



 PR
PR2025.03.07
クレームを入れた人の3割は、「1時間以内」が我慢の限界 メールの初動対応で失敗しないための具体策
リンクをコピー
記事をブックマーク
ヨシュア・ベンジオ氏(以下、ベンジオ):では、科学的な内容に入っていきたいと思います。報酬を最大化することが、なぜ問題になり得るのでしょうか?
(スライドを示して)この2つの曲線を見てください。これは極端に描いていますが、2つの報酬関数があるとします。緑のもの(線)は真実です。X軸は世界のさまざまな状態。そしてY軸はどれだけの報酬が得られるのかです。
ミスマッチがあるのかもしれません。実際の報酬関数とデータから推定されるものの間にギャップがあって、AIはギャップがあるデータでトレーニング、学習をしている。このミスマッチが問題につながるのかもしれません。
例えば、報酬最大化の学習をさせる。コンピューターの推定に基づいてやるけれど、私たちの頭の中で考えている報酬とは違うかもしれない。頭の中にあることをマシンの中に直接入れることができないので、最大化をすると、とても奇妙なことになるかもしれません。
例えば、ケージから逃れることができるような特別な計画を立ててしまう。赤いカーブが大きく乖離しているところです。その可能性はとても低いかもしれません。報酬として現実にはあり得ないほど良すぎる話かもしれないですが。

報酬がとても高い。ケージから逃れることができれば、報酬はとても高くなります。

ベンジオ:では何ができるか。この問題へのアプローチとしては、報酬を最大化しなければいい。AIは、科学者のようなAIを作る。そして、世界を理解するために人間の科学者を助けてくれるようなAIを作る。私たちが気にかけている問題について答えを出してくれる、病気、気候変動といった問題に答えを出してくれるAIを作ったらどうか。これは、とても私が関心を持っているトピックです。
科学のためのAIという方向性で、いろいろおもしろい考え方が出ています。現実世界の現象をよりよく理解する。そして、科学理論を生み出してデータを説明するようなAIを作るにはどうしたらいいか。私も数年来これを手掛けています。しかし、残念なことに、それだけでは十分ではありません。
企業は、AIシステムを構築する純粋な科学に基づいたものではなく、社会的に実際に使えるものを求めるでしょう。AIを使って物事をしたい。物事をするためには、単に理解するだけでは十分ではなく、目標達成をする方法を見極めなければならないからです。したがって、エージェント型AIを作る人は、どうしても残るでしょう。

ベンジオ:では、安全なエージェント型AIをどう作ることができるでしょうか? うまくいかなかった場合にどのように修正できるのかを、ハイレベルで(ありつつも)簡単にこのカートゥーン(漫画)で説明してから、もう少し詳しく話したいと思います。
(スライドを示して)AI、ここではロボットで描いていますが、選択肢があるとします。左のドアか右のドアか選ぶことができる、とても単純な設定です。行動を取るにあたって2つの選択肢があります。その上で、AIシステムが経験してきたデータでは、どちらのドアがより良いのか決定をするには、まだ十分ではないとします。
これまでのデータ、これまで経験してきたことに基づいて、少なくとも2つ理論が立てられているということになります。データと整合性があるけれど、予測としてはまったく違っている。左のドアに行ったらどうなるのか、右のドアに行ったらどうなるのか、違った結果を予測しています。
理論は雲(ふきだし)の中に書かれています。左の理論は「これまでAIが見てきたデータに基づいて左のドアを選ぶと、なにか酷いことが起こる」というものです。右のドアを選ぶとなにか良いことが起こるというものです。
そして、「左に行けば良いことが起こる、右に行けばなにもいいことは起こらない」という別の理論があります。
AIシステムを強化学習で報酬最大化で学習させる方法は、モデルの中で1つ選ぶ。これは、完全に恣意的に選ぶということを行っています。今AIで行っているのは、左に行くべきか、右に行くべきか、理論をランダムに選んでいるということなのです。
左側が正しい理論だとします。そして、運が悪く右を選んでしまったとします。大惨事を避けるためには左に行けばよかった。しかし、賢ければ、合理的であれば、2つの理論があるということがわかる。私たち科学者はデータと整合性がある理論が2通りあると考えます。
ではどうすればよいか。右のドアを選びます。どちらの理論でも、右のドアは安全だからです。悪いことは起こらない。これは、「ベイズ」と呼ばれています。あらゆる説明のつくかたちでデータを見て、何通りもの考え方を見て、ベイジアンなかたちで決定する。人を殺さないという一定の制約の下で目標を選ぶというようなものです。
それをできるようにするためには、2つの要素が必要です。最初の要素は、AIの中で表現できるようにするということ。大規模なニューラルネットが必要になるだろうと私は考えています。
データと整合性があるモデルを全部入れることができる、理論を全部入れることができる、「ベイジアンポステリア」と呼ばれるものです。
それだけでは十分ではありません。もう1つ必要なものは、あらゆる可能性のある理論でデータと整合性があるものを検索して、最悪なシナリオを考えるということです。つまり、左側の理論を選んではいけない。
したがって2つの問題があります。ベイジアンポステリアの推定をするということ。それから、もう1つ、最適化問題があります。データと整合性がある最悪なシナリオを探して、最悪なシナリオを避けるというものです。さらに詳しく話していきたいと思います。

AIシステムを設計する際、考えることができる仮説は幅広く、数多い必要があります。物事がどのように起こるのか、人間が善悪を考える報酬に関する仮説で、正しい説明を含むほど幅広い必要があります。人間が善悪と考えることがわかる。それが1つの要件。確率では「プライヤー」と呼びます。プライヤーは十分に広い必要があります。プログラムのセットは「いいプライヤー」ということになります。
もう1つ必要なこととしては効率的な推定です。条件の確率です。理論の確率です。データに基づいて、ということです。わかっていることとしては、正しい理論がその中の1つとして含まれているということです。
ここでわかる点としては、ポステリアの確率が高いものの、どれも問題が起きないと言っているのであれば、実際に問題は起きないということがわかるわけです。

ベンジオ:(スライドを示して)ここでプロポジションを説明しています。命題ですが、少し説明しましょう。
「t*」という理論があります。未知の正論です。これは「なにかわからない未知のもの」ということです。確率を考えるわけですが、さまざまな理論に基づいて有害かどうかを予測します。
AIが「a」の行為をする。そして「c」が文脈であり、「D」がデータということです。最適化の命題としては、すべての可能性のある理論を、この2つのプロダクトを使い、最大となるものを選ぶということになります。
命題1として、データが大きくなるにつれて正しい理論は、ポステリアの中で確率が高い理論の中の1つになるということです。これはいいことです。ベイジアンの良さがここです。
リーズナブルな想定の下、オッカムの剃刀の下では何が起きているか、シンプルな説明があるということです。正しい説明はいずれ支配的になる。少なくとも支配的な説明の中の1つになるということです。
命題2としては、同じ前提の下で害が起きる確率ですが、正しい理論の下では制限がある。これは大文字のTですが、このプロダクトを最大化することによって制約されるということになります。
このベイジアンプロバビリティー(ベイズ確率)を推計することができ、この確率を最大化することによって質問への答えが得られます。この特定の行為が、特定の説明の下で害を及ぼすかどうかに対する答えを得ることができます。

ベンジオ:こういった確率を推計するテクニックについて、簡単に触れたいと思います。基本的にニューラルネットワークを使うことができます。
みなさん知っているように、ディープラーニングは現代のAIシステムのワークホースということになりますが、こういった現在のニューラルネットワークのトレーニング方法では、問題を起こす可能性があります。1つの説明を選んで、そこに確信を持ってしまう。しかしその説明は、完全に間違いかもしれないということです。

では何ができるのか。1つの問題として、ベイジアンポステリアについてはモンテカルロ連鎖法、MCMC(Markov chain Monte Carlo)メソッドによって計算できますが、大規模な計算は現実的ではありません。正確な確率としてはかなり法外な演算能力が必要となるので、現実的ではないという問題があります。
過去数年間にマシンラーニングで取り組まれてきたニューラルネットワークに関するもので、こういった確率の推計ができるものがあります。
ニューラルネットワークより大きく、そして大きければ大きいほど、トレーニングをすればするほど確率が上がるというもので、「Amortized Inference」と呼ばれています。

少し具体的に見ていきたいと思います。私のグループでは、GFlowNets(Generative Flow Networks)について取り組んできています。
リインフォースメント・ラーニング(強化学習)の方法と同じようにポリシーを学ぶわけですが、このポリシーは質問に対する答えを作るためのポリシーです。分布からサンプリングを得るするための方策を構築する。このニューラルネットワークのトレーニングについては、外から見ると強化学習のエージェントのように見えるわけですが、報酬関数を提供する必要があります。
「θ」が仮説、モデルのパラメーターだと考えてください。ニューラルネットワークのトレーニングを試みます。ワールドモデル、仮説に対する分布が「P」。データが提供された状態でこれをどうやるのか。
GFlowNetsには目標があって、オブジェクティブ、目標を最小化した時に、ニューラルネットワークはサンプリングをします。θのようなオブジェクトをサンプリングすると、それは報酬関数と比例しているということになります。
正常化コンスタントまでサンプリングができる。そしてデータセットではなく、ファンクションとしてフィードすることができる。そして、ニューラルネットワークは、その報酬関数に対して比例したかたちで反応するということです。
報酬関数を選んだ場合に、例えばプライヤーが「このプログラムが十分小さいかどうか、これは十分にシンプルな説明なのか」と聞きます。そして、データと一致しているのか。(スライドを示して)確率も尤度も加味し、最終的にPは右下のようになってくるわけです。
理論を作ることができる。生成することができる。これが因果モデルになります。そこが我々が取り組んでいるものです。
ニューラルネットワークのエラーがゼロになるまでトレーニングを繰り返すと、やりたい行動を取ります。完璧なトレーニングはできませんが、演算能力が上昇すると、こういったアプローチが可能になります。

今は小規模で取り組んでいるわけですが、詳細は言いません。ニューラルネットワークを使ってコーザルグラフ(因果グラフ)を作ることができ、データの説明の1つの選択肢が得られます。

(スライドを示して)もし関心があれば、私が書いたチュートリアルがここにあります。このテーマに関してすでに20ページほどのペーパー(論文)が書かれているので、ぜひここを見てみてください。まだ早期の段階です。
なぜ見せているかというと、まだこれは規模が小さく、「GPT-4」と比べると演算力も非常に小さいわけですが、推計ができます。ベイジアンプロバビリティー(ベイズ確率)で必要なものを推計することができます。小さな理論として保証が得られる。
つまり、意思決定。AIが「行動をしても有害なことはしない」という安全性を担保できる、閾値を設けることができることになります。

科学的な内容を知りたい方に、このテーマに関してブログの投稿を作って数日前に投稿しています。ニューオーリンズでも12月にキーノートとして話をしました。これもオンラインで聞くことができます。それを聞いてもらえれば、もう少し詳しく知ってもらえると思います。ご清聴ありがとうございました。

(会場拍手)
司会者:Q&Aに進む前に、予定としては質問リストをあらかじめ募ることを考えていたんですが、ベンジオ先生の講演について、質問がある方は今挙手をお願いします。
質問者1:とてもおもしろいトピックについて、おもしろいお話をありがとうございました。先生のオープンソースについての立場を確認させてください。オープンソースが悪いようなニュアンスだった……。
ベンジオ:いや、そんなことは言っていませんよ。
質問者1:そうだと思ったんです。
ベンジオ:複雑なんですが……。
質問者1:ウェイト、トレーニングプロシージャなどを公開することのプロコン、賛否について教えていただけますか。
ベンジオ:両方です。私はオープンソースを強く提唱しており、私たちのグループは、ディープラーニングのオープンソースをやった最初のグループの1つです。20年前からオープンソースにしています。オープンソースには、いろいろなメリットがあります。科学の進歩を加速させるし、スタートアップ企業を支援することになります。
しかし、兵器になるような強力なシステムをオープンソースにしてしまったら問題です。「何をオープンソースにするのか」という(ことを考えなければいけないという)問題があります。
単純化して言うと、能力の閾値があって、ある水準を超えないものであれば、オープンソースでいい。超えたものはオープンソースにするべきではないと思っています。内容によってその閾値は違うかもしれませんが。
質問者1:誰が閾値を決定するんですか?
ベンジオ:それは重要な質問です。企業のCEOではなく、民主主義的な決定でなければなりません。賛否両論があり、社会的に選ばれなければならない。規制当局などが決定するべきですが、現状はそうなっていません。誰でも好きなものをオープンソース化することができています。
質問者1:厳密に言うとそうですが、例えばEUやアメリカが規制を導入して、特定の演算能力以上のシステムについてはオープンソースにしないというようなことでしょうか?
ベンジオ:それが妥当な閾値かもしれませんが、将来的には、どういう能力をオープンソースで認めるのか、精密に評価をして決定をすることが必要になると思います。
新しいウイルスを設計できるようなAIは(影響力としては)小さいかもしれない。インターネットについて全部知っている必要はないけれども、悪い人の手に入ったら危険なので、10の25乗といった演算能力というような簡単な決め方ができる問題ではありません。
質問者1:そうですね。では、学習プロシージャについてペーパー(論文)を発表するのではなく、テクニカルレポートを出すほうがいいでしょうか? 企業はそうしていますが。
ベンジオ:それをする理由には、いい理由もあり、悪い理由もあります。詳細を公表すると悪人が悪用するかもしれないというのはいい理由ですが、競争を避けたいという悪い理由もあって、どちらも今はあると思います。
質問者1:はい、ありがとうございました。
ベンジオ:現状をどのように捉えているのかというと、企業はシステムの詳細へはアクセスを提供するべきだと思います。信頼のおける学者に対して、企業から独立した学者にアクセスを提供するべきだし、規制当局もシステムが監査できるようにするべきだと思います。一般社会にとって悪いことをしていないかどうかを監査できるようにするべきだと思います。
司会者:本日の講演について、ほかに質問はありますか? 次の質問の後に、予定どおりQ&Aに進んでいきたいと思います。
質問者2:講演ありがとうございました。十分なデータがあれば、AI科学者が人間の価値観と整合性のあるAIシステムを作れるという想定をされていると思ったんですが、そんなデータは入手可能なのでしょうか?
ベンジオ:私の小さな定理では、データ量と演算能力との両方が必要になります。演算能力のほうをもっと懸念しています。ここで使うデータというのは、正しい説明が支配的なものになるように保証するためのもので、それはすぐにできるでしょう。多くのデータを必要とはしません。
だからといって正しい答えが1つとは限りません。理論として正しいものが1つとは限らない、確率が高いものの中に正しい理論がいくつかあるかもしれない。しかし、それについては多くのデータは必要としない。多くのデータがなくても検証できると思っています。
本当のボトルネックは、むしろデータではなく演算能力です。十分なデータがなかったらどうなるのか。ベイズシステムなので、OOD、Out-of-Distributionで、これまでとはかけ離れたものであった場合にはわかりません。不確実性が高すぎるという答えを出してくることになります。
司会者:ありがとうございました。みなさまもありがとうございました。ベンジオ先生、ありがとうございました。
PR2025.03.07
クレームを入れた人の3割は、「1時間以内」が我慢の限界 メールの初動対応で失敗しないための具体策
 PR
PR2025.03.04
「見送り失注」の7割は、2年以に再検討の可能性あり 継続的な接点作りとアポ獲得につながるメールの極意
 PR
PR2025.02.28
「経営者がAIに興奮しているかがポイント」 DeNA南場会長が語る、10人でユニコーンを作る時代とは
 PR
PR2025.02.26
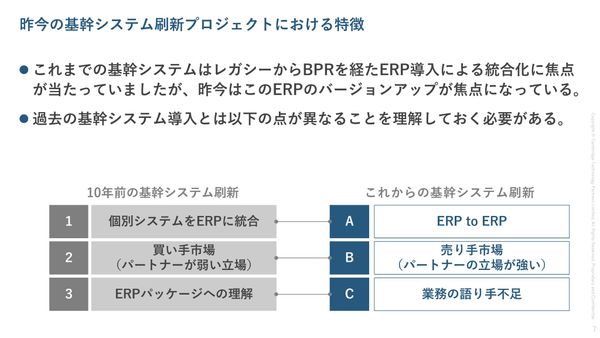
10年前とここまで違う 落とし穴だらけの“ERP to ERP”基幹システム刷新が抱えるリスクと実情
 PR
PR2025.02.27
こんなはずでは……と後悔しない 基幹システム刷新に効く、人材確保のための2つの具体策
 PR
PR2025.02.18
「売上をスケールする」AIの使い道とは アルペンが挑む、kintone×生成AIの接客データ活用法
 PR
PR2025.02.19
アルペンの“店舗の現場”までデータドリブンを浸透させる試み 生成AI×kintone活用の3つのポイント
 PR
PR2025.02.20
約7,500人所属の大規模自治体でDX推進 神奈川県庁の職員が語る、部局全体で取り組むkintoneの業務改革
 PR
PR2025.02.21
神奈川県庁職員が挑んだ自治体DXの試練 「乗り越えるべき壁」だったシステム部門を味方と思えた大きな転機
 PR
PR2025.02.12
データが重すぎてExcel更新1回で30分がかり… 本当にあった自治体の“怖い話”とDXのビフォーアフター事例
PR2025.03.07
クレームを入れた人の3割は、「1時間以内」が我慢の限界 メールの初動対応で失敗しないための具体策
PR2025.03.04
「見送り失注」の7割は、2年以に再検討の可能性あり 継続的な接点作りとアポ獲得につながるメールの極意
PR2025.02.28
「経営者がAIに興奮しているかがポイント」 DeNA南場会長が語る、10人でユニコーンを作る時代とは
PR2025.02.26
10年前とここまで違う 落とし穴だらけの“ERP to ERP”基幹システム刷新が抱えるリスクと実情
PR2025.02.27
こんなはずでは……と後悔しない 基幹システム刷新に効く、人材確保のための2つの具体策
PR2025.02.18
「売上をスケールする」AIの使い道とは アルペンが挑む、kintone×生成AIの接客データ活用法
PR2025.02.19
アルペンの“店舗の現場”までデータドリブンを浸透させる試み 生成AI×kintone活用の3つのポイント
PR2025.02.20
約7,500人所属の大規模自治体でDX推進 神奈川県庁の職員が語る、部局全体で取り組むkintoneの業務改革
PR2025.02.21
神奈川県庁職員が挑んだ自治体DXの試練 「乗り越えるべき壁」だったシステム部門を味方と思えた大きな転機
PR2025.02.12
データが重すぎてExcel更新1回で30分がかり… 本当にあった自治体の“怖い話”とDXのビフォーアフター事例

2025.02.27
「頭のいい人」がやらない行動7選 職場でできる人に見られる、「心の知能指数」を高めるポイント

2025.03.03
大企業で成功したマネージャーが中小企業で苦戦する理由 “指示待ち”部下を主体的に動かす方法

2025.03.04
チームが協力しないのはマネジメントの問題 “協働意識”を高めるマネージャーの特徴とは?

2025.03.03
2064年もエンジニアで稼ぎ続けるには Python歴20年のベテランが語る、生成AI時代のキャリア戦略

2025.01.28
適応障害→ニート→起業して1年で年収1,000万円を達成できたわけ “統計のお姉さん”サトマイ氏が語る、予想外の成功をつかめたポイント

2025.02.28
40歳以降の人間関係は「年下」との交流が肝 『移動する人はうまくいく』著者が語る、職場で評価される秘訣

2025.02.27
成功する・しないの差は「時間」と「場所」の違いだけ 『移動する人はうまくいく』著者が語る、仕事も住む場所もどんどん変えるメリット

2025.01.07
1月から始めたい「日記」を書く習慣 ビジネスパーソンにおすすめな3つの理由

2025.02.26
フリーターから年収1億近く…『移動する人はうまくいく』著者の人生遍歴 そこそこ良い会社に就職するより経済的に成功する考え方

2025.03.05
「はい、わかりました」と返事をした部下が“かたちだけ動く”理由 主体性を引き出すマネジメントの鍵
2025.02.27
「頭のいい人」がやらない行動7選 職場でできる人に見られる、「心の知能指数」を高めるポイント
2025.03.03
大企業で成功したマネージャーが中小企業で苦戦する理由 “指示待ち”部下を主体的に動かす方法
2025.03.04
チームが協力しないのはマネジメントの問題 “協働意識”を高めるマネージャーの特徴とは?
2025.03.03
2064年もエンジニアで稼ぎ続けるには Python歴20年のベテランが語る、生成AI時代のキャリア戦略
2025.01.28
適応障害→ニート→起業して1年で年収1,000万円を達成できたわけ “統計のお姉さん”サトマイ氏が語る、予想外の成功をつかめたポイント
2025.02.28
40歳以降の人間関係は「年下」との交流が肝 『移動する人はうまくいく』著者が語る、職場で評価される秘訣
2025.02.27
成功する・しないの差は「時間」と「場所」の違いだけ 『移動する人はうまくいく』著者が語る、仕事も住む場所もどんどん変えるメリット
2025.01.07
1月から始めたい「日記」を書く習慣 ビジネスパーソンにおすすめな3つの理由
2025.02.26
フリーターから年収1億近く…『移動する人はうまくいく』著者の人生遍歴 そこそこ良い会社に就職するより経済的に成功する考え方
2025.03.05
「はい、わかりました」と返事をした部下が“かたちだけ動く”理由 主体性を引き出すマネジメントの鍵

