

Dieselの特徴
実際に私がDieselを触ってみてちょっと感じたこととか、辛かったことの紹介をします。
まず特徴としては、型安全性を持っていて、クエリをコンパイルする際に検査を行ってくれます。同じ型安全性という特徴があるRustと相性が良いのではないかなと思っていました。
あとはマクロの機能があります。(スライドを示して)これもそうなんですが、コンパイル時に自動でマイグレーションを行って、クエリを作成してくれるんですよね。それによって手間がかからないというのがありました。
あとは、トランザクションと複数のクエリを一連の操作としてグループ化してくれたり、マイグレーションで、データベーススキーマを変更するための安全で簡単な方法を提供してくれたりすることもあります。
(スライドを示して)こちらの表ですが、ORM(について)で、最近だと2つの中で選ぶのではないかな。Dieselと「SeaORM」という、もう1つのORMのライブラリがあります。それぞれの特徴があって、(SeaORMには)Dieselでは対応していないデータベースエンジンもあったりします。
私としてはDieselがおすすめなんですが、これに何て書いてあるかというと、初心者としてはけっこうチャレンジ的なライブラリであるということで、初心者の方は勉強しなければいけないこともけっこうあったりするのもあり、コミュニティのサポートが確立しています。機能とパフォーマンス面ではけっこうこなれているライブラリかなと思っています。

Dieselを使ってみて良かった点
実際にDieselを使ってみて良かった点をいくつか紹介したいと思います。
先ほども言ったとおり、参考にする資料がとても多いです。私みたいな初心者は、なんかうまくいかなかった時とか、最初に導入する時には、ネットとかで情報を調べたり、ドキュメントを参考にすることが多いんですが、Dieselは多くの方が利用されているライブラリなので、参考にする資料がとても多いのは良いところ、長所になるのではないかと思っております。
あとはマイグレーションを行う時に、外部制約のスキーマを自動で生成してくれるので、作成する手間がありません。それによってJOINとかもとても簡単にできています。
(スライドを示して)具体例のコードですが、INNER JOINを行う時にはONとかの指定が必要ですが、Dieselでは要らないと思います。
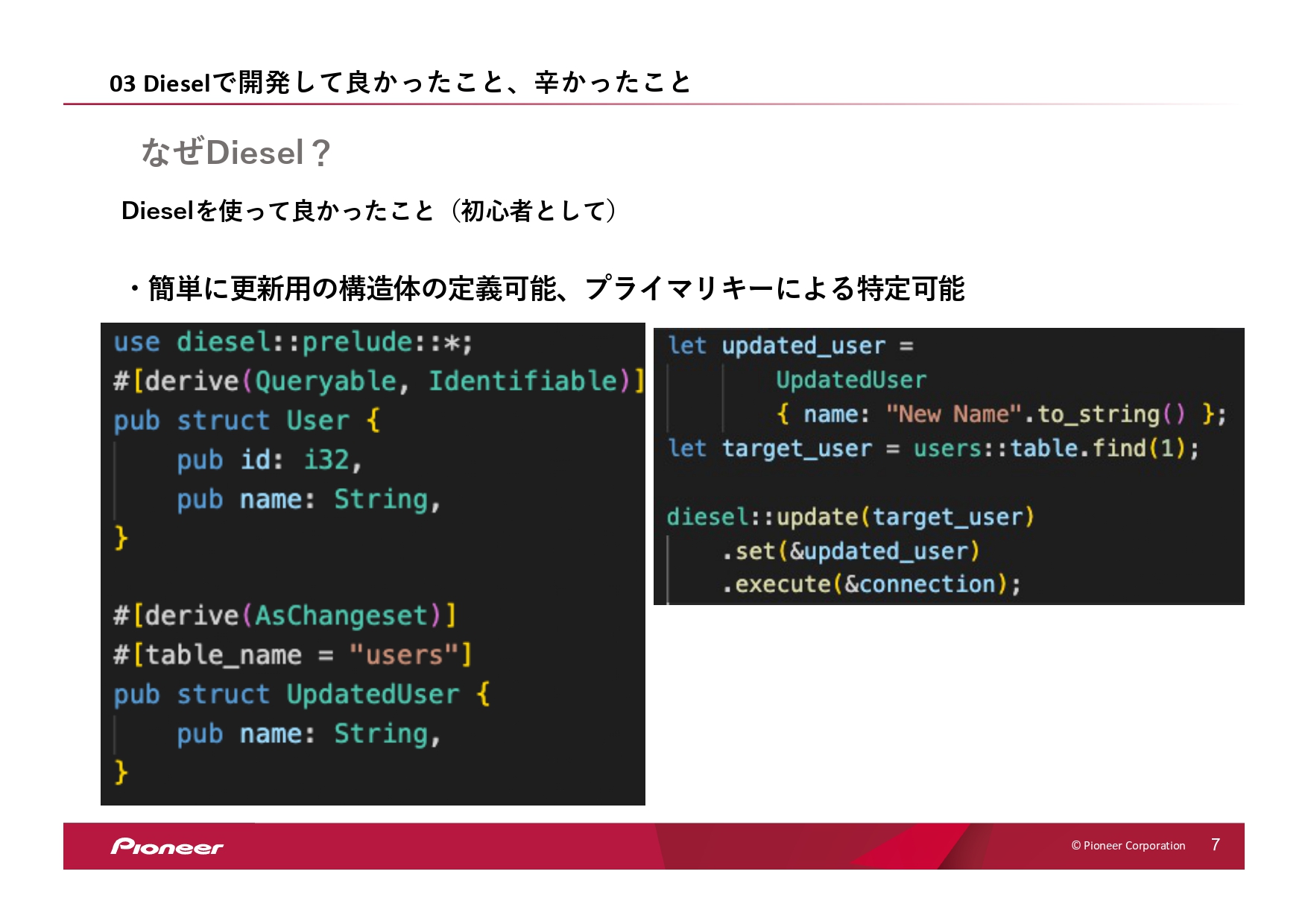
あとは、簡単に更新用の構造体の定義ができて……。まぁ更新用だけではないんですが、いろいろな構造体の定義ができて、プライマリキーによる特定も可能です。
(スライドを示して)例えばこちらのコードですが、「Queryable」は「クエリができるよ」という意味で、「Identifiable」は、「プライマリキーによる特定が可能だよ」という定義を指定します。そうすると、プライマリキーによって、テーブルの中で特定ができるようになります。
あとは「AsChangeset」という定義が指定されているんですが、こちらは「更新用の構造体ですよ」という意味ですね。これによってこの構造体は更新用で使われていることがわかって、実際に使う時にも「update」、更新用でこの構造体を利用して使うことができます。
Dieselを使ってみて感じた弱点
一方、やはり弱点もあります。実際に触ってみて、Dieselは強力な拡張可能なツールですが、初めて使うにはやはり勉強することもたくさん存在するかもしれないということを実感しました。
あとは、自動で生成されたり、必要になるコードの量がけっこう多いので、実際に書いてみると実感できると思いますが、膨大なプロジェクトでは可読性がちょっと落ちるかもしれないです。
あとは、プロシージャおよびトリガーサポート、またはデータベースのエンジンのサポートには、一部限界が存在しているということです。こういう弱点も存在しています。

Dieselを活用した実装例
次は簡単な実装の例です。準備などはDieselの公式のドキュメントに細かく書いてあるので、そちらを参考にしてもらえればと思います。

(スライドを示して)こちらもDBの接続をする時のコードの例になります。

こちらがモデルの定義の例です。一応、スキーマのファイルの中では、マイグレーションを行う時、コンパイルの際に自動でスキーマが生成されます。なので、こちらに関しては実際に(自分の手で)書くことはほとんどなく、簡単にできるかなと思っています。
こちらを参考にして実際のモデルのコードを作成します。その際に、「Queryable」「Selectable」「Insertable」「AsChangeset」みたいに、何に使う構造体であるのかを定義します。

その次は、実際の簡単な例です。(スライドを示して)SELECT文だと、例えばこのようなSQL文があるとしたら、先ほど言ったとおり、「Selectable」と定義した構造体を使ってフィルターを絞って、「load」というメソッドを使って、SELECTを行います。

INSERTも同じく構造体を定義する際に、「Insertable」という名前で定義を行います。そうすると、「こちらはINSERTに使う構造体ですよ」という意味になり、Dieselの「insert_into」というメソッドを使ってINSERTできるようになります。

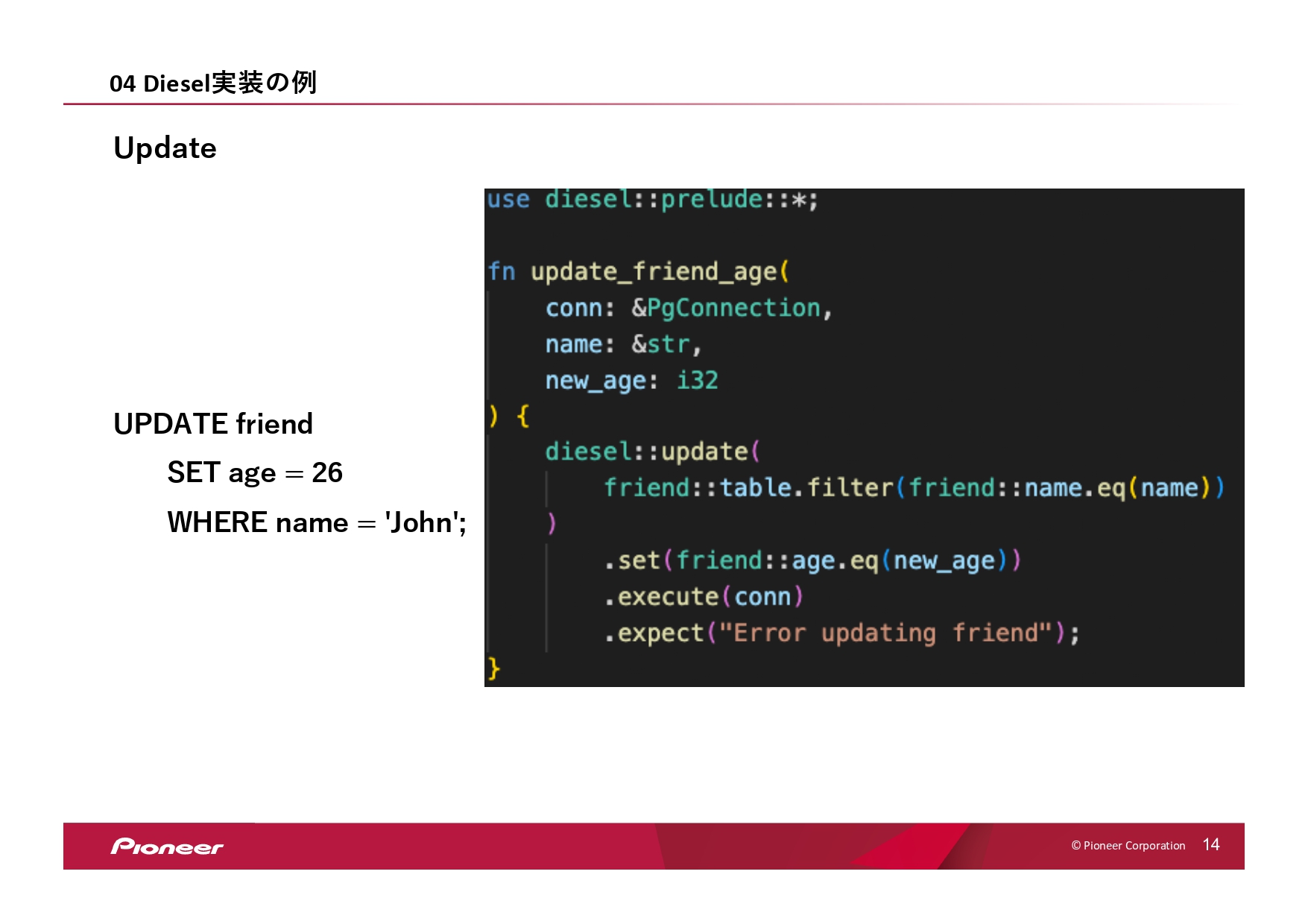
次はUPDATE、更新です。更新も同じく構造体の定義が必要で、その時は先ほどの「AsChangeset」という名前で構造体を定義します。その後、対象をフィルタリング関数を使って絞って、「set」で更新の値を入れて更新するかたちになります。
DELETEに関しましては「delete」のメソッドを使って、対象を絞って、フィルタリング関数を使ってDELETEを行います。

フィルタリングの関数に関しても、とてもいろいろなケースに応じて全部用意されているので、とても使いやすかったなと思っています。

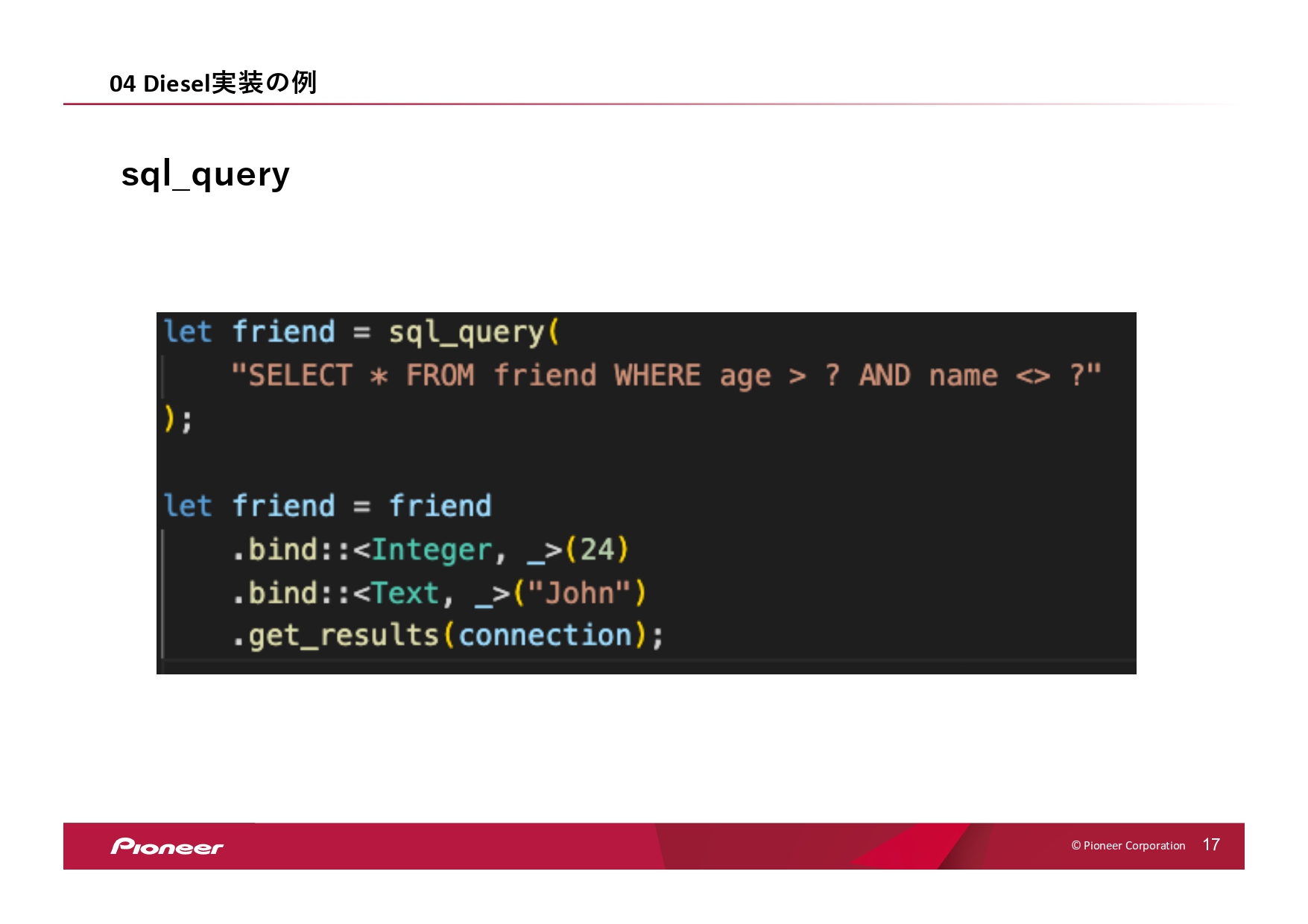
そのほか、項目の数がものすごく多くなったり、SQL文がすごく複雑になったり、型がうまくサポートされていないものも存在したんですが、その際にはSQL文を直接叩かないといけなかったので、「sql_query」を使って実装を行っていました。
(スライドを示して)「sql_query」の使い方はこちらになります。このようにSQL文を直接書いて、「?」のところにバインドを行います。型、値のかたちでバインドを行って、実装を行います。
適切なORMツールを選択することが大事
最後の一言です。やはり開発者としては、Dieselが良いというよりは、プロジェクトの要件とチームの技術的な好みに基づいて適切なORMツールを選択する必要があって、それが一番大事かなと思っています。
その中で、今回紹介したDieselが1つの例になって、参考になればいいかなと思っています。

以上です。ご清聴ありがとうございました。