「全体の開発の流れが見える状態」から「全部のプロセスが見えない状態」に変化する中で感じた危機
大沼和也氏:「開発生産性を計測し、開発組織の当たり前基準を上げていく」という内容で発表いたします。今日はどういうふうにやったかも軽くお話ししますが、どういった経緯や背景で、この生産性を追おうと思ったのかというところを主に話していきたいと思っています。
まず背景を説明します。最初は僕が1チームのスクラムマスターをやっていて、そのあとに複数チームを見る立場に変わっていったというところで、その1チームのスクラムマスターをやっていた時は自分も開発していたこともあり、基本的に全体のチームの開発の流れが全部見える状態だったんですね。
なので、各メンバーがどこで詰まっているのかとか、どこが迷うポイントなのかというのが基本的に全部わかっている状態で仕事をしていました。人数も当時は6、7人とか、10人いかないぐらいのチームをやっていたので、デプロイフローがあまり決まっていなかったりしても、そんなに問題なく開発がスムーズに進められている状態でした。

そこから、デジタルプラットフォーム部門で、もっと人を増やしてどんどん開発していこうと、ガンガン採用をやっていく中で、今度は複数チームでやっていきましょうというのがあって、チームが増えてきた時は1リポジトリを3チームぐらいで触っていました。
この中で不具合やホットフィックスが前よりけっこう増えてきました。そんな中で、QAせずにデプロイするのは危険だよね、デプロイのCI/CDまわりを整備するのも必要だし、QAを入れて週1にデプロイを抑えようという流れになったんですね。僕も複数チームを見る立場だったので、自分が全部関わっているところと変わってきたなと思うところがありました。
全部のプロセスが見えていないので、問題の発見が遅れがちになったなと思うところがありました。当時はリリースブランチ、masterブランチで運用していて、masterにどんどんマージしていって、リリースブランチに反映すると本番環境にデプロイされるという流れだったのですが、特に年末年始などはプルリクエストが溜まってくるので、Files changed 379みたいな感じで、1リリースPRがかなり大きくなっている状態でした。
この時はたまたまうまくいったからよかったのですが、もし「不具合が起きました」となった時に、この300ファイルの中で具体的にどのファイルに問題があったのかがわからないよなと思っていて、少しずつここで危機を感じ始めていました。

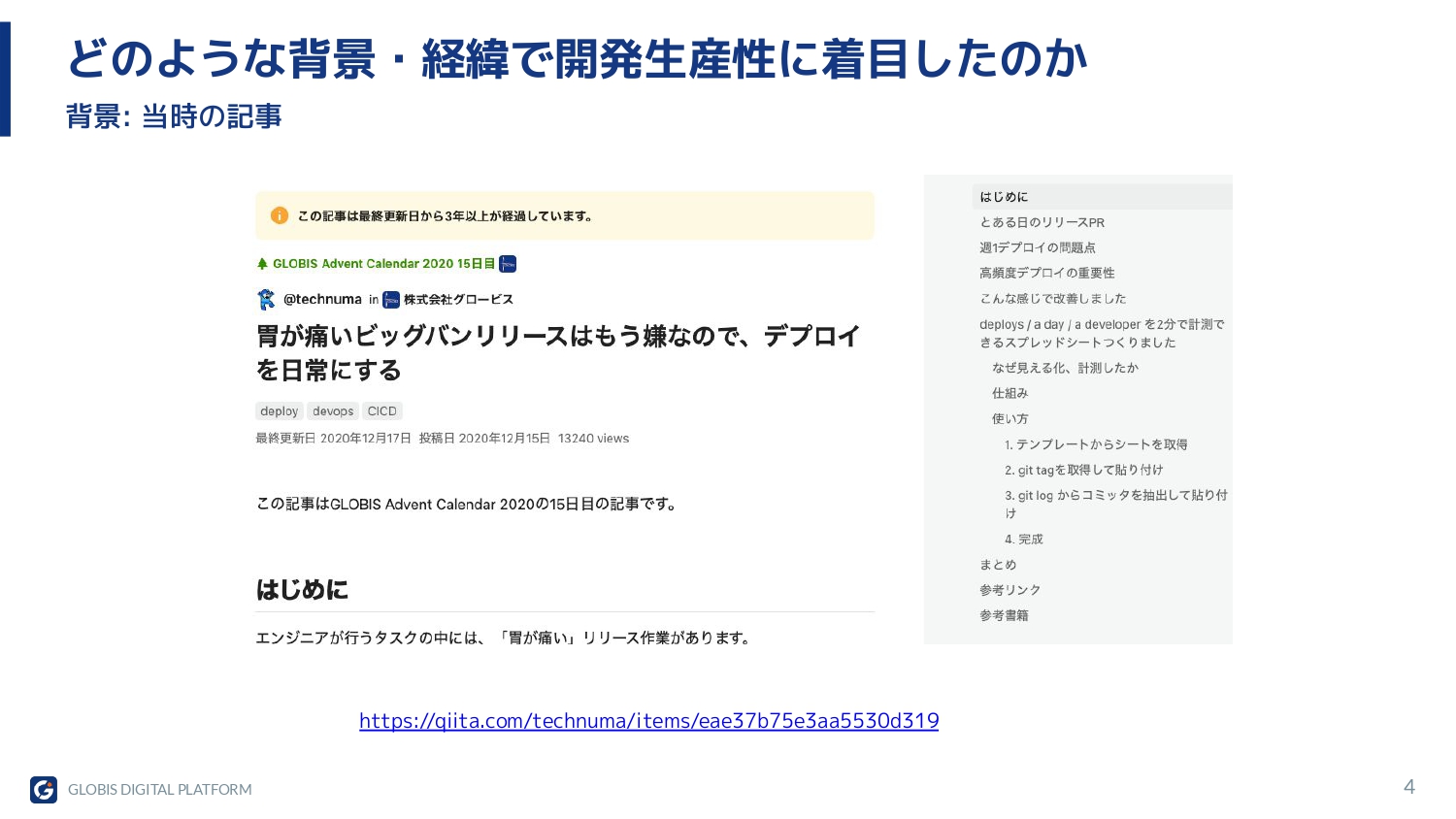
詳細は2020年に記事を書きました。「300ファイル以上のデプロイでもビッグバンリリースだな、ビッグバンリリースは嫌だな」と思っていて、このプルリクエストをマージするのにめちゃくちゃドキドキするのが嫌だったので、それを分割してデプロイを日常的にできないかと考えて書いた記事です。もしよかったら見てみてください。
「Four key metrics」を知ったきっかけ
そこから、事業に関わってくるチームが6チームに増えてきたタイミングで、うちの開発組織っていい感じなんだっけ? というのが僕の中でもわからなかったんですね。いい・悪いって曖昧な指標だなと思っていて、それをもう少し裏付ける、ブレイクダウンしたものはなにかないんだっけ? というのを考えたいなと思って、こういった取り組みを始めました。
けっこうプロダクトだと、A/Bテストや、この指標が上がったからこの機能はおそらくいいものなんだと見ると思いますが、それと似たようなことが開発組織でできないんだっけ? と思ったんですね。ざっくり印象として頭に残っているのが2012年ですかね。
その頃アマゾンの組織は1時間に1,000回ぐらいデプロイしていて、単純にすごいなと思った記憶がちょっと残っていたのもあって、デプロイをたくさんしているのって、なんかかっこいいなと、なんとなく頭にあった状態でした。
2018年、2019年頃のt-wadaさんの「質とスピード」ですね。このスライドの中で、Four key metricsというものが良さそうな指標として掲載されていて、そのスライドの終わりのほうに参考資料として『LeanとDevOpsの科学』という書籍が紹介されていたので、「あ、ちょっとこれを読んでみよう」と思って読み始めたのが最初のきっかけですね。
これを調べていくと、GoogleもFour key metricsを重視しているということで、けっこう信頼できそうな数字だなと思いました。特に当時は、Googleだったり、Netflixのエンジニアが入った時に「いや、こんな開発組織だとちょっとダルすぎるので働けないです」とか言われちゃうと困るなと思っていました。
なので、そういった人たちが入ってきても「いい環境ですよ」と言える組織になったらいいなと思っていたので、この指標を追うようにしました。

「組織に対して正しい積み上げをしたい」と思った
そこからさらに2021年頃ですかね。これもちょっと曖昧ですがCTO協会。広木大地さんがたぶんメインで上げられている「DX Criteria」というガイドラインが公開されて、うちのグロービス デジタルプラットフォーム内でも、実際に自分たちでアセスメントしてやってみようということで、マネージャー陣でやりました。
そこで「ここちょっと点数が低いけど大丈夫かな?」というところをお互いに認識合わせして、やるべきところは改善につなげたというのを動きとしてやっています。自分自身の経験としても、10人規模のベンチャーがけっこう長く、マネージャーをまったくやったことがなかったというのもあって、組織に対して正しい積み上げをしたいなと一番思ったんですね。
めちゃくちゃ仕事をがんばっていても、正しい積み上げができておらず、来年どんどん楽になっていく、良くなっていくという感覚が持てなかったらあまり意味がないなと思っていたので、例えば週1デプロイの状態で、デプロイのQAをめちゃくちゃがんばるというということがあったとします。
確かにがんばってはいるのですが、品質の問題に対してどんどんがんばっていたところで、フェーズゲートQAのようなかたちになってしまい、最終的にデプロイ頻度を上げていかないとお客さんに価値を届けるスピードは上がっていかないので、本当にやった行動が正しい積み上げかどうなのかというのをめちゃくちゃ気にしています。
健康指標として、このFour keysがけっこう使えるなと。最近は「SPACE」とか言われたりもしますが、使えるなと思っています。個人的な感覚としてはけっこう楽しさも大事だと思っていて、楽しくて快適なんだけど、生産的な状態になれているというところを環境として作れたらいいなと思っています。
良いことが当たり前になるように積み重ねることが大事
いいデフォルトがけっこう大事だなと思っていて、グロービスは中途入社の方がかなりの割合を占めているので、今の環境はいろいろな経緯でこうなったんだろうなと思われることがけっこうあるんですね。僕はそれはあまり良くないなと思っていて、逆に良い当たり前を作っておいてそこが普通になっていくみたいなものを積み重ねるのがけっこう大事だと思っています。
デプロイが本当に危ないなと思ったら、すぐに切り戻せる。10秒以内に切り戻せる状態でデプロイするとか、これはフィーチャーフラグなどを使うとできるんですが、そのプルリクエストのサイズはできるだけ小さいほうがいいよねというところ。例えばサイズでいうと、データベースの変更で1PRでぜんぜんいいと思っていて、そこから機能開発で1PR。
実際に機能を有効化したり、導線をつないだりというところもプルリクエストを分けていいと思うので、それぐらいの小ささでどんどん開発が回っていく状態が普通になっていくといいなと思っています。プロジェクトも大きな理由がなければ3ヶ月以内で収まるようにやっていきたいなと思っていて、半年や1年とかになってくると、やはり難易度が劇的に上がるなと思っています。
全体としては長くてもぜんぜんいいのですが、そのフェーズ切りというか。ここまでで1回リリースみたいなものは細かくしていくといいなと思っています。
CIは体感ですが、10分以内ぐらいに終わらせるようにしたいなと思っています。やはり1日かかったりすると、極端な話、回されなくなってしまいます。並列化はしてもぜんぜん問題ないので、うちもたくさん並列化していて、10分以内に終わらせることをデフォルトにしていきたいなと思っています。
そんな感じで、強い理由がなければ「こんなデフォルトでいいんじゃないの?」みたいなところを当たり前にして、当たり前基準を作っていきたいと考えています。

デプロイ頻度、リードタイム、変更失敗率…それぞれの定義
定義はサラッといきますね。デプロイ頻度は、デプロイを日付で割って、その開発者数でさらに割っています。営業日、あとは開発者の数で割るとブレがなくなるので、これはけっこうおすすめな指標です。
リードタイムは「Findy Team+」を導入しているので、コミットしてからプルリクエストがマージされるまでの時間が計られていて、MTTRは障害発生時から解消までの時間です。
変更失敗率は、Revertしたプルリクエストを全体のプルリクエストで割って、100をかけたものを見ています。変更失敗率は厳密には見れていないんですが、たいだいそんな感じというのと、現状はそんなに問題が起きていないというところで、この粒度で見ています。

リードタイムやデプロイ頻度は、今は多くのチームで取っています。あとは組み込み方ですね。健康指標として週次でスクラムオブスクラムで確認しています。チームによっては週次のふりかえりで数値を確認して、そこからチームごとに改善アクションをつなげているところもあります。
もともとなかったけれど入れたものでいうと、フィーチャーフラグを導入しています。うちはまだデプロイに7、8分ぐらいかかっちゃうんですが、フィーチャーフラグをデータベースで管理しているので、機能のON・OFFを10秒以内ぐらいでできる仕組みが入っています。ここもチームによりますが、自分の開発作業よりもレビューを優先するというところで、1つのプルリクエスト単位のリードタイムをどんどん短くしていくというのをやっています。
あとはそのモブ設計やモブレビューを通じて認識合わせをしています。プルリクエスト上で非同期でやり取りをすると、どうしても時間がかかってしまうので、設計やレビューを、Zoomやハドルでやって、認識合わせの時間を圧縮しています。
あとはKubernetes化と環境改善を行っていて、ステージング環境を増やしやすくするというのをやったりしています。

以前はステージング環境を増やすのに、1日や2日かかっていたのですが、今はたぶん半日ぐらいでできるような仕組み作りができています。
以上で終わります。開発のブログ、採用サイト、アドベントカレンダーなども公開しているので、興味があればこちらも合わせて確認いただけると助かります。以上で終わります。

継続的に改善を試みるチームにするためのマネジメントメソッド
司会者:ありがとうございました。みなさんもパチパチパチとお願いします。開発組織として正しい積み上げをするための仕組み作りという考えのところから、いいデフォルトを作るために開発生産性へ着目されたという話があったと思います。
「楽しく快適かつ生産的になれているか」というところへの共感コメントが多数出ていましたね。今回もともと「connpass」ページでお申し込み時にアンケートを募っていてけっこう質問が来ていまして、そちらからまずはおうかがいできればなと思います。「定量的に可視化されたメトリクスをチームが継続的に見たり、改善を試みるようにしていくためのチームマネジメントメソッドの具体例が聞きたい」ということですが、こちらは回答をいただけますか?
大沼:そうですね。メトリクスをそのままチームが見るというのも確かに大事ではありますが、自分の感覚としてはその前段として、なんでこのメトリクスを追う必要があるのかという話をいかにチームに伝えるかがすごく大事だなと思っています。
例えば、そのデプロイ頻度やプルリクエストの細かさとか。デプロイ頻度って、プルリクエストを細かくしていかないと上がらない。
というのと、週次デプロイとかではなくて、プルリクエストごとにどんどんマージしてデプロイする仕組みを取らないと上がりにくいものではあるんですね。その中で、じゃあなんでプルリクエストって細かく分ける必要があるんだっけというのは、けっこう開発したツラみとかをセットで認識すると一番いいなと僕は思っていて、開発作業って基本的には抽象的なものを具体化していくというフローの中があると思っています。
チームで開発していると必ず認識合わせをしていって抽象を具体化していくというステップがあると思っていて、例えばそのデータベースのスキーマがズレている状態で実装の話をしたら基本的にズレちゃうなと思うんですよね。例えばクラスの構成のイメージがズレていたら、絶対にその詳細はズレるはず。
テーブルやクラスを合わせた状態で次のステップに進むと、少なくともクラスとテーブルの認識は合っているよねという状態で進めるので、すごくおすすめなんですよね。なのでそういった戻りなどが発生したタイミングで、きちんとふりかえりで「これってなんでなんだろう」と、しっかり1個ずつ深堀っていく。
1個ずつそれを見ていくと、だいたいこういったところにたどり着くなという感覚があります。その一つひとつの指標が大事だねとチームが思ってくれると、わりと自らその改善につながっていく印象があります。
司会者:メトリクスの背景から実際の活用例までお話いただいてありがとうございます。
健康指標というかたちで取り入れている
司会者:まだ質問があるので、そのまま進めていければと思います。こちらも事前質問です。開発生産性をどのように組織運営に組み込んでいるのかはお話いただいたと思いますが、目標あたりですかね。「KGIやKPIとして数字として定義しているのか、それともOKRとして定義されているのか」といったところをご回答いただければなと思ったのですが、こちらはいかがでしょうか。
大沼:KGIやKPIには定義していないですね。OKRも定義はしていなくて、どちらかというと健康指標という側面が強いかなと思っています。広木大地さんもDeploy/a day/Developerみたいな、「0.1を下回ると何かしら問題がある。それ以上はなんか健康である」という感じのツイートをされていました。
うちの組織も健康指標として基本的に全部使っていて、これがちょっと落ち込んでくると、大丈夫かな? というのをヒアリングしたり、確認に行ったりしています。
司会者:なるほど。ありがとうございます。健康指標というかたちで取り入れているということなので、そういった捉え方自体の違いはあるのかなというところです。
Four key metricsを選んだ理由
司会者:次も来ているので回答いただきたいなと思います。「計測できるメトリクスの候補はさまざまあったかと思いますが、最終的に発表いただいたメトリクス」……先ほどの資料ですかね。「(発表いただいたメトリクス)に決まったプロセスを教えていただきたいです」というところですが、こちらもお願いできますか。
大沼:メトリクスはそうですね。いろいろあるなと思っていて、Four key metricsは、かなりデファクトスタンダードになっていたというのが大きいところ。『LeanとDevOpsの科学』の作者も言っていますが、最近はSPACEというものも新しくできたので、今はそちらも参考にしています。やはり業界標準というのが一番大きいところですね。
「業界」というのは、「金融だからデプロイ頻度が上げにくいです」みたいな、そういう話がないというのが一応証明されている内容になっていて、「うちの業界だから無理です」みたいな言い訳が一応通用しないと書かれているので、それってすごくいいなと思って採用しました。
あとはデプロイ頻度から僕は始めたのですが、デプロイ頻度は高くなって困ることがないので、多少ハックされている。1行ずつにプルリクエストを作ったらアップされちゃう仕様で、あまりそれに意味はないんですが、それでも細かすぎて困ることはほぼない指標だなと思っているので、始めやすいかなと思っています。
司会者:ありがとうございます。回答になっていたら幸いです。
組織への周知やフィードバックをどうしているか
司会者:そのまま、次の質問もいければなと思います。「開発生産性の向上のために各種アーキテクチャの選定や周知も必要だと思いますか? また、思うとして何を基準に選定を行って、組織への周知、フィードバックはどのような工夫をして行っていますか?」というところなんですけれども。ちょっと長いですが、こちらもお願いできますか?
大沼:確かにこの指標が崩れやすくなるようなアーキテクチャの選定は、僕はちょっと危ないかなと思っています。基準や選定で言うと、先ほどお話しした認識合わせのプロセスというのが、開発をやっていく上ですごく占めると思っています。
レビューをやっていても思うんですが、うちのフレームワークや、バックエンドはRailsでできている部分が多くて、ある程度Rails Wayみたいなものが整理されているフレームワークになるので、その書き方とか、何をどこに書くかみたいなところの意見の相違があまりないのが1個いいなと思っています。
うちの場合は特に複雑なドメイン領域を扱う開発なので、さらにそこに技術的な複雑さがあるとなると、複雑でもうめちゃくちゃ認知負荷が上がっちゃうというのが1個あるので、ここは事業にあった特性で選んでいいかなと思っています。基準はそんな感じですかね。
組織への周知やフィードバックは、一応うちの場合はADR、Architecture Decision Recordですかね? という、バックエンド全体で今はこういうふうにしましょうというところの合意を取っていく場があるので、そういったかたちで少なくともバックエンド陣全員は合意した状態で進めています。
司会者:ありがとうございます。今来ているご質問には回答いただけましたので、「もうちょっと聞きたかった……」みたいなことがありましたら、Q&Aにご投稿いただいて、その際は大沼さんからテキストで回答できればなと思いますので、こちらでいったん以上とさせていただきます。あらためまして、大沼さん、ご発表ありがとうございました。
大沼:ありがとうございました。