



 PR
PR2025.11.27
数理最適化のエキスパートが断言「AIブームで見落とされがちな重要技術」 1,300社が導入した「演繹的AI」が意思決定を変える
コピーリンクをコピー
ブックマーク記事をブックマーク
笹原和俊氏(以下、笹原):画像生成AIやディープフェイクが出てくると、当然、フェイクニュースに利用しようという人たちも現れてきます。
これは日本で起こったことですが、静岡で水害があった時に、「ドローンで撮影された様子です」といって、実際に画像生成AIで作った偽画像のツイートが出ました。ものすごく拡散したということではないんですが、ある程度拡散しました。

もし、本当に災害が起きた時にこういうフェイクニュースが流れると、混乱が生じるわけですね。画像生成AIを使うと、数十秒待てば、誰でもこういったものが作れちゃうような時代ですので、フェイクの高度化・大量化が懸念されます。
これまで、機械学習を使ったAIというのは、どちらかというと「識別タイプ」のモデルが多かったんですね。入力があって、学習して、「ある入力はこちらのクラス、ある入力はこのカテゴリー」というふうに、分類するように学習するタイプが多かったんです。
今のAIは(「生成モデル」)。生成AIの「生成」はここから来ているんですが、もともと訓練に使ったデータの特徴を備えた、新しいデータを生成することができるモデルになっているんですね。

入力の前に「確率分布」というある種のモデルがありまして、元の訓練データとそっくりな新しい画像を作ること、データを生成することができる。これが「生成モデル」と言われるものです。
例えば、こういうオートエンコーダみたいに、猫画像を入力して、これと同じ猫画像をもっと少ないユニットで表現できるようにトレーニングすると、実はこのローデータがある知識表現に圧縮されて、これをもとに同じ猫を再現することができるようになる。

こういうことをすると、その画像の特徴を抽出できるようになるんですね。これは一例ですが、こんなふうにして、今のAIはもともとのデータから特徴を抽出して、それを使って画像なり文書なりを生成できるようになっているんですね。
笹原:特にディープフェイクで使われる重要な技術の1つが、「GAN」というやつです。これはGenerative Adversarial Networks、敵対的生成ネットワークと言います。

「生成器」と「識別器」という2つのモジュールがあるんですが、この生成器というのが、あたかも贋作を作る“詐欺師”のような働きをして、どんどん偽物を作っていく。“鑑定士”の識別器のほうは、作られたものをできるだけ見抜けるようにして、お互いに競い合って学習するんですね。
そうすると、最終的には本物か偽物かが見分けがつかないような、本物っぽい画像が生成できるようになるというアーキテクチャーになっています。これは、ディープフェイクの初期のアーキテクチャーとしてよく使われたものです。
その後に、「Stable Diffusion」のような、いわゆる拡散モデルと言われる、また別のタイプのアーキテクチャーの機械学習が出てきました。今日は触れませんけれども、本書で詳しく説明していますので、そちらについてはぜひ読んでいただければと思います。
例えばCycleGANを使うと、馬をシマウマにするという「スタイルの変換」は、ものすごく簡単にできてしまいます。
簡単になったとはいえ、これまでの画像生成AIは、プログラミングだったりコンピューターの知識が必要でした。しかし、今の画像生成AIは、言葉がUI(ユーザーインターフェース)になっているんですね。
だから、言葉によって指示を与える。これを「プロンプト」と言います。私たちの誰もが使える言葉で指示を与えると、それっぽい画像ができる。
例えば、OpenAIが発表している「DALL・E 2(ダリ2)」とか、「Midjourney」。それからこれはオープンソースですが、Stability AIが発表している「Stable Diffusion」。こういった、新しいタイプの画像生成AIが出てきました。まさにこれが、現在の脅威になっているわけです。
笹原:例えば、私の研究室の大学院生が、「FBI organized January 6 Capitol Riot」(FBIが1月6日連邦議会議事堂襲撃を組織)というプロンプトをStable Diffusionに入れて、30秒ぐらい待つわけです。そうすると、本当に議事堂を襲撃しているかのような偽の画像が、このリアリティでできてしまいます。本当に起こっているかのような画像ですよね。

ただ、ちょっとおかしな点があります。みなさんお気づきだと思うんですけれども、(画像右下に)「FIB」と書いてあるんですね。もちろん「FBI」という組織はありますけど、「FIB」という組織はないと思うんです。
少なくとも、このStable Diffusionはそういうことは知っていなくて、今のAIは、時々人間では起こさないような間違いも平気で起こしたりする。
よく「(AIは)人間の脳を模倣している」と言うんですが、そうではなくて。人間とは違ったかたちで、でも、こういう知識を何らかのかたちで自分の中に構造化・組織化している。それが現在のAIだと思います。
ちょっと時間がなくなってきたので、ChatGPTのお話に移っていきます。これも、いわゆる生成系AIの一部なんですが、まさに今、日々新しいサービスが生まれているAIです。
実際にChatGPTに「ChatGPTとは何ですか?」と、尋ねてみました。そうすると、「ChatGPTはOpenAIによって開発されました」「2021年9月までの知識がありますよ」「いろんな質問に答えられますよ」と、ものすごく的確に答えてくれます。
(ChatGPTは)こんなふうに対話に特化したAIですね。自然言語がUIで、対話することができるとか、これまでのWebの集合知を学習しているところに特徴があります。
笹原:実際に、ある研究グループは、ChatGPTを活用して、2時間で論文を執筆したというアナウンスもありました。これは今、査読中ですね。それから中国では、ChatGPTから生成されたニュースが出回ってしまって、フェイクニュース騒ぎが起こったりもしています。
ChatGPTを使った大規模なトラブルやフェイクニュース案件は、まだそこまで出てきていないんですが、これから「ChatGPT×画像生成AI×SNS」ということになると、コンテンツを簡単に作れる。
それを容易に拡散するようなプラットフォームもあるということで、偽ニュースの量産だったり、SNS上で振る舞うような偽のペルソナが現れて、より深刻なフェイクニュースの事件が生じかねないという可能性があります。

この後、質問のコーナーでもおそらく出るかなと思うんですが、ChatGPTに“目”や“手足”、つまりセンサーとかモーターがついた時に、本当の脅威になるのかなと感じています。
今のChatGPTは、あくまでも過去の情報しか参照できないので、センサーやモーターで今の情報が取れるようになった時には、もっと怖いことが起こるのかなと想像しています。
ChatGPTや生成系AIをどういうふうに使っていけばいいのか。これは、大学でもいろいろな立場に分かれています。
笹原:これは本学、東京工業大学の例ですが、我々はどちらかというと「(生成系AIを)積極的に使っていきましょう」という立場をとっていますし、教育担当理事の方もそのようにおっしゃっています。

ここが特に重要だなと思っていて、「学生のみなさんの主体性を信頼し、良識と倫理感に基づいて生成系AIを道具として使いこなすことを期待します」と。そうじゃないと、みなさんがAIに隷属することになりますよ、ということを言っています。
ですので、どういうふうにこういうツールを使っていけばいいのか、どんな問題があるのか。まだ未知なところがありますけれども、できるだけクリエイティブな使い方をしていきたいと思っています。
ディープフェイクは必ずしも負の側面ばかりではなくて、リアルタイム性が高いもの、それから複雑性が高いものに対して、効果的にクリエーションを可能にするツールです。もちろん、ビジネスの文脈でもポジティブな効果をもたらすことは大いに考えられます。

同時に、ディープフェイクの弊害も考えておかなければいけないわけなんですが、インフォカリプス(情報の終焉)に向かわないように、つまり、トラストが失われた、何も信頼できないような世界に向かわないようにしなきゃいけない。
笹原:本物のような偽物が出回り、実害が生じる可能性を下げたいですし、本物と偽物の区別がつかない環境では、偽物を作っているほうこそが得をするという状況も生じがちです。これを「嘘つきの配当」と言うんですが、こういうことにも気をつけなければいけません。

そして何よりも、不確かなUser Generated Content(ユーザー生成コンテンツ)、およびAI Generated Content(AI生成コンテンツ)が混ざるような状況が生じますので、情報生態系が汚染される。我々が住んでいる情報生態系が汚染されることもありますので、それも潜在的な弊害の1つかなと思います。
我々はフェイクメディアに関する研究を続けていて、実際にディープフェイクを見抜くような技術も作っているところです。
執筆の裏話をちょっと述べて終わりにしたいと思うんですが、実はいろいろ苦労をしました。Stable Diffusionが出るまでは本当に書けなくて、なかなか苦労したんですけれども、その話題が出てから、わりと自分で考えてたことがまとまり始めて、一気に書けたところがあります。

この執筆を終えた2022年の大晦日、まさかChatGPTがここまでになるとは思ってなかったというのも、科学者として正直な感想です。ということで、ぜひみなさんご興味がありましたら、本書(『ディープフェイクの衝撃 AI技術がもたらす破壊と創造』)を手に取っていただければと思います。私からは以上で発表を終わりたいと思います。
続きを読むには会員登録
(無料)が必要です。
会員登録していただくと、すべての記事が制限なく閲覧でき、
スピーカーフォローや記事のブックマークなど、便利な機能がご利用いただけます。
すでに会員の方はこちらからログイン
名刺アプリ「Eight」をご利用中の方は
こちらを読み込むだけで、すぐに記事が読めます!
スマホで読み込んで
ログインまたは登録作業をスキップ
この記事をブックマークすると、同じログの新着記事をマイページでお知らせします
PR2025.11.27
数理最適化のエキスパートが断言「AIブームで見落とされがちな重要技術」 1,300社が導入した「演繹的AI」が意思決定を変える
 PR
PR2025.11.28
「あの人がいなくなったら仕事が回らない」を解決 属人的な業務から脱却する「最適化」の実践方法
 PR
PR2025.11.28
「計画と運用」をごちゃ混ぜにすると崩壊する ビジネスに使える最適化システムの“境界線”の引き方
 PR
PR2025.11.27
9割がリピーターでも“飽きられない”仕掛け 馬渕磨理子氏×オリエンタルランドが語る、体験価値と「成長の3本柱」
 PR
PR2025.11.28
“テーマパークの外”への挑戦で売上1兆円を目指す 馬渕磨理子氏が迫る、オリエンタルランドの新領域戦略
 PR
PR2025.11.28
物価上昇時代の“もう1つの収入源” 自己資本約10万円から始められる、不動産投資の仕組みとリスク解説
 PR
PR2025.11.27
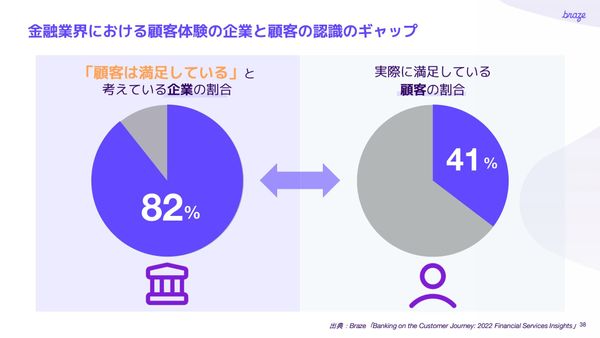
AIで激変する顧客体験──「金融機関」と「消費者」の関係を再設計 Brazeが描く“真の顧客エンゲージメント”とは
 PR
PR2025.11.28
金融機関の休眠顧客をアクティブユーザーへと転換 Brazeが提供する、収益改善を実現する「パーソナライゼーション」事例
 PR
PR2025.11.28
管理職に求めすぎる組織の限界 役割分割で生まれる新しいチーム運営
 PR
PR2025.11.27
「考えろ」と言うだけの上司が組織を壊す 自律型人材が育たない本当の理由
PR2025.11.27
数理最適化のエキスパートが断言「AIブームで見落とされがちな重要技術」 1,300社が導入した「演繹的AI」が意思決定を変える
PR2025.11.28
「あの人がいなくなったら仕事が回らない」を解決 属人的な業務から脱却する「最適化」の実践方法
PR2025.11.28
「計画と運用」をごちゃ混ぜにすると崩壊する ビジネスに使える最適化システムの“境界線”の引き方
PR2025.11.27
9割がリピーターでも“飽きられない”仕掛け 馬渕磨理子氏×オリエンタルランドが語る、体験価値と「成長の3本柱」
PR2025.11.28
“テーマパークの外”への挑戦で売上1兆円を目指す 馬渕磨理子氏が迫る、オリエンタルランドの新領域戦略
PR2025.11.28
物価上昇時代の“もう1つの収入源” 自己資本約10万円から始められる、不動産投資の仕組みとリスク解説
PR2025.11.27
AIで激変する顧客体験──「金融機関」と「消費者」の関係を再設計 Brazeが描く“真の顧客エンゲージメント”とは
PR2025.11.28
金融機関の休眠顧客をアクティブユーザーへと転換 Brazeが提供する、収益改善を実現する「パーソナライゼーション」事例
PR2025.11.28
管理職に求めすぎる組織の限界 役割分割で生まれる新しいチーム運営
PR2025.11.27
「考えろ」と言うだけの上司が組織を壊す 自律型人材が育たない本当の理由

