


 PR
PR2025.11.27
数理最適化のエキスパートが断言「AIブームで見落とされがちな重要技術」 1,300社が導入した「演繹的AI」が意思決定を変える
コピーリンクをコピー
ブックマーク記事をブックマーク
fadis氏:簡単なGLSL(OpenGL Shading Language)の例を見てみましょう。ここでバッファを宣言しています。スレッドIDからバッファのどこに書くかを決定し、各スレッドが自分が担当するバッファの要素をインクリメントします。

ここでGLSLのソースコードは「bindingが1のバッファをoutput_dataに結びつけよ」といっていますが、bindingが1のバッファとはどのバッファのことでしょうか。

VulkanのAPIで作ったいくつものオブジェクトのうち、どれをシェーダに結びつけるかを決める対応表がディスクリプタセットです。vkUpdateDescriptorSetsで、バッファBとbinding=1が対応していることをディスクリプタセットに書き込むと、シェーダのoutput_dataはバッファBの内容が見えるようになります。

ディスクリプタセットは、ハードウェアの限られたレジスタを使って実現されていることがあります。そのため、メモリのアロケートとは別に用意された、ディスクリプタセット専用のプールから作成します。

ディスクリプタセットになんの対応関係をいくつ書き込む必要があるかを指定するのが、ディスクリプタセットレイアウトです。ディスクリプタプールにディスクリプタセットレイアウトを渡すことで、要求した数の要素を書き込めるディスクリプタセットが作られます。

ここで気になるのは、必要なディスクリプタの数。つまり「bindingが何個シェーダの中に存在するかは、プログラマーが指定しなくてもシェーダのSPIR-Vを読んだらわかるのでは」ということです。

これは実際そのとおりで、SPIR-Vを漁って必要なディスクリプタの数を取得できるライブラリが存在します。Vulkanがこれを自動で行わないのは、ベンダーが個々にこの機能をドライバに実装する必要を無くすためです。

ディスクリプタセットができたらパイプラインを作ります。これは「どのシェーダモジュールを使うか」ということと、「そこにどのようなレイアウトのディスクリプタセットをつなぐつもりか」という情報を結びつけます。

ディスクリプタセットはトランポリンのようなものです。ディスクリプタセットの要素数とシェーダモジュールが組み合わさることで、実行時にディスクリプタセットを動的リンクして実行可能バイナリを作れるようになります。

パイプラインには、後ほど述べるグラフィック描画用のグラフィックスパイプラインと、任意の計算を行うためのコンピュートパイプラインがあります。グラフィックスパイプラインは大量の設定項目が並んでいますが、コンピュートパイプラインはおおざっぱに扱うディスクリプタセットのレイアウトと、シェーダモジュールを指定しているだけです。

パイプラインを作る時は、パイプラインキャッシュをつけられます。パイプラインキャッシュには、過去に生成した実行可能バイナリがキャッシュされます。以前と同じ条件でパイプラインを作ると、キャッシュの内容が使われます。

パイプラインキャッシュを作ります。これはいつでもシリアライズすることが可能で、作成時に過去にシリアライズした内容を渡すと、異なるプロセスで作った実行可能バイナリを二次記憶に保存して再利用できます。


シリアライズされた内容はベンダー依存で、パイプラインキャッシュを保存してからGPUを変えてパイプラインキャッシュを読むと、チェックの甘いドライバがよくお腹を壊すことが知られています。
実行可能バイナリが用意できました。あと必要なのはこれを何スレッドで実行するかです。GPUで実行可能バイナリを動かすコマンドvkCmdDispatchをキューに積むと、引数で指定したスレッド数でGPU上で計算が開始されます。

GPUに送ったコマンドは、コマンドバッファに並んだ順に実行される保証はありません。GPUのプロセッサーに空きがあれば複数のDispatchを同時に処理させることもありますし、ただちに実行できる状態にないDispatchは後回しになることもあります。複数のDispatchの間にデータの依存関係があり、決まった順序で実行されなければならない場合、メモリバリアを挟んで依存関係を明示します。


バリアに依存関係があるバッファを渡してキューに流すと、「バリアの前にこのバッファを触ったコマンドが完了するまで、バリアの後でこれを開始してはいけない」という意味になります。


では、さっそく動かしてみましょう。動かすのは先ほどのインクリメントするだけのシェーダです。ゼロクリアしたメモリをGPUのバッファにコピーします。コピーの完了を待ってから、ディスクリプタセットとパイプラインを指定して実行します。


実行の完了を待ってから、GPUのバッファの内容をCPUのバッファにコピーします。ここまでの内容をコマンドバッファに記録して、キューに流します。その内容の実行が完了したら、GPUから戻ってきたデータをJSONにしてダンプします。すると、メモリの中身がすべてインクリメントされています。


よく忘れられることなのですが、GPUのGはGraphicsのGです。GPUはもともと画像を描いて画面に送るための装置です。

バッファの中にRGB各8bitの明るさを記録して、「これは画像だ」と主張することもできなくはないのですが、Vulkanには画像を扱うためのより便利な方法が用意されています。メモリをvkBufferではなくvkImageにバインドすると、「そのメモリに置かれているデータが画像である」とVulkanに伝えられます。

BufferとImageの大きな違いは、Imageの場合Vulkanはメモリ上のデータの並びを画像の用途に応じて変更する点です。ここでいう変更には、アラインするためのパディングの挿入、ピクセルの順序の変更、レイヤーやミップマップの記録位置の変更などが含まれます。

なぜ画像のフォーマットを変える必要があるのか、簡単な例を見てみましょう。イメージをテクスチャとしてシェーダの中から読むことを考えます。
テクスチャのサンプリング位置は浮動小数点数なので、ピクセルとピクセルの間の色を補間によってでっちあげなくてはなりません。線形補間なら4点、Cubic補間なら16点の近傍のピクセルを読むことになります。

もし画像が単純な行メジャーでメモリに置かれていた場合、y軸方向、つまり列方向に隣接するピクセルはメモリ上では離れた位置に配置されます。それは、すでにキャッシュに乗っている可能性が低いということです。

一方、こんなふうにジグザグな順番でピクセルがメモリに置かれていると、y軸方向で隣接するピクセルがそこそこ近くに配置されるため、最初の1ピクセルの読み出しで同一キャッシュラインに乗る可能性が高くなります。このような理由から、テクスチャサンプラーは一般にタイル状にピクセルを並べた形式を要求してきます。

イメージは作成時に用途を1つ以上設定します。これでこのイメージは指定した用途に適したピクセルレイアウトへの変換が可能になります。イメージに割り当てる必要があるメモリのサイズは、変換可能なレイアウトのうち最も大きなメモリを必要とするレイアウトでのサイズです。

例えばコンピュートパイプラインで画像を生成し、それをCPU側に送る場合。コンピュートパイプラインから値を操作できる、VK_IMAGE_LAYOUT_GENERALから転送に適したVK_IMAGE_LAYOUT_TRANSFER_SRC_OPTIMALに変換して送ることになります。

あるピクセルの値がメモリ上のどこにあるかはVulkanしか知らないので、イメージのピクセルの値には専用の関数を通してアクセスします。

このようにコンピュートシェーダを使って画像を描くこともできなくはないのですが、これは一般的な方法ではありません。なぜなら、GPUには効率よく3Dグラフィックスを描くための専用ハードウェアがいろいろと載っているからです。
例えばここにあるPolyMorphは、大きすぎる三角形を複数の小さい三角形に分割する計算をハードウェアで行います。ラスタライズは頂点座標で定義された三角形が、画面上の描画先のどのピクセルに影響を与えるかを求めるハードウェアです。


Raster Operatorsは、シェーダの実行結果を集めてアンチエイリアスやカラーブレンディングといった色の合成を行い、描画先のイメージに記録する色を決定するハードウェアです。

このように3Dグラフィックスを描くという観点では、今日のGPUは大量の任意の計算を行うプロセッサーの横に、ソフトウェアで計算するとつらい処理を支援するハードウェアがつながった構成になっています。

これはラスタライズで3Dグラフィックスを描く処理のパイプラインです。このうち、紫で示した部分に対して、ソフトウェアより効率よく処理できるハードウェアが備わっています。

したがって、レンダリング処理全体を1つのSPIR-Vにするのではなく、ハードウェアが処理しないステップに対して1つずつSPIR-Vのコードを割り当てて、パイプラインを完成させる必要があります。これをするのがグラフィックスパイプラインです。


グラフィックスパイプラインは、コンピュートパイプラインに比べると、結びつけられるシェーダモジュールの数が増えています。さらにグラフィックスパイプラインでは、ハードウェアで処理する部分の振る舞いを指定するパラメーターが追加されています。


コンピュートパイプラインと違い、グラフィックスパイプラインは直接キューに流すのではなく、「レンダーパス」と呼ばれるものに詰めてからキューに流します。

レンダーパスは、複数のグラフィックスパイプラインを束ねたものです。これが必要になった経緯は、3Dグラフィックスのレンダリング手順と深い関係があるので、一般的なレンダリングの流れを見てみましょう。

近代的な3Dグラフィックスは、1本のパイプラインで完結することはまれです。多くの場合、1つ目のパイプラインの出力を2つ目のパイプラインに入力として渡すマルチパスレンダリングを行います。

例えば、遅延レンダリングの1段階目のパイプラインで、イメージに対して各ピクセルの座標、法線、深度、材質などの照明の条件となる値を記録します。このようなイメージは「Gバッファ」と呼ばれます。

次にGバッファを入力して別のパイプラインで照明の計算を行います。1つの照明の影響を計算するパイプラインを複数実行して、その結果を足すことでたくさんの照明に照らされたシーンを描きます。

個々の照明はGPUのプロセッサーに余裕があれば同時に計算できるため、こうしたほうが単一のパイプラインの中ですべての照明を順番に計算するよりスケールします。

さらにGバッファに記録されなかった、つまりなにかの背後にあって最終的に見えなくなる位置は、以降の計算では考慮されなくなるため、最終的に表示されないものを、時間をかけて計算することを防げます。

この他にも、照明の位置からレンダリングした結果を照明の計算の際に参照することで、ある位置に光が本当に届くかどうかを判定したり、レンダリング結果に被写界深度効果のような画像処理を施すために、さらにパイプラインを追加したりといったことが行われます。


複数のパイプラインの間にデータの依存関係がある状態です。であれば、コンピュートパイプラインで見たように、「パイプラインの実行の間にバリアを置けばよいのでは」と思うかもしれません。実際この方法でマルチパスレンダリングを組むことはできます。しかしこの方法はモバイルGPUでは性能が出ないのです。

(次回へつづく)
続きを読むには会員登録
(無料)が必要です。
会員登録していただくと、すべての記事が制限なく閲覧でき、
スピーカーフォローや記事のブックマークなど、便利な機能がご利用いただけます。
すでに会員の方はこちらからログイン
名刺アプリ「Eight」をご利用中の方は
こちらを読み込むだけで、すぐに記事が読めます!
スマホで読み込んで
ログインまたは登録作業をスキップ
この記事をブックマークすると、同じログの新着記事をマイページでお知らせします
PR2025.11.27
数理最適化のエキスパートが断言「AIブームで見落とされがちな重要技術」 1,300社が導入した「演繹的AI」が意思決定を変える
 PR
PR2025.11.28
「あの人がいなくなったら仕事が回らない」を解決 属人的な業務から脱却する「最適化」の実践方法
 PR
PR2025.11.28
「計画と運用」をごちゃ混ぜにすると崩壊する ビジネスに使える最適化システムの“境界線”の引き方
 PR
PR2025.11.27
9割がリピーターでも“飽きられない”仕掛け 馬渕磨理子氏×オリエンタルランドが語る、体験価値と「成長の3本柱」
 PR
PR2025.11.28
“テーマパークの外”への挑戦で売上1兆円を目指す 馬渕磨理子氏が迫る、オリエンタルランドの新領域戦略
 PR
PR2025.11.28
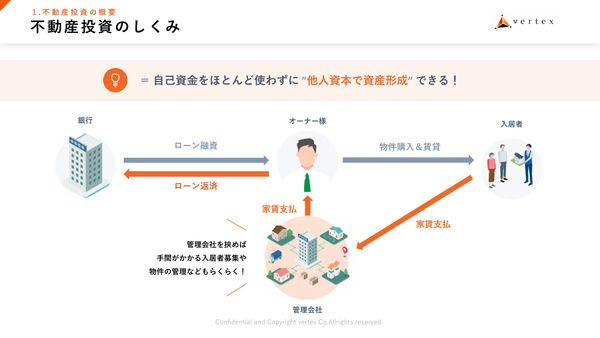
物価上昇時代の“もう1つの収入源” 自己資本約10万円から始められる、不動産投資の仕組みとリスク解説
 PR
PR2025.11.27
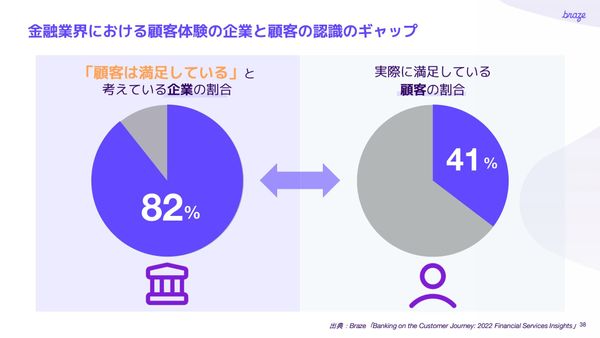
AIで激変する顧客体験──「金融機関」と「消費者」の関係を再設計 Brazeが描く“真の顧客エンゲージメント”とは
 PR
PR2025.11.28
金融機関の休眠顧客をアクティブユーザーへと転換 Brazeが提供する、収益改善を実現する「パーソナライゼーション」事例
 PR
PR2025.11.28
管理職に求めすぎる組織の限界 役割分割で生まれる新しいチーム運営
 PR
PR2025.11.27
「考えろ」と言うだけの上司が組織を壊す 自律型人材が育たない本当の理由
PR2025.11.27
数理最適化のエキスパートが断言「AIブームで見落とされがちな重要技術」 1,300社が導入した「演繹的AI」が意思決定を変える
PR2025.11.28
「あの人がいなくなったら仕事が回らない」を解決 属人的な業務から脱却する「最適化」の実践方法
PR2025.11.28
「計画と運用」をごちゃ混ぜにすると崩壊する ビジネスに使える最適化システムの“境界線”の引き方
PR2025.11.27
9割がリピーターでも“飽きられない”仕掛け 馬渕磨理子氏×オリエンタルランドが語る、体験価値と「成長の3本柱」
PR2025.11.28
“テーマパークの外”への挑戦で売上1兆円を目指す 馬渕磨理子氏が迫る、オリエンタルランドの新領域戦略
PR2025.11.28
物価上昇時代の“もう1つの収入源” 自己資本約10万円から始められる、不動産投資の仕組みとリスク解説
PR2025.11.27
AIで激変する顧客体験──「金融機関」と「消費者」の関係を再設計 Brazeが描く“真の顧客エンゲージメント”とは
PR2025.11.28
金融機関の休眠顧客をアクティブユーザーへと転換 Brazeが提供する、収益改善を実現する「パーソナライゼーション」事例
PR2025.11.28
管理職に求めすぎる組織の限界 役割分割で生まれる新しいチーム運営
PR2025.11.27
「考えろ」と言うだけの上司が組織を壊す 自律型人材が育たない本当の理由

