



 PR
PR2026.01.19
業務フローを変えずに、メール1通3分を削減 自動でAIにナレッジが貯まる問い合わせシステム「楽楽自動応対」
急成長中のレシピ動画サービス『クラシル』を運営するdelyが、 これまでのグロース戦略、エンジニアリング方針、ユーザー調査手法等についてお話しします!(全6記事)
コピーリンクをコピー
ブックマーク記事をブックマーク
深尾もとのぶ氏(以下、深尾):みなさんこんばんは。今日はデータウェアハウスについてお話しさせていただこうと思いますが、データウェアハウスとはなにかご存じですか?
(会場挙手)
あんまりいらっしゃらないですね。データウェアハウスというのは、昔はすごく大きい会社で何億円というお金をかけて作っていた、大量のデータを分析するときに使っていたものです。簡単に言うと、ビッグデータでSQLが回せるみたいなものです。
3〜4年ぐらい前から、AWSのRedshiftというサービスが出てきて、それでかなり身近になりました。そこがさらに進化して、昨年ぐらいからGlueというのが出てきました。これを使うと、例えばS3にCSVファイルなどを置くと、それがSQLで使えるというように、簡単に作れるようになったという話をしたいと思います。
自己紹介でSREという紹介がありましたが、僕はプロの料理人を8年ぐらいやっていました。今はSREをやっているんですが。SREというのはインフラエンジニアなんですけど、今日お話しするのは、最近始めたデータ可視化推進室のことがメインになります。
クラシルの分析基盤。今作っているデータウェアハウスが4世代目で、最近、2つのダッシュボードを作っています。Redshiftと先ほどお話ししたGlueの話、最後の時系列テーブルは今日の感じだとあまり役に立たない話かもしれません。
まずは分析基盤について。データウェアハウスを含めた分析基盤は大きく分けてこの3つのレイヤーがあると思います。
ダッシュボード。みなさんも見るんじゃないかなと思うんですけど、Re:dashとかGoogle Analyticsとか、そういったダッシュボードの可視化のレイヤー。
あとは、分析のレイヤー。SQLを回すようなBigQueryというのはたぶん知っているかな。今日お話しするRedshiftとか。
そこに向けてデータを貯めるログ収集基盤も必要で、マネージドのKinesisというサービスがあったり、自社で構築するFluentdといったOSSのサービスがあったり。
Google Analyticsはこの3つのレイヤーに跨っているサービスになります。今日お話しするのはこの全部3つ含めた話になります。
今まで4世代を渡ってきたんですが、第1世代はGoogle Analytics、第2世代Logpose。弊社はちょくちょくONE PIECEが絡んできます。第3世代はFirebase Analytics。そして現在作っているのが、第4世代、Eternalposeです。
まず第1世代がGoogle Analyticsです。長所短所なんですが、開発コストが圧倒的に安い。無料でも簡単に導入できる代わりに制限があります。基本的にはSQLが使えなくて、高額のオプションでBigQueryにエクスポートできますが、基本的には無料なので、簡単なかわりに制限がいろいろとあります。
そこで、第2世代で自社で最初に構築したのがLogposeです。Fluentdを使ってBigQueryにデータを送るというものを作りました。そうすることによって、SQLが使えるようになったり、GA(Google Analytics)のときは制限があったんですが、スケーラビリティを確保をして、データが増えてもBigQueryで集計ができるようになりました。
短所としては、最初に作ったのでデータの設計、テーブル設計が必ずしもよくなかったので、スケールするたびにスキーマを変更したり、もしくはSQLを組み立てるのが大変だったり。あとは、Fluentdは自社で管理しなければいけないので、ログ基盤の管理が大変だったりという短所がありました。
そこでマネージドのサービスに乗せ替えようということで、第3世代、GoogleのFirebaseのAnalyticsを使いました。これでログ基盤の管理が不要になりました。これがいいのは、データをBigQueryにエクスポートすることができるので、従来の長所だったBigQueryも使えることです。
一方で、仕様変更があってBigQueryにエクスポートするときに、データの仕様が変わったり、BigQueryに出してそこでクエリかけると、1つのカラムにデータが全部乗ってしまったりして、カラムで絞ってもクエリ料金が高額になってしまいました。
あとは、全体的にFirebaseは機能が未完成というか、まだ発展途上な感じがありました。APIや、Predictionsという機能がちょっと使いづらかったです。
そこで今作っているのが第4世代です。Sunnyというのは自社基盤の自社開発のダッシュボードで、MetabaseというのはRe:dashのようなオープンソースのダッシュボードです。データベースにつないでSQLを投げられるというダッシュボードになります。Eternalposeというのは自社のログ収集基盤です。
これはうちがつけた名前とサービスの名前が混ざっているんですが、「Sunny」というのは僕が勝手につけた名前ですね。弊社のビジョンに「BE THE SUN」というものがあるのですが、『ONE PIECE』のサウザンドサニー号から取っています。「Eternalpose」も『ONE PIECE』から取っているんですけど、Metabaseというのは、そういうオープンソースのサービスがあります。
2つのダッシュボード。なぜ2ついるのか? 最初はMetabaseだけで十分かなと思ったんです。最初にCTOから、ユーザーヒアリングの話や、サイクルを小さく回すみたいな話があったと思うんですが、僕もそこはやって。
最近、このプロジェクトが始まった時に、そのプロセスで僕もやったほうがいいかなと思って、営業さんに聞いたり、マーケの人に聞いたり。ユーザーヒアリングをしながらいろいろ聞いてみました。
Metabaseでもけっこういろんなことができるんですね。SQLでデータベースにつないでクエリを投げたり、Re:dashよりも、例えばパラメータを指定しやすい。ダッシュボードを作るときに、カレンダーで日付を絞って、その期間のクエリを投げるということをSQLを書かなくてもできるのがMetabaseのいいところです。
これさえあれば、日付を指定して動画のIDを指定すれば、SQLを書かなくても動画の再生数が出せたり、「これがあったらもう万能だよね」ってエンジニアとしては思うんですけど、実際にこれをドヤ顔で「こんなの作ったらどうだろう?」って聞いてみたら、「いや、そんなの大したことない」と。
ただ、昨日ヤフーとの提携の話がありましたけど、うちにたまたまヤフーでマーケティングをやっていた子がいて、その人に聞いてみると、ヤフーにはSQLなんか書かなくても、サービスに沿ったダッシュボードがあると。例えばヤフーだったら、「Yahoo!ニュース」とか「ヤフオク!」とかそんなメニューが並んでいて、そこをポチッとクリックすれば、もうそのヤフオク!のデータがわーっと出てくると。
それがうちも必要だと感じて作り始めたのが、先ほど話したSunnyです。これは、CoreUIというBootstrapというCSSのフレームワークを使って、自社で開発してるものになります。
検索エンジニアの話がありましたが、例えば検索、昨日の検索のトップ100が簡単に1クリックで見れるとか、そこに出てきた一番目が例えばキャベツだったら、キャベツをクリックしたらキャベツの過去3ヶ月の検索回数がグラフで出るといった、そういったものになります。
これがその長所・短所ですね。裏側はこんな感じになっていて、その中心にあるのがRedshiftとかGlueというサービスです。クラシルのアプリで行動ログをKinesisというAWSのマネージドのサービスで集計して、S3にログを置いて、それをGlueでクロールしてやると、自動でテーブル定義が作られるんですね。なので、JSONを置けばもうそこでテーブルが作られて。
これは別のAthenaというサービスでSQLを叩くことができるんですが、Athenaよりも僕はRedshiftを使っています。
RedshiftとかGlue、なぜそこがいいのかという話をすると、まずAthenaとRedshiftを比べたときに、Athenaはわりとシンプルで、しかもフルマネージドで低い学習コスト。エンジニアだったら低い学習コストで始められます。ほぼSQLを投げるだけなので。
一方で、Redshiftはなにがいいのかというと、1つは定額料金。Athenaはクエリ投げるごとに課金が発生するんですが、Redshiftは定額料金です。その分インスタンスのサーバー代金はかかりますが。
あと、SELECT INSERT。SELECTした結果を自由にほかのテーブルにINSERTできるというメリットもあります。
CTAS。これがけっこういいんですけど、SELECT INSERTに近いんですが、SELECTした結果でテーブルを作ることができるんですね。これはなにうぃ言っているかわからないと思う方もいるかと思いますが、これがけっこう大きいです。
あとは、Postgres互換だったり、Athenaよりも速かったりします。簡単ではないかもしれませんが、簡単に言うとこういうことです。カラム定義も、データのロードも、不要。
もともとAthenaや従来のRedshiftは、S3にデータを置いたら、そのS3のファイルのパスを指定して、なおかつ、そのファイルのフォーマット。「idがint型で、nameがstring型で」みたいなものを定義しなきゃいけなかったんですが、GlueとRedshiftを使うとそれが全部いりません。
最初に設定さえしておけば、あるディレクトリにファイルをどんどん置いておくと。そこをGlueが勝手にクローリングして、勝手にテーブル定義を定義してくれる。それに対してRedshiftで、先ほどのCTASのCreate Table As Selectなんですけど、それでSELECTした結果を別のテーブルにも入れることもできます。
そうすることによって、例えば全体のログがあって、全部のログが入ったテーブルがあって、そこから検索データだけをSELECTして検索のテーブルを作ったり、動画の再生数だけ集計してそのテーブルを作るといったことが、ほぼ自動でというか、SELECT文さえ書けば自由にできます。そこが一番のメリットかなと思います。
そんな感じで、S3に置いて、それをクローリングしたら、あとはCTAS。そうすればRedshiftでクエリが実行できます。それを可視化したのがMetabaseやSunnyです。
これがCTASで、「外部スキーマ」と書いてあるのは、GlueでクローリングしたS3上のJSONファイルです。CSVでも大丈夫です。内部スキーマはRedshiftの中にあります。
中に入れるとクエリ書き放題なんですね。そのまま外部スキーマのまま使ってもいいんですが、中に入れると、さらに集計が速くなったり、あとは何回投げても定額料金、お金かからなかったり、より便利になるという感じですね。
これに関してはあとで興味ある人は聞いてください。今日Redshiftに関してお話しして、10分だったのでわからないこともあったと思いますが、このあと懇親会あるのでいろいろ聞いてください。ありがとうございました。
(会場拍手)
続きを読むには会員登録
(無料)が必要です。
会員登録していただくと、すべての記事が制限なく閲覧でき、
スピーカーフォローや記事のブックマークなど、便利な機能がご利用いただけます。
すでに会員の方はこちらからログイン
名刺アプリ「Eight」をご利用中の方は
こちらを読み込むだけで、すぐに記事が読めます!
スマホで読み込んで
ログインまたは登録作業をスキップ
この記事をブックマークすると、同じログの新着記事をマイページでお知らせします
PR2026.01.19
業務フローを変えずに、メール1通3分を削減 自動でAIにナレッジが貯まる問い合わせシステム「楽楽自動応対」
 PR
PR2026.01.08
入社4年目の社員が“暗黒のExcel時代”を改革 売上金額2倍、年間110万円のコストカットを実現した方法
 PR
PR2026.01.09
上層部の無茶振りと現場の悲鳴の板ばさみ DX推進部がkintoneで叶えた、2,546時間の残業時間削減の道のり
 PR
PR2026.01.14
社員の約3割が離職、売上激減の危機に… コロナ禍の新米社長を救った、kintone活用と会社再生の軌跡
 PR
PR2026.01.15
良かれと思った「完全希望休」で現場は大混乱 創業65年のタクシー会社が“稼げる環境と働きやすさの両立”を実現するまで
 PR
PR2026.01.16
業務が非効率すぎて「ドン引きレベル」 超ネガティブな25歳事務員が挑んだ、“諦める・仕方ない”の逆説のDX成功法則
 PR
PR2026.01.13
Excelへの多重入力、終わらない社内業務… 文系元営業社員が“全社員DX人材化”を実現できたワケ
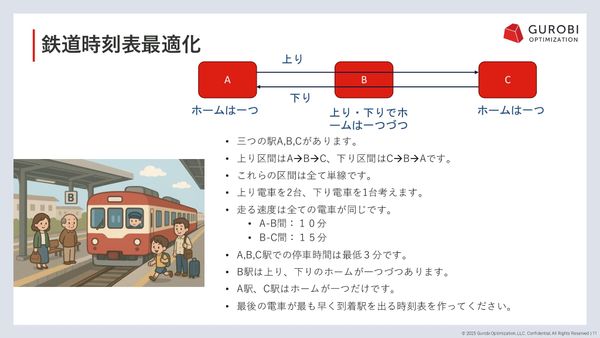 PR
PR2025.12.24
生成AIの進化が「数理最適化」技術の追い風に チャットボットで解くビジネス課題の実践プロセス
 PR
PR2025.12.25
ペペロンチーノの材料調達と配送計画は“同じ問題” 日常とビジネスの意思決定に共通する「アクションの型」とは
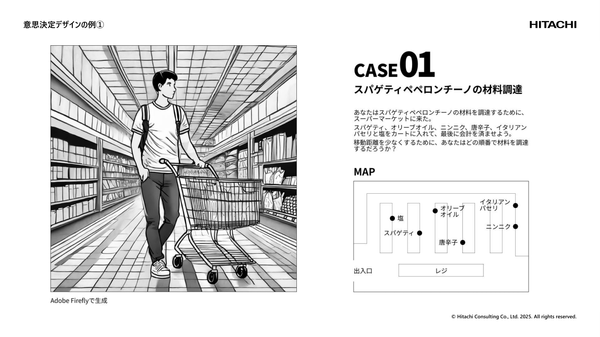 PR
PR2025.12.25
数理最適化で働き方を変える 日立コンサル平井氏の“意思決定デザイン”
PR2026.01.19
業務フローを変えずに、メール1通3分を削減 自動でAIにナレッジが貯まる問い合わせシステム「楽楽自動応対」
PR2026.01.08
入社4年目の社員が“暗黒のExcel時代”を改革 売上金額2倍、年間110万円のコストカットを実現した方法
PR2026.01.09
上層部の無茶振りと現場の悲鳴の板ばさみ DX推進部がkintoneで叶えた、2,546時間の残業時間削減の道のり
PR2026.01.14
社員の約3割が離職、売上激減の危機に… コロナ禍の新米社長を救った、kintone活用と会社再生の軌跡
PR2026.01.15
良かれと思った「完全希望休」で現場は大混乱 創業65年のタクシー会社が“稼げる環境と働きやすさの両立”を実現するまで
PR2026.01.16
業務が非効率すぎて「ドン引きレベル」 超ネガティブな25歳事務員が挑んだ、“諦める・仕方ない”の逆説のDX成功法則
PR2026.01.13
Excelへの多重入力、終わらない社内業務… 文系元営業社員が“全社員DX人材化”を実現できたワケ
PR2025.12.24
生成AIの進化が「数理最適化」技術の追い風に チャットボットで解くビジネス課題の実践プロセス
PR2025.12.25
ペペロンチーノの材料調達と配送計画は“同じ問題” 日常とビジネスの意思決定に共通する「アクションの型」とは
PR2025.12.25
数理最適化で働き方を変える 日立コンサル平井氏の“意思決定デザイン”

