


 PR
PR2025.11.27
数理最適化のエキスパートが断言「AIブームで見落とされがちな重要技術」 1,300社が導入した「演繹的AI」が意思決定を変える
コピーリンクをコピー
ブックマーク記事をブックマーク
俵氏(以下、俵):ちょっと補足情報なのですが、実はこのtimm.create_model で出るやつ(モデル)、このクラスはいろいろ情報を持っています。
1個目がnum_featuresで、たぶんこれを一番使います。CNNの最後のチャネルの数にアクセスできます。resnet18dだと512次元だ、と言っていたやつです。
feature_infoというブロックごとの情報の属性も持っています。ブロックごとの情報ってよくわかんねぇな、と思うかもしれませんが、この最初のブロックはいわゆる、CNNの画像認識モデルとかであのstemと呼ばれるやつ。stem_convと呼ばれる、最初のほうにあるConvolution層を通り抜けた時に、Channelsがなんぼで、その時点で解像度がどれぐらい落ちているかという情報と、Layerの名前が載っています。
その後、resnetの場合だとres_blockと呼ばれるblockが4つ入っていて、それごとの情報が同じようにここに入っています。
もう1個、このdefault_cfgというのも持っていて、これも文字が細かいので見えないかもしれませんが、pretrained modelがどこに入っているかとか、事前学習時の学習条件とかを実は持っています。
たまに使う情報として、最初のConvolution層の名前が何かとか、classfierといった、headの部分の名前が何かという情報が実は入っています。ここらへんを知っていると、たまに役に立つかもしれないです。

というわけで、backboneとして使おうということで、自分でモデルを定義するとどんな感じかをここに書きました。MyImageModelというクラスにしています。
モデルの名前と、pretrainedを使うかどうかと、隠れ層、hidden_dimとout_dimを指定するようにしています。
backboneに関しては先ほど紹介しましたが、「num_classes=0」にして、完全に特徴抽出器として使います。resnet18dだったら512次元のやつが出てくるというふうにします。
何を追加しているかというと、headです。僕は非線形にしたい時は1層のLinearではなく、いったんLinearを通した後に、ReLUを通して、Drooputしてもう1回Linearというふうによくやります。シンプルなMLPをheadとして入れるというのをやっています。
この時にheadの入力の次元を入れないといけないので、backboneのnum_featuresにアクセスしているのがこの部分です。forwardは入力として画像が入ってきたら、まずself.backboneでfeatureを取り出した後に、headを適用して、出力を返すようになっています。
こんな感じで、多くの人は定義時にnum_classesをタスクに合わせたクラス数にするよりは、こういう感じでbackboneとheadを自分で定義して作っている場合が多いんじゃないかと思っています。公開Notebookとかでも、よくこういうモデルの定義の仕方をしている気がします。

その他、ちょっとだけ補足情報として。自然画像ではないデータに使いたい時があると思います。例えば白黒画像だったらチャネルが1だし。ここで言っている細胞画像というのは、ちょっと前にKaggleであったHuman Protein Atlasなどの、純粋な自然画像ではないのでチャネルが4つあります、みたいなパターンとか。あとは、音声とかをメルスペクトログラムに変換したチャネルが1ですよ、などそういう時です。
「それってPretrained Model使いにくいんだなぁ」「だよなぁ」みたいに思うのですが、timmは、in_channelsの引数を指定するだけでいいんですね、メチャクチャお手軽。しかもきちんとPretrained Weightを使ってくれます。
(スライドを示して)右の例で、「in_chans=1」を指定すると、Batch Size、Channel、Height、WidthはChannelの部分を1にしていてもきちんとforwardができます。
今度は7に指定した場合です。入力Channelを7にしていますが、どちらもきちんとforwardが通って、1,000次元の出力ができています。本当にお手軽ですよ。ここを指定するだけでよいです。
人によっては「いや、これどういう仕様になってんねん」と思うかもしれませんが、1の時はもとの3用のfilterの合計値がConvolution層のfilterとして使われています。
1と3以外の時は、R、G、B、R、G、B、Rというように、順番に並べる仕様になっています。おもしろいことに、そういう仕様になっています。ちなみに値の大きさ自体は、合計値がうまいこといくようにスケールされるという仕組みです。

その他、今回はちょっとややこしい話なので軽く紹介だけしますが、複数のfeature mapを取り出したい場合には「features_only=True」とすると、先ほどfeature_infoという属性が取れることを紹介しましたが、あそこで言われていた5つが出てきます。
out_indicesで指定すると、今ここで2と4を指定していますが、0、1、2、3、4の2と4が下で取れているのが確認できると思います。
それと、これも完全に余談なのですが、Grobal Pooling系も実はAverageだけではなくてmaxとかavgmaxを指定できるのが、仕様上あります。ただ、僕はあまりAverage以外は使わなくて、ちょっとよく知らないので、使ってみて確認してほしいなと思います。

最後の話題ですが、ではどのモデル使いますか? というところです。これもtimm.list_modelsで一覧を見ることができます。「Pretrained=True」すると、Pretrained Modelがあるものだけ確認できます。
最初のほうで紹介しましたが、現段階で612種類、Pretrainedありは452種類と、メッチャクチャあります。ちなみに僕は、先ほどvovnetというモデルを見て「え、このモデル知らねえ」となりました。

ではどうやって選ぼうというところですが、1個目の情報として、まずtimmのレポジトリ内には、ImageNet Classification Taskに対する結果というのが全部まとまっています。
たまに追加されていないモデルもあるのですが、top1 accuracyとかtop5 accuracyとか、これも文字が小さいですが、パラメーターの数がどれぐらいとか、そういう情報が載っています。ちなみに僕はこのページをブックマークしています。
これを見て「では性能順に試すか」というとそんなことはありません。1番上のモデルは重すぎて、個人で学習するのはけっこうキツいし、これはあるあるなのですが、数値上のパラメーター数は少ないけど学習するとメッチャGPUのVRAM食うやんけみたいな、EfficientNetとかね、あったりして。なので、この表だけでは正直わからんとなると思います。

では結局どうなの? という話なのですが、ここでやっと分析コンペLTっぽいことを話します。いろいろなモデルをいたずらに試しても、結局時間がかかるだけかなと思っています。コンペのタスク次第ですが、大きいモデルだからいい性能が出るとも限りません。
あとはよくある話として、前処理とか後処理とか、別の工夫のほうが決め手になることが、往々にしてあります。
やはり自分の中でベースモデルを決めて、改善していって、最後のほうで「ちょっと大きいモデルも試してみるか」とやるのが、一番進め方としてはよいのかなと思います。
でも「どのモデルがいいねん」と思うかもしれません。個人的には最近はResNet-D系が好きなのでよく使っています。Solutionだと、EfficientNetをよく見かけます。
本当に最近のSolutionだと、ViT系がSolutionに現れるようになったと思っています。先日(※取材当時)のCOVIDのObject Detectionだと、3位を取られた日本の方は、Swin Transformerを使っていましたよね。

というところで、まとめです。まずtimmの紹介をしました。さまざまなモデルが実装されていて、しかも事前学習モデルもメチャクチャたくさんあって、更新も頻繁だし、本当にすごいやつですね。ただ僕、最近こいつに頼りすぎていて自分の実装力が落ちているなとちょっと感じています。
使い方を簡単に紹介しましたが、create_modelですごく気軽に呼び出せるし、pretrained modelも読み込めます。引数の指定によって、カスタムもしやすいです。
コンペでどのモデルを使うかという話もしたのですが、modelはすごくたくさん提供されているので、あまりいたずらに試すよりは、やはり自分の使うベースモデルを決めて改善していったほうが絶対いいかなあと思っています。ただ、さまざまなコンペで大概強いSolutionが出てくるので、そういうのはあとから試すのがよいのかなと思っています。

参考にしたところとして、公式レポジトリと公式のdocs、あともう1個、公式以外にfastaiの人が作っているのかな?docsが実は存在しています。なぜかこのdocsに、in_chansを3以外にした時の仕様が載っています。これは公式には載っていないので、本当になぜ載っているのだろうなという感じでした。以上で発表終わりです。ありがとうございました。

司会者:ありがとうございました。俵さんの調査力が半端ないというか、すごかったです。俵さんはこの資料は自分で作られたのですか?もともと知っていたネタをまとめたという感じなのでしょうか?
俵:そうですね。わりと知っていましたね。ちょっと前に調べていたことが多いかな。timmを使い込んでいる人だとけっこう知っている情報だと思うので、初心者の人には有用な情報かなという気はしています。
司会者:でも本当に、助かりますね。インプットのチャンネル数を変えられるとか、そういうのもぜんぜん知らなかったので「ああ、そういうことができるんだなあ」と。backboneに使う時のやり方とか知らなかったので、やはり画像勢の方はすごいなという感じですね。
俵:頼りきりすぎるとtimmにあるモデルしか使えなくなるので(笑)。最新の論文のやつを使いたかったら、公式の実装を見にいって、それをフォークしてくるとかはやりますね。
司会者:そうなのですね。でもtimmにもどんどん追加しているというのがすごいですよね。
俵:本当ですよ。本当にメッチャクチャ更新を頻繁にされているので、何者なのだろうなって気がしますね。お世話になりすぎていて、本当に最近GitHubスポンサーズでお金落としたほうがいいかなって気持ちになっているんです。
司会者:timmの作者にGithubスポンサーズで課金はできるんですかね。
俵:すみません、ちょっと詳しい仕組みはわかっていないのですが、できるのかなあって思っています。
司会者:いやあ、timmも本当ありがたいですね。タイムラインでも、timmがあるからPyTorchを使っているという方が何人もいました。
俵:ふふふ(笑)。本当にすごいですね。
司会者:それではいったんここで終わりたいと思います。ありがとうございました。
俵:ありがとうございました。
続きを読むには会員登録
(無料)が必要です。
会員登録していただくと、すべての記事が制限なく閲覧でき、
スピーカーフォローや記事のブックマークなど、便利な機能がご利用いただけます。
すでに会員の方はこちらからログイン
名刺アプリ「Eight」をご利用中の方は
こちらを読み込むだけで、すぐに記事が読めます!
スマホで読み込んで
ログインまたは登録作業をスキップ
この記事をブックマークすると、同じログの新着記事をマイページでお知らせします
PR2025.11.27
数理最適化のエキスパートが断言「AIブームで見落とされがちな重要技術」 1,300社が導入した「演繹的AI」が意思決定を変える
 PR
PR2025.11.28
「あの人がいなくなったら仕事が回らない」を解決 属人的な業務から脱却する「最適化」の実践方法
 PR
PR2025.11.28
「計画と運用」をごちゃ混ぜにすると崩壊する ビジネスに使える最適化システムの“境界線”の引き方
 PR
PR2025.11.27
9割がリピーターでも“飽きられない”仕掛け 馬渕磨理子氏×オリエンタルランドが語る、体験価値と「成長の3本柱」
 PR
PR2025.11.28
“テーマパークの外”への挑戦で売上1兆円を目指す 馬渕磨理子氏が迫る、オリエンタルランドの新領域戦略
 PR
PR2025.11.28
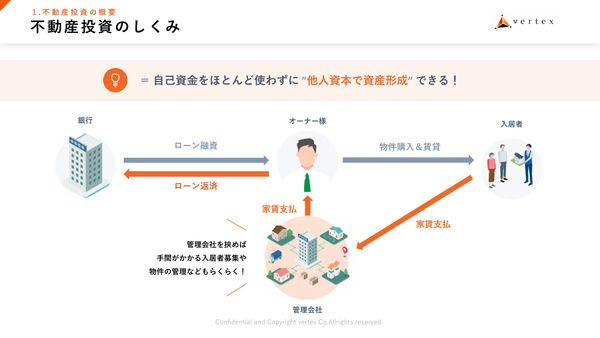
物価上昇時代の“もう1つの収入源” 自己資本約10万円から始められる、不動産投資の仕組みとリスク解説
 PR
PR2025.11.27
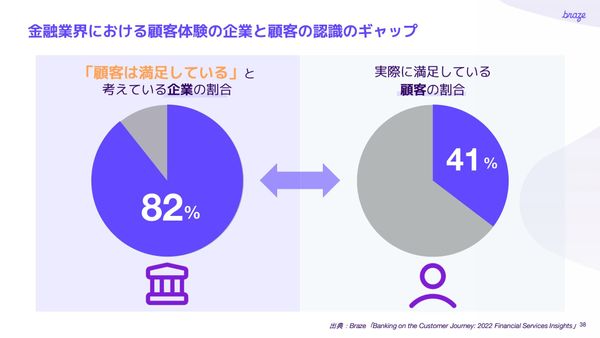
AIで激変する顧客体験──「金融機関」と「消費者」の関係を再設計 Brazeが描く“真の顧客エンゲージメント”とは
 PR
PR2025.11.28
金融機関の休眠顧客をアクティブユーザーへと転換 Brazeが提供する、収益改善を実現する「パーソナライゼーション」事例
 PR
PR2025.11.28
管理職に求めすぎる組織の限界 役割分割で生まれる新しいチーム運営
 PR
PR2025.11.27
「考えろ」と言うだけの上司が組織を壊す 自律型人材が育たない本当の理由
PR2025.11.27
数理最適化のエキスパートが断言「AIブームで見落とされがちな重要技術」 1,300社が導入した「演繹的AI」が意思決定を変える
PR2025.11.28
「あの人がいなくなったら仕事が回らない」を解決 属人的な業務から脱却する「最適化」の実践方法
PR2025.11.28
「計画と運用」をごちゃ混ぜにすると崩壊する ビジネスに使える最適化システムの“境界線”の引き方
PR2025.11.27
9割がリピーターでも“飽きられない”仕掛け 馬渕磨理子氏×オリエンタルランドが語る、体験価値と「成長の3本柱」
PR2025.11.28
“テーマパークの外”への挑戦で売上1兆円を目指す 馬渕磨理子氏が迫る、オリエンタルランドの新領域戦略
PR2025.11.28
物価上昇時代の“もう1つの収入源” 自己資本約10万円から始められる、不動産投資の仕組みとリスク解説
PR2025.11.27
AIで激変する顧客体験──「金融機関」と「消費者」の関係を再設計 Brazeが描く“真の顧客エンゲージメント”とは
PR2025.11.28
金融機関の休眠顧客をアクティブユーザーへと転換 Brazeが提供する、収益改善を実現する「パーソナライゼーション」事例
PR2025.11.28
管理職に求めすぎる組織の限界 役割分割で生まれる新しいチーム運営
PR2025.11.27
「考えろ」と言うだけの上司が組織を壊す 自律型人材が育たない本当の理由

