


 PR
PR2025.03.07
クレームを入れた人の3割は、「1時間以内」が我慢の限界 メールの初動対応で失敗しないための具体策
リンクをコピー
記事をブックマーク
石上氏:今回は「TensorFlow/PyTorchモデル移植のススメ」というタイトルで発表します。
あらためて自己紹介ですが、私は石上と申します。ハンドルネームは「rishigami」でやっていて、Kaggleでは現在Competitions Masterとなっています。ただ最近はちょっと忙しくて、Kaggleに参加できておらず、つい最近NFLコンペが開催された(※取材当時)ということで、ちょっとそちらに参加していきたいなと思っているところです。
というわけで、発表に移りたいと思います。
突然ですが、こんな悩みはありませんか? 例えば、参考になりそうな論文をアーカイブなどで見つけて、それの実装を見にいくとPyTorchしかなかったり、参考になりそうなKaggleの「notebook」を見つけたんだけれど、それがTensorFlowしかなかったり……ほかにも、こうした場合でも自分で実装はできるんだけれども、例えば大規模事前学習モデルのような、自前で重みを用意するのがなかなか難しいモデルに対して、TensorFlowや、PyTorchしか重みがなかったりする場合が、あるのではないかと思います。
今回の発表を通して、これらの悩みについてご自身で解決できるようになってもらえればと思っています。

というわけで、本日の内容ですが、この4つの項目についてお話しします。
1つ目は、TensorFlow/PyTorchのモデル実装の基礎というところで、TensorFlowは3つの実装方式、それからPyTorchは1つのモデル実装の方式を説明します。
続いて、TensorFlow/PyTorchの比較というところで、TensorFlowとPyTorchの主な違いであったり、あとはレイヤー名の細かな違いを比較してみます。
その次に、Weightを移植する際に必要な重み変換のテクニックを紹介します。
そして最後に、実践TensorFlow/PyTorchのモデル移植というところで、CNN画像認識モデルのVGG16を用いて、PyTorchからTensorFlowにモデルを移植して、重みを移植するという実践編の説明をしていきたいと思います。

それではまず、TensorFlow/PyTorchのモデル実装の基礎から説明したいと思います。
先ほども言ったとおり、TensorFlowではモデル定義の仕方が主に3つあります。ここでは2つ先に説明をします。1つは「Sequential API」、そしてもう1つは「Functional API」という定義の仕方です。
Sequential APIは、はじめにSequentialのコンストラクタを利用して、そこにレイヤーをどんどん追加していく書き方となります。
一方でFunctional APIは、Modelのコンストラクタを利用して、インプットとアウトプットを明示的に定義して、そこで入出力をつなげていって、最後にModel内でインプットとアウトプットを指定する書き方となっています。
このSequential APIとFunctional APIの違いですが、Sequential APIは、このように直感的に追加していくだけのシンプルな書き方で、例えば入力が2種類であったり、出力が2種類のような複数の入出力を持つ場合や、ResNetのようにResidualのコネクションを持つ場合は、なかなか定義するのが難しかったりします。
一方でFunctional APIは、複雑なモデルに対しても定義が可能というメリットがあります。
ここまで2つAPIを説明をしたのですが、TensorFlowの中でもこのような書き方はKeras以来と言えると思います。

続いて説明する「Subclassing API」は、主にTensorFlowの2系からメインで使われるようになった書き方になっています。
こちらは、tf.keras.Modelのサブクラス化によって、このクラスの中(TFCustomModel)で、__init__の中で、レイヤーをまず定義して、callメソッドの中で、そのレイヤーを入力から出力までつなげるという書き方をするものとなっています。
こちらはPyTorchに近い書き方なので、ふだんPyTorchで書き慣れている方も、見慣れたような書き方となっているのではないかと思います。
ここまで、TensorFlowの3つの書き方を説明したのですが、PyTorchでは主にSubclassの書き方が多いと思います。
PyTorchもこの左側のSubclassing APIとかなり似た書き方をします。nn.Moduleのサブクラス化を行って、__init__の中でレイヤーを定義して、forwardメソッドの中で入出力をつなげるという書き方をします。
今回の発表では、このTensorFlowのSubclassing APIと、PyTorchのSubclassの書き方をメインで説明をしていきます。

続いて、TensorFlowとPyTorchの比較ですが、違いを3つ挙げています。
1つ目は、channel lastか、channel firstかという違いです。例えば、2次元の画像のようなデータを扱う際に「バッチ、高さ、横幅、チャネル」の4つの軸があると思います。
こうした場合に、TensorFlowはチャネルが一番最後に来ます。一方PyTorchの場合は、バッチ以降でチャネルが最初に来ます。channel last、channel firstという違いがあります。
この違いによって、例えばモデル移植をする場合にはデータの軸の位置に気をつける必要がありますし、例えばPyTorchなどでもチャネルの位置をきちんと気をつけないと、実装がちょっとバグってしまうこともあると思います。
2つ目は、in featuresの有無です。先ほどレイヤーを定義していったのですが、レイヤーのfeatureの数に関して、TensorFlowはアウトプットのfeatureの数だけを指定すればいいのですが、PyTorchはインプットのfeatureの数も指定しないといけないという違いがあります。
3つ目は、主にモデル移植の際に重要になってくるのですが、hyperparameterの微妙な違いです。BatchNormalizationの2つを比較すると、momentumとepsilonのhyperparameterがそれぞれあるのですが、このoptionalの初期値が、TensorFlowの場合は0.99で、PyTorchの場合は0.1という違いがあります。
けっこう多くの値が違っているのですが、ややこしいのは、TensorFlowのmomentumは、PyTorchでいう、1引く0.01の値を示していて、一方でPyTorchの0.1は、TensorFlowの1引く0.90の値に対応するという違いがあって、実際にモデル移植を行う際のバグの要因となり得る1つかなと思います。
というわけで、ここまで3つの大きな違いを説明してきました。

続いて、TensorFlowとPyTorchのレイヤー名の違いですが、よく使うレイヤーを並べて示しています。左側がTensorFlowで、右側がPyTorchです。
大きな違いは、DenseとLinearという名前の違い。名前は違いますが中身は一緒です。
ほかにも、Conv1DとConv1dは、ラージ「D」かスモール「d」かという違いであったり、Transposeの位置が違ったり、RNNはSimpleが付いたり、BatchNormalizationをNormalizationと略したり、という違いがあります。
ここらへんは慣れてきたらけっこう覚えられるのですが、モデル移植するはじめのほうは、けっこう間違えるので、こういうふうに一覧で覚えておくとかなりわかりやすいのかなと思います。

ここまでTensorFlowとPyTorchの比較を行ってきたのですが、実際に重み変換のテクニック、Tips集を紹介していきたいと思います。
まずは、Weightへのアクセスの仕方の違いというところで、先ほど定義したLinear層、Dense層が3つ連なったモデルについて、Weightのアクセスの仕方を比較してみます。
先ほどの例は、このようにインプットからDense層が3つ連なったモデルとなっています。(スライドを示して)この2つは、同じもの、同じモデル、同じ構造のモデルに対応しているのですが、それぞれのモデルの中で重みを持っているのは、このDense層の3つです。
まずは、左側のTensorFlowの例を見ていきます。TensorFlowの場合は、Weightへアクセスをする時にtf_modelというモデルがあった場合、まずは「.layers」で、各レイヤーを見ていきます。
先ほどの例でいうと、Dense層が3つあるので、3つのレイヤーを見ていきます。その中のレイヤーのweightsを見て、weightの変数を見ていきます。
その変数の中で、例えばnameを指定すると、そのweightの名前が得られますし、「.numpy」で得られるのは、weightの中身ですね。NumPy形式の重みそのものとなります。
ここではshapeを取得しているので、結果としてはこのように、weightの名前と、重みのshapeが得られています。
ここで、1つのdense層に対してkernelとbiasという2種類の重みが入っていることがわかります。

続いてPyTorchの場合、いろいろとやり方があるのですが、その1つとして、torch_model.named_parametersとしてパラメーターを読み込んでいきます。
このパラメーターはタプル形式なので、param[0]が名前、param[1]が重みのテンソルとなっています。
重みのテンソルをNumPy形式に変換するために「detach().numpy()」と、ここではしています。
その結果が以下になります。ほとんどTensorFlowと同じですが、違いとしては、kernelですね。PyTorchでいう、dense1.weightという名前が、TensorFlowでkernelとなっていたり、あとはkernelに関して、軸が0番目と1番目で入れ替わっていたりという違いがあります。biasに関しては名前はbiasですし、shapeも同じで特に違いはありません。
このように、2つの同じ構造を持ったモデルの中で、重みを取り出すことができます。
続いては、TensorFlowからPyTorch、またはPyTorchからTensorFlowにこの重みをどう移植するか、説明したいと思います。
まずは、TensorFlowのモデルの重みをPyTorchのモデルに移植する例を示したいと思います。左側に先ほど取り出した重みの中身を示していて、右側にPyTorchの重みの中身を示しています。
まずは、この左側のTensorFlowの重みを、NumPy形式で取り出します。それぞれ、重みの、tf_names、名前と、tf、重みの、paramsをリストに保存します。
先ほどと同じように、各layer、各weightsから、名前と重みを取り出します。それぞれの名前と、重みの中身をリスト形式で入れます。

続いて、取り出した重みをPyTorchに入れる手順です。ここもいくつかやり方があると思うのですが、その内の1つとして、まずはPyTorchの現状の重みを取り出して、その重みを書き換えて、書き換えた重みを再度読み込むというやり方をしています。
このtorch_model.state_dictによって、現状のPyTorchのモデルの重みを取り出しています。このPyTorchの重みは、上から順に「weight、bias、weight、bias」という順で取り出せます。
そこでkeyとなっているのは、このdense1.weightや、weightごとの名前です。そして、この名前を取り出すのと同じ順番で、左側の先ほど取り出したTensorFlowの重みも取り出します。
ここで「if "kernel"」というif文を使っています。kernelの場合は、軸が0番目か1番目で入れ替える必要があると言ったのですが、そのために、tfのparamsでkernelの場合は、transpose(1,0)と軸を入れ替える操作を行っています。
一方biasはそのまま使えるので、NumPyの重みをテンソル形式で取り出して、それをtorch_params[key]で、torchの重み、weightを直接指定して、そこのデータに入れるという処理を行っています。
ここでfor文で、上から順に重みを入れて、最後に書き換えた重みをもとのモデルに読み込んでいます。
これがTensorFlowからPyTorchへの例です。
続いて、PyTorchからTensorFlowの例ですが、ここもやることは大きく変わりません。まずはtorchのパラメーターと、それからパラメーターのkeyですね、keyは先ほど言ったとおり、weightの名前に対応します。名前を取り出して、各レイヤーごと、そして各重みごとに上から順番にTensorFlowの重みを見ていきます。
torch_keyでリスト形式になっているので、そのリストから1つずつ順番にkeyを取り出して、そのkeyに対応する重みの中身を取り出して、TensorFlowの場合は、各変数に対してassignというメソッドを使うことで、「numpy」という重みを直接入れることができます。
kernelが入っている場合は、ここでも軸を0番目と1番目で入れ替える必要があるので、(1,0)で入れ替えてから、var.assignを行っています。
以上が、PyTorchからTensorFlow、TensorFlowからPyTorchへの重み移植の手順です。

ここまでで、「1番目と0番目を入れ替える必要がある」というような細かい知識が必要となることはわかったのですが、続いてはそのような知識をレイヤーごとに1つずつ紹介していきたいと思います。
まずは、leyers.Dense、nn.Linearです。TensorFlowの場合はkernel、PyTorchの場合はweightに対応して、biasはそのまま同じです。
kernelをTensorFlowからPyTorchに移植する場合は、transposeで1番目と0番目の軸を入れ替える必要がありました。PyTorchからTensorFlowも同様です。

次に、Conv1Dは軸が3つ存在しているので、kernelとweightにそれぞれ対応するのは、「2番目、1番目、0番目」、「2番目、1番目、0番目」というような入れ替えが必要となります。

Conv2Dは4つ軸があって、これが一番間違えやすいのですが、transpose(3,2,0,1)。PyTorchからTensorFlowの場合は、(2,3,1,0)という変換が必要です。2DTransposeは、2Dと同様です。


続いてSimpleRNNです。RNNはなかなかやっかいです。TensorFlowは3つの重みがあって、PyTorchは4つの重みがあります。
kernelは、これまでと同じで1、0を入れ替えるのですが、biasは、TensorFlowが1つなのに対して、PyTorchは2つ存在しているので、不可逆性が発生しています。TensorFlowからPyTorchに移行する場合は、このPyTorchのbias_ih_l0は、すべて0で入れて、一方でもとのbiasはこのbias_hh_l0に入れる必要があります。
反対に、PyTorchからTensorFlowに移行する場合は、bias_ihとbias_hhを足し合わせて、このbiasに入れる必要があるのが、ちょっと注意が必要なところです。

LSTMもRNNと同様で、ちょっと注意が必要です。

続いて、よく使うであろうBatchNormalizationは、4つweightがあって、「weight、bias」が「gamma、beta」に対応していて、あとは追加で、「moving_mean、moving_variance」「running_mean、running_var」という重みが存在しています。

最後にLayerNormalizationは、「gamma、weight」「beta、bias」ということで、軸の入れ替えは特に必要はありません。
先ほどもちょっと触れましたが、モデルを実際に移植する場合に、hyperparameterがマイナス5乗とマイナス3乗であったり、0.1、0.9であったりという違いがあるので、ここも変える必要があります。
確か、transformersのPyTorchのLayerNormalizationは、このTensorFlowのLayerNormalizationに合わせるかたちでハイパーパラメーターが設定されていた気がします。

というわけで、ここまで各レイヤーごとの重み変換のTips集を紹介しました。
(次回へつづく)
PR2025.03.07
クレームを入れた人の3割は、「1時間以内」が我慢の限界 メールの初動対応で失敗しないための具体策
 PR
PR2025.03.04
「見送り失注」の7割は、2年以に再検討の可能性あり 継続的な接点作りとアポ獲得につながるメールの極意
 PR
PR2025.02.28
「経営者がAIに興奮しているかがポイント」 DeNA南場会長が語る、10人でユニコーンを作る時代とは
 PR
PR2025.02.26
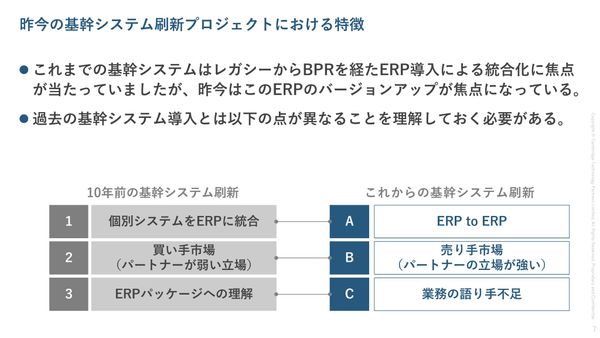
10年前とここまで違う 落とし穴だらけの“ERP to ERP”基幹システム刷新が抱えるリスクと実情
 PR
PR2025.02.27
こんなはずでは……と後悔しない 基幹システム刷新に効く、人材確保のための2つの具体策
 PR
PR2025.02.18
「売上をスケールする」AIの使い道とは アルペンが挑む、kintone×生成AIの接客データ活用法
 PR
PR2025.02.19
アルペンの“店舗の現場”までデータドリブンを浸透させる試み 生成AI×kintone活用の3つのポイント
 PR
PR2025.02.20
約7,500人所属の大規模自治体でDX推進 神奈川県庁の職員が語る、部局全体で取り組むkintoneの業務改革
 PR
PR2025.02.21
神奈川県庁職員が挑んだ自治体DXの試練 「乗り越えるべき壁」だったシステム部門を味方と思えた大きな転機
 PR
PR2025.02.12
データが重すぎてExcel更新1回で30分がかり… 本当にあった自治体の“怖い話”とDXのビフォーアフター事例
PR2025.03.07
クレームを入れた人の3割は、「1時間以内」が我慢の限界 メールの初動対応で失敗しないための具体策
PR2025.03.04
「見送り失注」の7割は、2年以に再検討の可能性あり 継続的な接点作りとアポ獲得につながるメールの極意
PR2025.02.28
「経営者がAIに興奮しているかがポイント」 DeNA南場会長が語る、10人でユニコーンを作る時代とは
PR2025.02.26
10年前とここまで違う 落とし穴だらけの“ERP to ERP”基幹システム刷新が抱えるリスクと実情
PR2025.02.27
こんなはずでは……と後悔しない 基幹システム刷新に効く、人材確保のための2つの具体策
PR2025.02.18
「売上をスケールする」AIの使い道とは アルペンが挑む、kintone×生成AIの接客データ活用法
PR2025.02.19
アルペンの“店舗の現場”までデータドリブンを浸透させる試み 生成AI×kintone活用の3つのポイント
PR2025.02.20
約7,500人所属の大規模自治体でDX推進 神奈川県庁の職員が語る、部局全体で取り組むkintoneの業務改革
PR2025.02.21
神奈川県庁職員が挑んだ自治体DXの試練 「乗り越えるべき壁」だったシステム部門を味方と思えた大きな転機
PR2025.02.12
データが重すぎてExcel更新1回で30分がかり… 本当にあった自治体の“怖い話”とDXのビフォーアフター事例

2025.02.27
「頭のいい人」がやらない行動7選 職場でできる人に見られる、「心の知能指数」を高めるポイント

2025.03.03
大企業で成功したマネージャーが中小企業で苦戦する理由 “指示待ち”部下を主体的に動かす方法

2025.03.04
チームが協力しないのはマネジメントの問題 “協働意識”を高めるマネージャーの特徴とは?

2025.03.03
2064年もエンジニアで稼ぎ続けるには Python歴20年のベテランが語る、生成AI時代のキャリア戦略

2025.01.28
適応障害→ニート→起業して1年で年収1,000万円を達成できたわけ “統計のお姉さん”サトマイ氏が語る、予想外の成功をつかめたポイント

2025.02.28
40歳以降の人間関係は「年下」との交流が肝 『移動する人はうまくいく』著者が語る、職場で評価される秘訣

2025.02.27
成功する・しないの差は「時間」と「場所」の違いだけ 『移動する人はうまくいく』著者が語る、仕事も住む場所もどんどん変えるメリット

2025.01.07
1月から始めたい「日記」を書く習慣 ビジネスパーソンにおすすめな3つの理由

2025.02.26
フリーターから年収1億近く…『移動する人はうまくいく』著者の人生遍歴 そこそこ良い会社に就職するより経済的に成功する考え方

2025.03.05
「はい、わかりました」と返事をした部下が“かたちだけ動く”理由 主体性を引き出すマネジメントの鍵
2025.02.27
「頭のいい人」がやらない行動7選 職場でできる人に見られる、「心の知能指数」を高めるポイント
2025.03.03
大企業で成功したマネージャーが中小企業で苦戦する理由 “指示待ち”部下を主体的に動かす方法
2025.03.04
チームが協力しないのはマネジメントの問題 “協働意識”を高めるマネージャーの特徴とは?
2025.03.03
2064年もエンジニアで稼ぎ続けるには Python歴20年のベテランが語る、生成AI時代のキャリア戦略
2025.01.28
適応障害→ニート→起業して1年で年収1,000万円を達成できたわけ “統計のお姉さん”サトマイ氏が語る、予想外の成功をつかめたポイント
2025.02.28
40歳以降の人間関係は「年下」との交流が肝 『移動する人はうまくいく』著者が語る、職場で評価される秘訣
2025.02.27
成功する・しないの差は「時間」と「場所」の違いだけ 『移動する人はうまくいく』著者が語る、仕事も住む場所もどんどん変えるメリット
2025.01.07
1月から始めたい「日記」を書く習慣 ビジネスパーソンにおすすめな3つの理由
2025.02.26
フリーターから年収1億近く…『移動する人はうまくいく』著者の人生遍歴 そこそこ良い会社に就職するより経済的に成功する考え方
2025.03.05
「はい、わかりました」と返事をした部下が“かたちだけ動く”理由 主体性を引き出すマネジメントの鍵

