学生コンテスト世界大会出場の経歴
佐藤邦彦氏(以下、佐藤):よろしくお願いします。「Microsoft Imagine Cupと深層学習を用いた音源分離技術について」と題して、佐藤邦彦が発表します。このイベントに今日初めて来て……。メールで「Imagine Cupと深層学習のことを話してくれ」と言われたので、それについて話そうと思います。
まずImagine Cupについて。せっかくMicrosoftで開催してるので、ちゃんとImagine Cupの宣伝をしようと思います。
まず、学生向けのITコンテストです。日本大会だけでなく、日本大会で勝ち上がったあとは世界大会で、世界の人たちと戦って優勝が決まるという、学生向けのコンテストにしては大きい大会ですね。
とくにテクノロジーにフォーカスしていて、今年の優勝賞金は85,000ドルなので、日本円だと900~1,000万くらいだと思います。
ちょうど今週の月曜日、Imagine Cup 2018の日本大会決勝が行われました。そこへ僕も出場してきました。結果はみごと世界大会進出ということで……。

(スライドの)向かって左が僕ですね。今年は3チーム世界大会に出場が決まりました。これに出したプロダクトの話をしようと思います。
自己紹介です。佐藤邦彦です。

実は所属が変わっています(笑)。今、LINE株式会社に就職しました。東京大学にいたのは3月までです。修士課程を卒業。大学は筑波大学の情報学群を卒業しました。
今の所属はLINEですが、今日はLINEの事業と関係なく、僕個人のプロジェクトとしてお話します。
ちょっと短めに自己紹介すると、昔は野球をやっていましたが見てほしいのは(スライドの)右下です。

Imagine Cup 2017世界大会と書いてあるんですけど、これが僕です。実は去年も日本大会で勝ってて、今回2連覇です。自分でもけっこう、まぁすごいかなと思うんですけど……。
(会場笑)
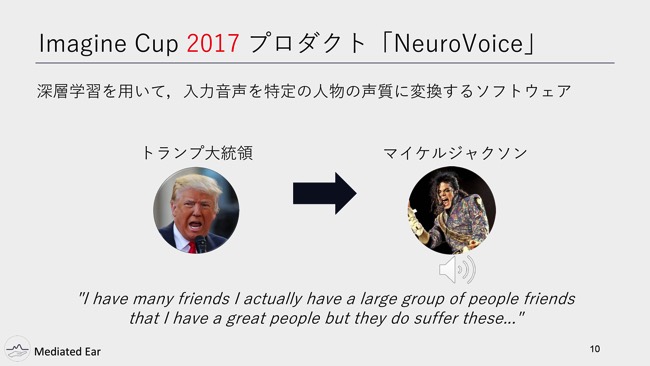
そのとき出したのも音声系なので、紹介しようと思います。音声と深層学習を使ったものです。そのときは、入力音声を特定の人物の声質に変換するソフトウェア「NeuroVoice」を作っていました。
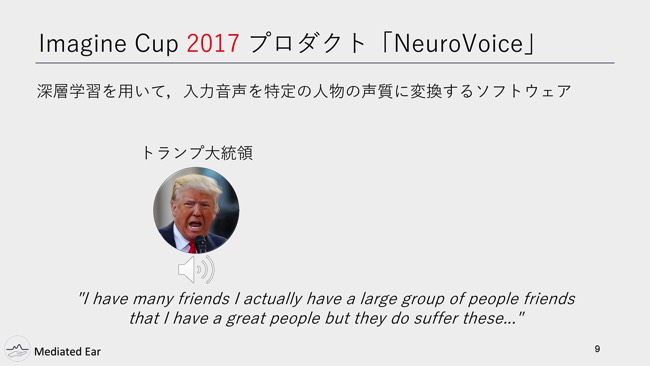
声マネを実現するソフトウェアです。ちょっとデモを聞いてもらいます。入力音声がトランプ大統領です。
(音声が流れる)
佐藤:これをNeuroVoiceを使って、じゃあマイケル・ジャクソンの声にします。
(音声が流れる)
佐藤:……というふうですね。発話タイミングは一緒なので、同時に再生します。
(音声が流れる)
という感じで、入力音声の声質だけを特定の人の声色に変えることができるというプロダクトで、去年は世界大会に行きました。
世界大会の結果は1回戦で負けてしまって。世界から54チームくらい出ていて、最初で半分くらいに絞られますが、そこを勝てなくて負けてしまいました。今年はリベンジということで、日本大会に出て勝って世界大会へ行けることになったので、次は世界で勝てるように、ということです。
声の抽出ソフトウェア「Mediated Ear」
さっそく、今回出すプロダクトの話に入ります。今回は「Mediated Ear」という音声系のプロジェクトです。また音声系です。特定の人物の声を抽出するソフトウェアです。
導入から入りますと、僕には補聴器をつけている友達がいます。大学のときの友達なんですが、補聴器してるぶんには普通に会話できるんですね。でもちょっと問題があって、人混みではぜんぜん会話相手の声が通らないんです。
僕もその友達とレストランやカフェに行くと、僕の声がその友達に届かないことがよくあります。
これって聴覚障害者の音の聞こえ方として、音が小さく聞こえるんじゃなくて、「周りの音すべてが混ざって聞こえる」ということが原因です。

いわゆる健常者の人は、聞きたい音に注目することができるんですが、聴覚障害者で補聴器を利用している方は、周りのすべての音が全部混ざって聞こえてしまいます。

そこでMediated Earです。
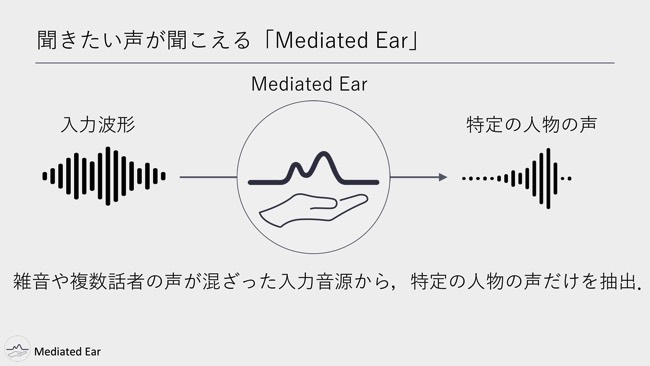
深層学習を利用して、特定の人物の声を抽出するソフトウェアです。Mediated Earは、雑音や複数の話者の声が混ざった入力音源から、特定の人物の声だけを抽出します。
デモです。今、複数話者が重なっている音源から、特定の人の声だけを抽出します。(スライドの)上でまず、抽出対象の人の声を流します。次が入力音声です。最後がMediated Earによって、対象話者の声を抽出した結果です。

(音声が3パターン流れる)
というふうに、入力音声のほうで混ざっていた対象話者じゃない人の声を抑制して、対象話者の声だけを抽出できます。あるいはBGMなどが重なっている音源からも、その人の声だけを抽出できます。
(音声が流れる)
複数話者が重なっていても、BGMや雑音が重なっていても、1つのニューラルネットワークでその人の声を必ず抽出できる、という深層学習の作品です。
現在の補聴器やイヤホンも、雑音抑制や音声強調機能が入っているんですが、複数話者の声を分離することができません。一方、Mediated Earは、抽出対象となる人物の声がMediated Earに入力されると、なるべくそのままその人の声を出力するようにします。
(スライドを見せる)この波形の画像は、実際に出力した波形の画像です。
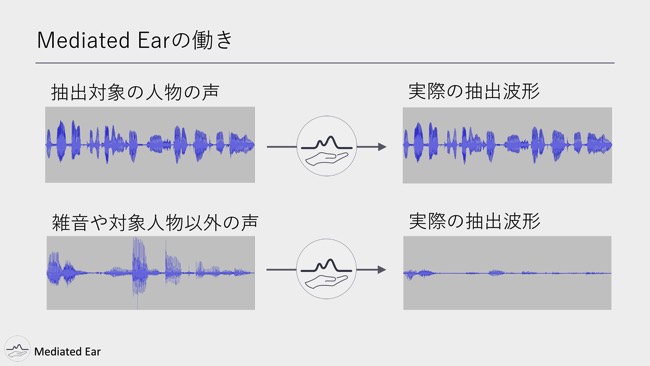
一方で雑音や抽出人物以外の声が入力されると、それらの波形を抑制するようにはたらきます。
Mediated Earと先行事例の比較
音源分離の技術の先行事例としては……。音源分離は大きく2つに分けられていて、1つはシングルマイクの音源、モノラルチャンネルから波形を分離するという手法。もう1つが、マルチマイクを使って、複数のマイクから入力された音源を分離するという方法です。Mediated Earは、シングルマイクでの音源分離に分類されます。
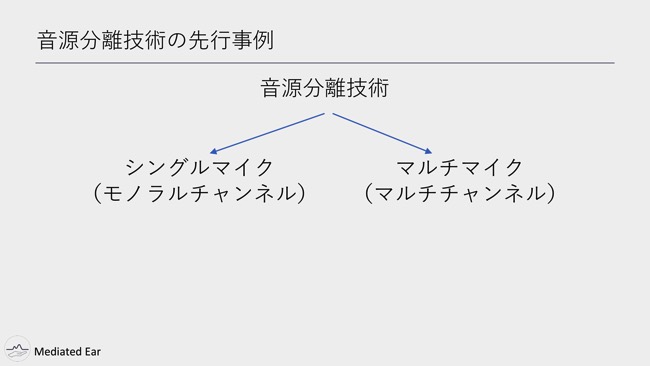
さらにシングルマイクでの音源分離も、大きく分けて雑音除去と話者分離に分かれます。
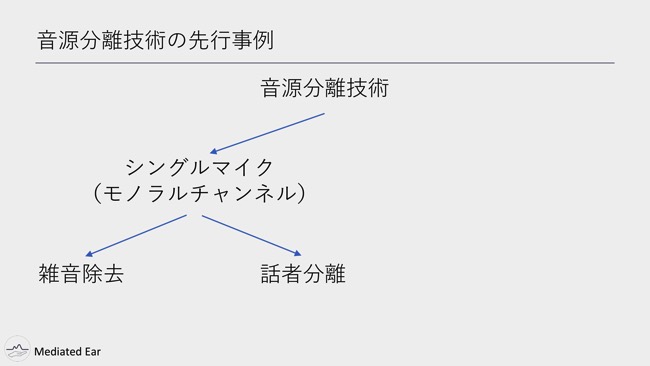
先行研究などでは、基本的に雑音除去や話者分離について音源分離を行った研究が多いです。
雑音除去と話者分離とMediated Earの違いを説明しますと、雑音除去はその名のとおり、雑音と人の声を分離することができます。でも一方で、話者は分離できません。サンプルがあります。“Deep Clustering and Conventional Networks for Music Separation” という論文があり、Web上で音源分離のデモを公開してます。ちょっとこれを使わせてもらいました。
これは雑音というか、音楽と声を分けるという研究です。では実際に、音楽が混ざった入力音声から声だけを抜いてみます。
(音声が流れる)
というふうに、背景で鳴っていた音楽は消せます。しかし……。複数話者を入れた場合のフィルター結果を聞いてもらいます。
(音声が流れる)
音楽と人の声は分けられるんですが、人の声同士は分けられないというのが雑音除去のニューラルネットワークの特徴です。
話者分離についてはもちろんその名のとおり、複数話者の声を分離できます。が、短所としてまず、雑音を消すことができない。あと入力音源に雑音が含まれると、話者分離の精度が落ちるという特徴があります。
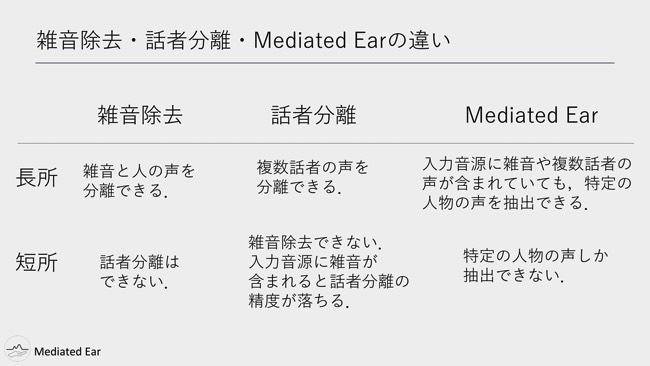
一方、Mediated Earは、入力音源に雑音や複数話者の声が含まれていても、特定の人物の声を抽出できます。短所として基本的には1つのニューラルネットワークで、1人の特定人物の声しか抽出できないというトレードオフがあります。どんな入力音源であっても必ずその人の声を抽出できるというメリットの代わりに、デメリットして1ニューラルネットワークで1人、というようなトレードオフをとっています。
入出力の値とDNN構造
Mediated Earの実装方法です。抽出対象となる人物の声だけを抽出するように、深層学習を行います。
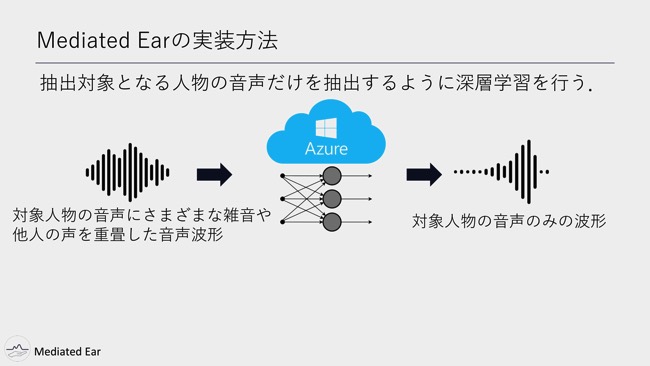
まず訓練データの入力音声が、対象人物の音声にさまざまな雑音や他人の声を重畳した音声波形です。その音声波形から対象人物の音声のみの波形を出力するように、学習を繰り返します。
ここで、比較的新しいことだと思うのは、入出力に波形のサンプリング値をそのまま使えることです。先ほど徳井さんの話でもありましたが、音声の深層学習はスペクトログラムに変換したり、なにかしらの周波数領域に変換したりということをよくするんですけど、Mediated Earはそのままサンプリングした値を入出力します。
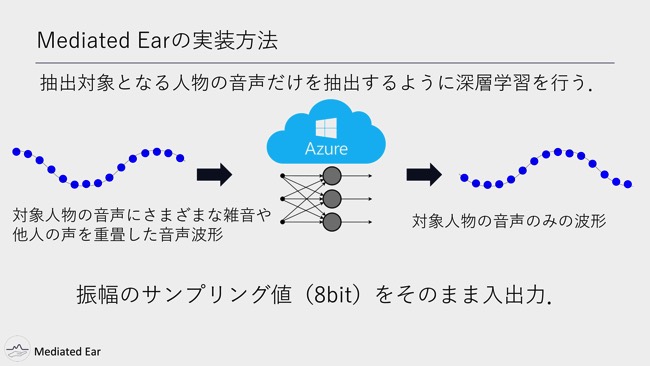
wavファイルで8bitでサンプリングした値をそのまま入れます。そして、そのまま出力されるということです。
メリットとしては、けっこう開発が楽というのがありますね。音声のニューラルネットワークを「初めてやります!」っていうと、いきなりMCEPsとかフーリエ変換とか、ちょっと周波数領域の難しい話が出てきて、それでけっこう警戒されるんですけど(笑)、これはサンプリング値そのまま入れて出すだけなので、開発が楽です。
学習するためのDNN構造について話します。こういう波形とか時系列データっていうのは、RNNとかLSTMがよく使われるかなと思います。ですが最近のトレンドというか、ナウでヤングな感じは、RNN/LSTMを使いません。
これには理由があります。まず先行研究で、これも“Deep Clustering~”の論文から引用してるんですが、LSTMを用いたDNNモデルは訓練データに含まれない話者同士の分離が難しい、という特徴があります。
つまり今想定しているのは、訓練データにも含まれてない、かつ抽出対象の人物じゃない声が入ったときにはそれを抑制したいという状況なので、訓練データに含まれない話者が入力されたときに分離がうまくはたらかないというのは、大きな欠点です。
もう1個。これは2週間前くらいのブログです。

この人は“Drop your RNN and LSTM, they are no good!”って言ってるんです。もうこれくらい、「LSTMとRNNはダメじゃない?」って言ってます。
理由としては、訓練時も学習済みモデルを実行するときも、多くのリソースを必要とする。RNNは中間層が逐次実行で、中間層の計算結果を保持する必要があり、メモリを無駄に食います。あとGPUの並列処理を有効に使えないという問題があります。
DNN構造の比較
これはConvolutional Neural Network(以下、CNN)とLSTMの演算のイメージ図です。
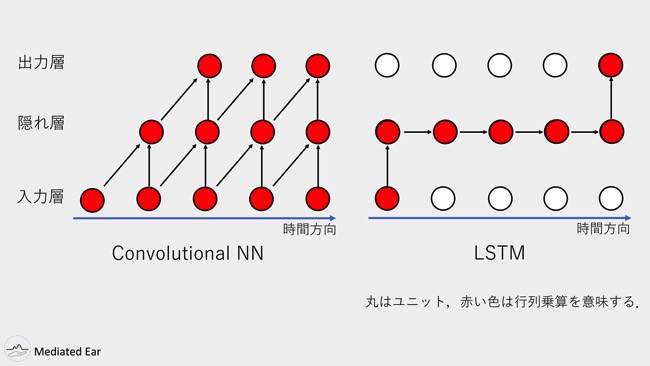
CNNなどは入力があって、そして並列で隠れ層で計算して、そのまま出力層へと計算できるんです。しかしLSTMは入力があって、中間層で各自、値の受け渡しがある。逐次実行しかできないんですね。
なのでまず、学習速度がめちゃくちゃ遅いです。おそらく、CNNとLSTMを動かしたことがある人ならわかると思うんですけど、10~20倍くらいLSTMのほうが時間かかります。
そこでどういったDNN構造を使ってるかというと、Dilated Convolutional Neural Networkです。
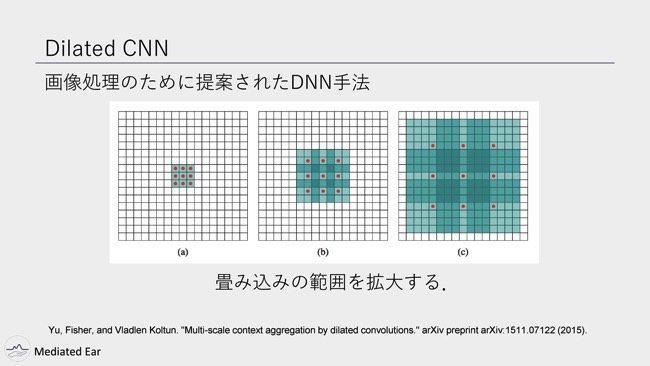
Dilated CNNはもともと画像処理のために提案された手法です。通常のCNN・畳み込みはフィルターのサイズを3×3など一定にしてフィルターかけるんですけど、このDilated CNNは隠れ層が深くなるにつれて、フィルターの幅を広げるという手法です。
最初は画像処理に提案された内容で、これを音声に適用したのが「WaveNet」です。音声界隈だとすごく有名な論文だと思うんですけど、これは「Text to Speech」というタスクに適用された手法です。
Text to Speechは、文章を入力したらその文章をコンピュータが読み上げて、音声で出力してくれるというタスクです。これはwaveformのサンプリングの値なんですけど、それを畳み込む幅をちょっとずつ広げているという特徴があります。
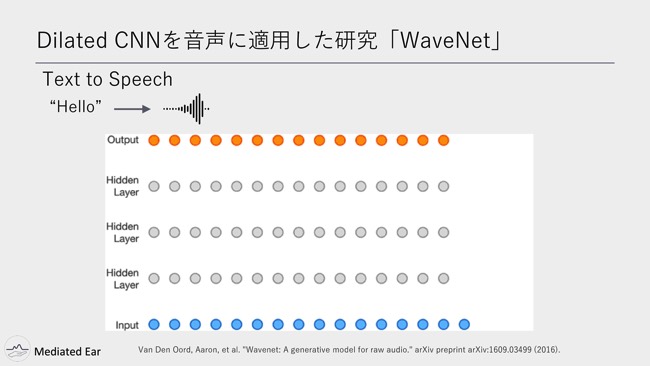
音声の情報量って、時間的に近いものと遠いものの両方を学習する必要があります。近いものというのは例えば発音記号であったり。遠いものっていうのはイントネーションとかアクセントというような情報があります。それらの時間的に短い情報と長い情報の両方を一気に学習できるのがDilated CNNです。
Mediated Earでも、このDilated CNNやWaveNetで使われているテクニックをいくつか採用しています。
競合との比較、データ量、抽出対象について
DNNの構造についてはここまで。あとは競合との比較です。ちょうど先週、Google Researchが「複数音から特定の発話者の声だけを聞こえるようにする深層学習手法」というのを発表しました。Imagine Cupの発表4日前だったんで、ちょっとびっくりして、急いで論文読みました。

このGoogle Researchの手法は顔認識と音源分離の2つを使っています。なので発話者の顔画像が必要になります。一方、Mediated Earは音声データのみで分離を行うので、そこが違いかと思います。
ここで、「Mediated Earの訓練データに必要な抽出対象人物の音声データ量は?」ということが気になると思います。これは最小で3分です。例えば自分の恋人の声を抽出したければ、その恋人の声を3分集めて学習を行うことで、その恋人の声が抽出できるようになります。ちなみに5分とか10分とか30分でもやったんですけど、あんまり精度変わりませんでした。
「Mediated Earのユーザーはどのような人を抽出対象とするか?」と。実際に使うときには事前に学習させなきゃいけないので、その場で会った人とかにはちょっと使えないんですね。じゃあ実際に補聴器をしている人はどういう人に対して使うかというと、そのユーザーの家族や恋人、仲の良い友人など、頻繫に会話する人の声をあらかじめ学習して使うのではないかと想定しています。
実はこれはデメリットに見えてメリットがあって。親しみのある人の声、親とか恋人とか孫の声を聞くことは、聴覚が低下した人に対して聴力を向上させる可能性があるという研究が出ています。
なので親しい人の声をいつでもどこでも聞くことが可能になるだけで、こういった聴力が低下した人というのは、聴力向上の機会を多く掴むことができるということです。
ユーザーからのフィードバックと今後の展望
実際にユーザーからもフィードバックをもらいました。冒頭に話した大学時代の友達なんですけど、このMediated Earで抽出した音を聞かせに行きました。
まずMediated Earで抽出した音は、「対象者の声が聞きやすくなっている」と。あとは、あとは「日常生活で聞きづらいシーンというのは意外とザワザワしている中で一人しゃべっている状況よりも、たくさんの人がしゃべっているときが一番会話相手の声が聞きづらい。Mediated Earは音源に雑音が含まれていても話者分離できるのがいい」という声をもらいました。
あとは「Imagine Cup世界大会で優勝して早く実用化してくれ」と言われて(笑)。これをちゃんと日本大会の決勝でも出して、しっかり世界大会へ送り出してもらいました。
発展性としては、「Wearableから『Hearable』へ」ということで、今、無線イヤホンがすごく流行っています。Google Glassとかは失敗してしまったので、眼鏡型より実はイヤホン型のほうが、ウェアラブルデバイスとして一般的に広がるんじゃないかと考えられています。
このイヤホンにMediated Earを搭載できれば、イヤホンを介して周囲の音も選択的に聞くことが可能になると。そうすれば聴覚障害者だけじゃなく、一般の人もMediated Earの恩恵を受けることができるんじゃないか、というふうに思っています。
チームです。

研究室の同期の富永と、あと僕、佐藤でやっています。今はソフトウェアだけなんですけど、世界大会までにはハードウェアと組み合わせて、なにかしら体に身につけた状態で使えるようにしたいと考えています。
発表は以上です。どうもありがとうございました。
(会場拍手)