生成AIを活用して、接客データをビジネスに結びつけようと画策する、スポーツ用品販売大手の株式会社アルペン。生成AI利活用にはさまざまな失敗があったと語りましたが、その課題をどう乗り越えたのか? 「Cybozu Days」で、kintone導入と合わせて生成AIを使いこなすための施策が聴衆に明かされました。データドリブンな組織づくりのコツ、人材育成の方針は? さまざまな試行錯誤の末に学んだ教訓が語られました。
アルペン、生成AI活用で重ねた試行錯誤
小島雄一朗氏(以下、小島):ここから後半はこの課題をどう乗り越えてきたのかをお話ししていきたいと思います。さまざまな試行錯誤の末、現在採用した検証中のモデルをご紹介したいと思います。こちらも中澤さん、よろしいですか。
中澤洋之氏(以下、中澤):また技術的なお話になってしまうんですが、ベクトル検索と全文検索に適した質問があります。なので、まずユーザーから質問がきた時に、質問の内容がどっちに適しているのかに1回、AIをかませます。
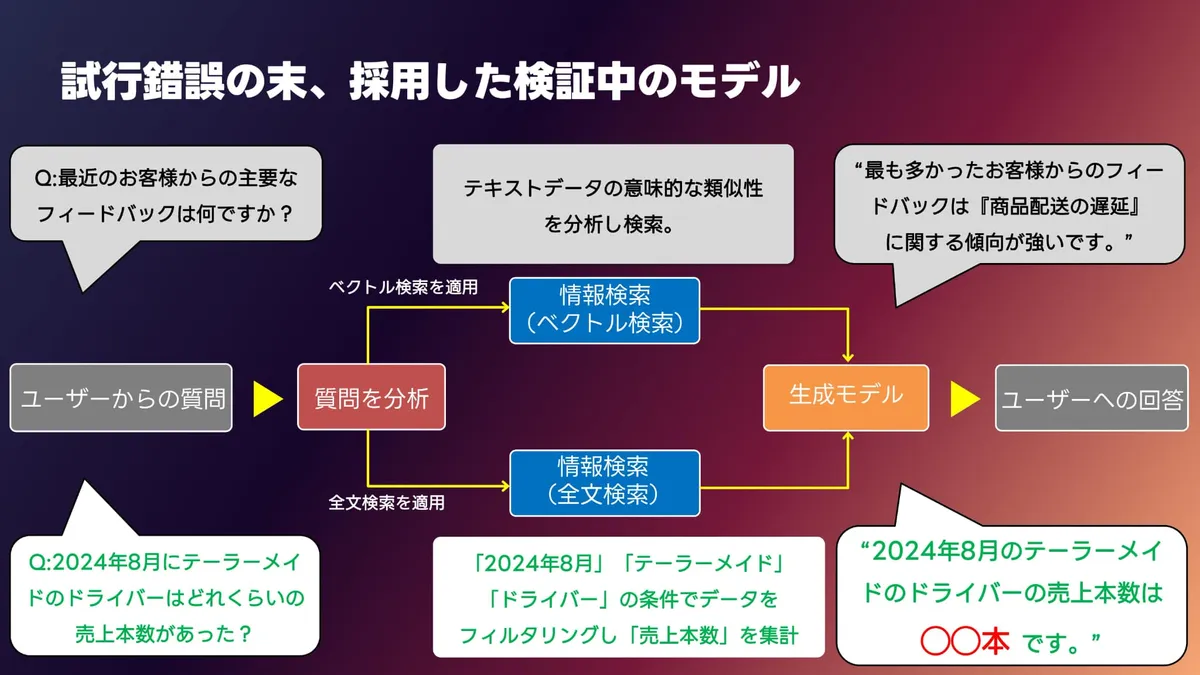
全文検索が向いているものは下、ベクトル検索が適している質問であれば上にいって、それぞれ適したデータを返す仕組みにしています。
小島:2つの検索があることを理解して、使い分ける分析を入れたという。
中澤:そうですね。ユーザーさんはその質問の意図を考えなくても、聞きたいことを聞けば、(AIが)真ん中の赤い部分の「質問を分析する」ところで自動的に切り替えてくれます。
栗山圭太氏(以下、栗山):質問の分析はどの技術を使っているんですか?
中澤:これもAIを使っています。
生成AIの精度をどう上げていったのか?
小島:もう少しだけ時間ありますので、蒲山さん。このあたり、解決策が出てきてどう思われましたか?
蒲山雅文氏(以下、蒲山):もともとChatGPTに代表される生成AIは、基本的には世の中のインターネットに出回っている情報を、都合よく引っ張ってきて解釈をしてくれるものだと思います。当社の基幹系システムの情報を生成AIが知るはずもなく、普通に考えると正しい数字が出るはずもないんですよ。

一方でビジネスで生成AIを使おうとすると、やはりまずはマクロから入っていって、最終的にミクロに落ちていって、最後はお客さまの行動特性・趣味嗜好と合わせながらフィッティングをしていく流れになるので、どうしても最初はマクロから入るために定量的な数字で把握する必要があります。
でも途中からたぶん、「そのクラブはどんな特徴があるの?」「どういう人がたくさん買っているの?」など、定量的なものから定性的なものに質問が変わっていくはずです。
それをこのモデルによってうまくハンドリングをしてくれると、「一番売れているドライバーは何本なの?」と聞いたら、「何万何千何百何十何本」と答えが返ってくるようになりました。このモデルに到達してからは、わりと精度は上がっていった感触はありました。
小島:ありがとうございます。この資料を作っている時、まさにユーザーへの回答の見せ方……グラフがいいのか、表がいいのかなど、この時もアイデアが出てきましたけど、このあたりはいかがですか。
蒲山:当社の基幹系のシステムをAIが全部なめにいって集計をかけると、どうしてもパフォーマンスが落ちてしまう課題にぶち当たりました。中澤さんにその時に「どうしても集計に時間かかりますね」という話をしました。
どうやら時間がかかっているのは集計ではなくて、集計結果を生成AIが言語的な表現としてまとめるところでした。そうであれば出てきた結果をグラフで表現したり、グラフでも遷移や推移と言われたら折れ線グラフにしたり、内訳というキーワードがあったらパイチャートにしたり。
やはりユーザーが欲しいかたちでキーワードに引っかけて、グラフや表など、時には日本語で提案するなり、欲しいかたちでアウトプットがもらえるようにできれば、パフォーマンスは上がるという話はつい先日したばかりですね。
 小島:
小島:中澤さん、これはいけそうですか。
中澤:もちろんです、いけます。
小島:もちろん(笑)。
生成AIは「ハイプ・サイクル」では幻滅期に
栗山:この話とずれるんですけど、ガートナー社のハイプ・サイクル(注:特定の技術の成熟度、採用度、社会への適用度を示す図)があるじゃないですか。「今、流行っています」「廃れました」「幻滅です」というものです。
ハイプ・サイクルでは、生成AIがすでに幻滅期に入っているんですよね。今回アルペンさんのプロジェクトを中澤からいろいろと聞いていると、確かに大変だと思ったんですよ。
今はたぶん結果だけを話しているので「こういうことができるようになりました」と言っているんですけど、もともとアルペンさんは、きっちり作られている「データウェアハウス」があるじゃないですか。あれがスタートしていても、こうやって課題があるということだと思うんですよね。

だから生成AIを企業で使いこなすための要素として、データをしっかりと整備していること、それから頼れる専門家がいること。社内に専門家と話せるレベルの人がいること。とてもハードルが高いなと思いました。蒲山さんは実際にどのようにお感じですか。
蒲山:kintoneのアプリの特性的に、まず「データベースを作ります」「テーブルを作ります」から「業務を設計しながら項目を当てはめていきます」じゃないですか。こうすると部分最適化されたいろいろなテーブルが、アプリごとに作られちゃうじゃないですか。
結局、当社の場合はもともとデータウェアハウスがあったので、あとからkintoneに溜まったデータをデータウェアハウスにフィードバックすればいいという発想になりました。
最初にkintoneから入ってしまうと、データは業務ごとに部分最適されたものとしてとらえてしまいがちなので、どこかのタイミングでこれを一元的に集約してしまわないと、生成AIしかり機械学習しかり、ビックデータの分析しかり、やはり企業の再利用性は上がらないと思っています。
遅かれ早かれ、順番がどっちが先かわからないですけども、最新の技術を入れてデータの利活用のレベルを上げていこうとすると、どうしてもデータウェアハウスみたいな1個の巨大なデータベースの中に、いろいろなデータを集めてくることは価値があることです。
ただ時間がかかることなので、なるべく早くそういう課題にぶち当たっていただいて、時間をかけて丁寧に情報を集めていけば、情報が増えるたびに、生成AIや機械学習のパフォーマンスは上がっていくはずです。
時間をかけてでも、データを統合管理する基盤は作ったほうがいいかなという感覚を持っています。
データ分析できるロールモデルを中心として育成
栗山:でも、我々の提案がフロントシステムとしてのkintoneを中心に提案しているので、裏側のデータウェアハウスの仕組みは、サイボウズの営業からの提案にはあんまり入っていないと思うんですよね。
そこを入れていかないと、企業内で生成AIを使う時に、データがちゃんと整備されていない状態からスタートすることになってしまいます。中澤さん、データウェアハウスの提案をサイボウズの営業に覚えてもらわないといけないんじゃないですかね?
中澤:これから必要になりますよね。
栗山:本当そうですよね。蒲山さんがおっしゃっていた専門的なパートナーと、その専門的なパートナーと会話できる人材。これについてはアルペンさんにはそのレベルの方がもともといらっしゃったんですか。
蒲山:もともと私みたいな一部中途採用がいて、あとは一部データ分析を専門としている部署があるので、そこに少し強い人間がいました。それ以外は基本的に店舗出身者ばかりですね。
栗山:その人たちはやはりだいぶ教育というか、研修をされたんですか?
蒲山:どちらかというとOJTが中心になるので、最低限のことだけ教え込んだ上で、あとは私やマネージャーたちが現場に連れ回していました。
いろいろな課題を聞きながら、それに対するソリューションの提案の現場を見せることによって「次から自分もああなりたい」というロールモデルとして引っ張ってくる育成しかしてきていませんね。

いざ、こういう少し専門的な技術が必要になる知識になってくると、少し弱い部分はあります。そこに関して言えば今回、中澤さんがかなり当社のことを長年知ってくれています。
当社の人材的な特徴もデータ的な特徴もご存知なので、中澤さんに通訳をしてもらいながら、なんとかこぎつけた感じですかね。
栗山:なるほど。僕は本当に、店舗の方を引っ張ってくる仕組みがアルペンさんの強みだなと思っていたんですよね。さっきの「仲間のためにがんばる」というモチベーション、業務自体をよく知っていること。そしてkintoneは作るのが簡単と。
なので、これらを合わせることによって成果が出てきました。ここの分野は、たぶんナチュラルには身につかない分野なのかなと思ったので、お聞きしたんですけど。
技術を持った人材の伴走型支援がカギになる
蒲山:先ほどちょうど裏で話したばっかりなんですけど、今回の生成AIはおそらくkintoneが始まって以降、最も高度な技術を要求される部分だろうなと思っています。
もともとユーザー企業でもアプリケーションが作れるのがkintoneの強みとしてありましたけれども、一部JavaScriptを組み込めば、より柔軟なビジネスロジックが作れたりするのも、一方でkintoneの罪でもあります。
当社の場合だと中澤さんみたいなサポートもありますし、昔から当社のことを知ってくれているベンダーさんがkintoneに詳しくなろうとしてくれていたので、おそらくは中澤さんからそちらの方に引き継いでいただいて、これから一緒に育てていくことは必要なんだろうなと思っています。
そういう意味では、kintoneだけだったら店舗出身者でも作れるし、JavaScriptを覚えれば無敵のツールになれると思うんですけど。今回の生成AIに関して言えば、ある程度技術を持った方が伴走型的な支援をやっていったほうが、より良いものが生まれるんだろうなという感覚は持っています。
栗山:けっこうハードルはあるなと思ったんですよね。私はマーケティング本部なので、プロモーションの部隊を抱えているんですよ。kintoneは今まで「簡単、便利、速い」みたいな感じだけで引っ張ってきたんですけど(笑)。この分野をやるんだったら、それだけのプロモーションだとけっこうきついなと思いました。
もう1個はデータウェアハウスの整備や人材などを合わせるとたぶん、やろうと思ったらそれなりに腰を据えて、「やるぞ」と言ってやらないといけない分野かなと思うんですよね。
逆に言うと誰でも簡単にとっかかれるものではないので、手をつけるといわゆる競合他社との差別化にもつながるんだろうなと、今回のプロジェクトを見ながらすごく感じたところではありましたね。
小島:ありがとうございます。さまざまな試行錯誤がありましたので、予定をオーバーしながら盛り上がっていますが(笑)、ここで一度まとめます。
生成AI×kintoneの活用ポイント
小島:今回取り組んでいただいています、アルペンさまのところから得たみなさまへのフィードバックとしまして、kintoneユーザー向けにはどういったポイントがあるのかをまとめていきたいと思います。栗山さん、3点お願いできますでしょうか。
栗山:これは今お話ししたことですよね。あとから考えれば確かに当たり前なんですけども、やはりAIで検索しようと思ったらベクトル検索がセットになってしまっているんですよね。

なので、AIでどういうデータを取り出したいのかをしっかりと考えた上で、検索方式を作っていく必要があるんだろうなと思います。
2点目は、さっき言ったようなデータウェアハウスですよね。やはりデータがしっかりと整備されていないと欲しいデータは取り出せないです。中澤さん、何かありますか? kintoneで活用するためのポイント……これは気をつけたほうがいいみたいな。
中澤:社内でもデータを見ながら気づいたのが、人間が見やすいデータがあるじゃないですか。星をつけてあげて「ここ読んでね」みたいな。kintoneのデータにそういうデータがたくさん入ると思うんですけど、AIにするとすごく厄介なデータです(笑)。
栗山:邪魔なんですね。
中澤:文章中に星(マーク)が入ってきたりするので(笑)。そういったところはたぶん、いろいろなプラグインを使いながら、AIに適したデータに変換するのが必要になるかなと思います。
カリスマ店員のデータ利活用は可能なのか?
小島:このあたりのデータの変換についても、プラグインを出されているパートナーさまがいらっしゃいますよね。
中澤:Smart at AIさんなどがいらっしゃいますね。
小島:今日のブースでも見ていただけますので、データにお困りの方も聞いてください。
栗山:平文でAIが読みづらいデータから、なにかを弾いていってくれるというものでしょうか?
中澤:そうですね。例えばHTMLのタグを弾いたり、変な空白のスペースを取り除いてあげると、AIは扱いやすいデータになりますね。
栗山:なるほど。アルペンさんが今回店舗で使おうとしているデータは、もともとAIが読みやすい形式にはなっていたんですか?
中澤:もうなっていますね。
蒲山:今試しているのは、あくまで定量的なデータが中心なんですよね。数字が中心だし、せいぜい「テーラーメイド」や「ステルス」という、ブランド名や品名ぐらいがテキストなんですけど。
最終的にはこれだけじゃなくて、接客のカルテの中に入っている、過去の提案の履歴を全部解釈してくれると、最強のツールになるんだろうなと思っています。これをやろうとすると、プラグインみたいな話が出てくるんだろうなと思います。
栗山:そこはまだこれからということですね。でも、結局小売店舗なので、カリスマ店員みたいな人がいるんですよね? そのノウハウがみんなで使えれば最高というのは、やはり考え方としてはあるという。
蒲山:誰もが望むけど、誰も今まで実現できていない領域だとは思います。それが少しでも生成AIの解釈する力、伝える力を使って実現できればすばらしいなとは思いますね。
栗山:結局、売上拡大に使いたいということは、そこに手をつけていかないといけないですよね。
蒲山:どこまでいっても効率化には限界があって、長年企業が取り組んできている効率化は、ほぼ行き着くところまで行ってしまっている気がしています。これ以上PLにインパクト与えようとすると、どうしてもトップラインを上げる必要があるので、少しでも売上を上げる施策として何かないかは常に考えています。
カリスマ店員のノウハウに再現性はあるか
栗山:カリスマ店員の知識が使えればいいなと、みんなが考えるわけじゃないですか。過去にいろいろな取り組みがあったと思うんですけど、このあたりはなぜうまくいかないんですかね。
蒲山:100:0で考えると失敗すると思うんですよ。カリスマたるゆえんの中に、再現性のある部分と再現性のない部分がたぶん混ざっていて、なんならその人の人生に基づくようなものたちもあるわけで、それは捨てましょうと。
その人たちがどういうふうにデータを見ているのかということだけだったら、たぶん再現性はあるし、再現できると思うんですよね。なので、標準化して継承できる部分と、標準化を諦めて個性を活かす部分を、しっかり切り分けてあげたほうがいいのかなとは思います。
栗山:確かにカリスマは、たぶん「なぜ自分ができるか」をわかっていない人が多いじゃないですか。だから、その人がどういうデータの見方をしているかという部分だけを切ってみるんですね。
蒲山:それができたら、すばらしいですよね。
栗山:なるほど。そうだったらこの仕組みに乗せやすくはなりますよね。そのチャレンジはこれからでしょうか?
蒲山:これから中澤さんががんばります(笑)。
中澤:やります。
栗山:中澤さんが店舗の方にインタビューしていくことから始めていくんでしょうか?
中澤:そうですね。
栗山:なるほど(笑)。おもしろいですね。
中澤:商談データもありますからね。
栗山:たぶん、みなさんのヒントになると思うんですよね。トップ営業の仕組みは、昔から言われているわけじゃないですか。トップ営業のやっていること、聞いていることを聞いて「みんな真似しましょうね」と。
うまくいったプロジェクトもあると思いますけど、うまくいっていないプロジェクトも多いと思うんですよね。それはどこの部分に再現性があるのかをしっかりと……定量的な部分がいいですよね。
確かに、例えばゴルフクラブのカリスマって、本当に「ゴルフクラブに命かけています」みたいな人を全部コピーできるかといったら、それは無理ですよね。
小島:ありがとうございます。
アルペンの生成AI活用、将来的なビジョン
小島:ではもう少しとなってまいりましたが、最後に蒲山さまより、アルペンとしてのビジョンを教えていただきたいと思います。
蒲山:この先、特に生成AIに期待するところでもあるんですけど。みなさんご存知な方がすごく多いと思いますけども、「データドリブン」という言葉をなるべく現場まで浸透させていくことが、これから先の私のミッションなのかなと思っています。
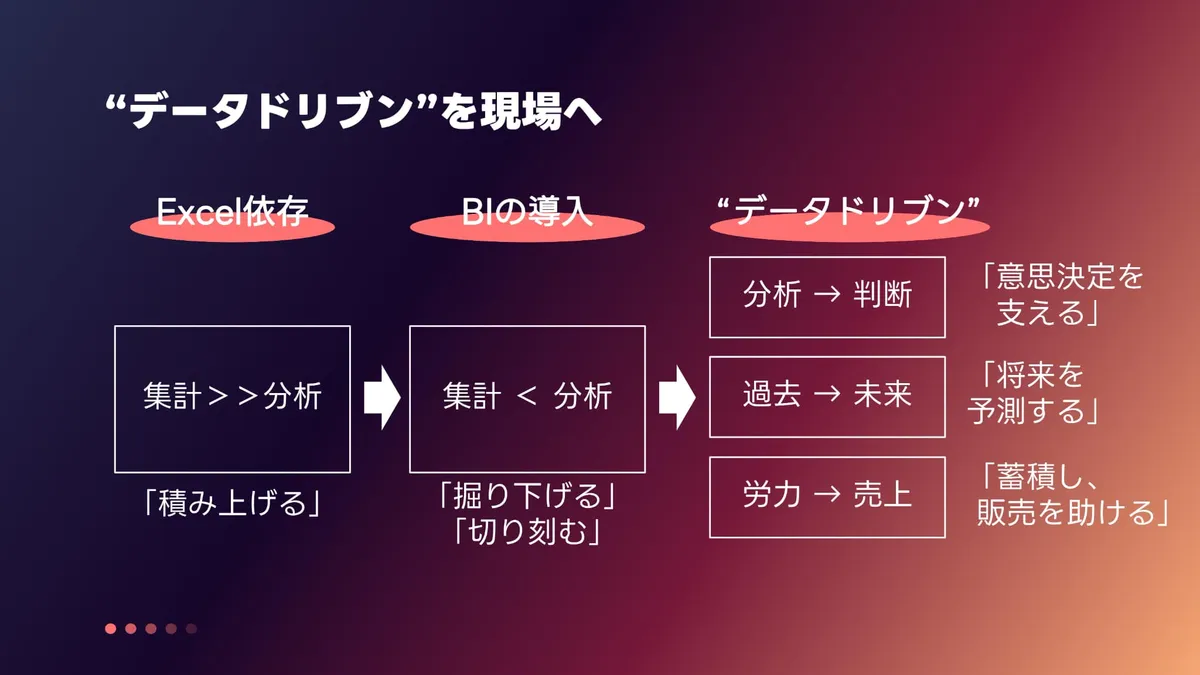
もともとExcelに依存していた時代が6年ぐらい前なんですけど、その頃はデータはひたすら積み上げるものだと言われていました。みんなががんばって集計してきて、一部の役員がレポートとして受けることが、データの主な存在意義でした。
これがビジネスインテリジェンス(BI)という仕組みが入ると、勝手に積み上がっていきます。積み上げたものをさらに逆に深掘りをしたり、スライスして輪切りに切り刻んで、いろいろな角度から物事を見ていくことができるようになってきます。これがBIの導入によって、かなりデータのリテラシーが全社的に上がったというケースです。
とはいえ、これはあくまでも積み上げる作業しかしていなかった人たちが、ようやくデータと向き合えるようになっただけで、データドリブンにはまったくこの中では至っていません。
ちゃんと分析をして、経営が判断できる情報を提供したり、もしくは過去のデータを使って機械学習に食べさせて未来を予測するといったところが本当のデータドリブンだと思っています。ただ、これまで店舗の現場にまでは、まったくこの効果が出なかったんですね。
今回生成AIが定量的なデータと定性的なデータをそれぞれちゃんと扱えるようになると、みんなががんばって蓄積してきた接客のデータなどを生成AIが噛み砕いてくれて、販売を助けられて、売上を上げられます。
ここまで全部入ってくると、本当の意味でデータが経営をドライブする、ドリブンするところが実現できるのかなと思いますので、しばらくはここを目指していきたいなと思っています。
栗山:今のはヒントありましたね。やはりデータドリブンというと、みんな数字をイメージしますよね。数字をイメージして「数字がこうだから、こうしよう」なんですけど。
今のは「日報のデータもデータとして活かしましょう、それが生成AIだとできるようになりました」というお話ですから。今まで以上に営業日報などの記録自体が大事になってきますよね。とてもおもしろかったですね。
小島:それではここまで40分でございますが、アルペンさまの最新の実験・取り組みを活用しまして、AI活用の挑戦についてお送りしてまいりました。本当にありがとうございました。





 PR
PR





 PR
PR PR
PR PR
PR PR
PR PR
PR PR
PR PR
PR PR
PR PR
PR










