


 PR
PR2025.11.27
数理最適化のエキスパートが断言「AIブームで見落とされがちな重要技術」 1,300社が導入した「演繹的AI」が意思決定を変える
新規事業でもマイクロサービスに挑戦する(全1記事)
提供:Sansan株式会社
コピーリンクをコピー
ブックマーク記事をブックマーク
加藤耕太氏:こんにちは。加藤です。今日は『新規事業でもマイクロサービスに挑戦する』というタイトルでお話しします。マイクロサービスアーキテクチャについてご存知の方は、新規サービスをマイクロサービスで作るのはアンチパターンである、という話を聞いたことがあるかもしれません。
チームが小さいにもかかわらず流行りに乗ってマイクロサービスに分割して作ってみたものの、開発の効率が落ちるだけでしたとか、独立してデプロイできない分散モノリスができあがってしまいました、のような失敗談を聞くことがあります。
新規事業でマイクロサービスをやっていますと言うと、どうしてもそういうイメージがあるので、個人的にはあまり積極的に言わないようにしてきました。
ただBill Oneで1年半ほどやってきまして、それなりにうまく回っていると感じています。また、今回のイベントのテーマが「挑戦」ということで、個人的にもBill Oneでのマイクロサービスの取り組みを話すことに挑戦しようと、このようなタイトルにしてみました。
マイクロサービスにしなかった場合と比べることはできないので、本当にうまくいっているのかはわかりませんが、Bill Oneでは素早くリリースして改善しやすい点と、障害発生時の影響を局所化できる点で、メリットを享受できていると考えています。
もちろんすべてがうまくいっていると言うつもりはありません。たまたまうまくいったという要素も、多分にあると思っています。今日は、私たちの取り組みを1つの事例として共有することで、みなさんがマイクロサービスアーキテクチャの導入を検討する際のお役に立てればうれしいです。
あらためまして、自己紹介です。加藤耕太と申します。関西支店でソフトウェアエンジニアをしております。3年前にSansanに入社し、2年前からBill Oneの開発に携わってきました。

今日のアジェンダですが、まず最初に、チェックインということで、みなさんと認識合わせをしたいと思います。そしてBill Oneにおいてどのようにマイクロサービス化していったのか、Bill Oneでの実装方針がどうだったかをお話しします。
ではチェックインです。Bill Oneは、あらゆる請求書をオンラインで受け取るというコンセプトのクラウド請求書受領サービスです。2020年5月にローンチした新規事業ですが、すでに多くのお客さまに利用いただいています。
(スライドを示し)あらゆる請求書をオンラインで受け取るということですが、Bill Oneを利用するのは右側にある請求書受領側の企業です。この企業は左側にある請求書を発行する企業から請求書を受け取ります。
この請求書のやりとりは、現代においてもなかなか標準化されていないのが現状です。紙の請求書が郵送で届いたり、メールの添付ファイルで送られてきたりと、アナログなやりとりが残っています。
そんな状況であっても、左側の請求書を発行する企業に対し、送付方法を変えることなく請求書の送付先だけをBill Oneに変更してもらうことによって、受領側の企業はワンストップで請求書を受領できるサービスです。
さらにその受領した請求書を高い精度でデータ化することによって、データベースで一元管理できるようになり、請求書業務を効率よく進められるようになります。

また、今日のテーマであるマイクロサービスに関してですね。ウィキペディアからの引用にはなりますが、認識合わせということで、紹介します。
読み上げます。
マイクロサービスとは、ソフトウェア開発の技法の1つであり、1つのアプリケーションをビジネス機能に沿った複数の小さいサービスの疎に結合された集合体として構成するサービス指向アーキテクチャの1種であると紹介されています。
ここで重要なのは、小さいサービスが疎結合で作るところですね。よく言われるのは、技術的な観点よりも、組織論が重要であるということです。それぞれのサービスを1つのチームで管理できるのが理想である、とよく言われるかと思います。
Bill Oneのアーキテクチャにも触れておきます。Bill Oneでは、少ないエンジニアで運用できるようにGoogle Cloudのマネージドサービスをふんだんに活用しております。
ユーザーから直接リクエストを受けるところは、Backend For Frontend、BFFというところです。ここはGoogle App Engineを利用しています。この後ろでリバースプロキシするかたちで、Cloud Runのマイクロサービスが稼働しています。このマイクロサービスはKotlinを使って書いています。
そして、そのマイクロサービスのメインのストレージとしては、Cloud SQL、これはGoogle Cloudにおけるマネージドなリレーショナルデータベースですが、私たちはCloud SQL上のPostgreSQLを使っています。

ここまでが前提で、実際にどうBill Oneでマイクロサービス化していったかをお話したいと思います。
Bill Oneが新規サービスであるという話ですが、2020年5月にローンチするまでにも、いくつかのフェーズがありました。
(スライドを示す)1つ目のフェーズでは、Djangoですばやく作って、社内トライアルをしました。ここはまだ私も参画していないような時期で、SESのエンジニアにお願いして、最初はモノリスで作ってもらったというかたちです。
2つ目のフェーズから、私も参画して、少しエンジニアを増やしてSESのエンジニアから開発を引き継ぎ、Kotlinで追加機能を開発しました。
なぜKotlinかというと、当時のメンバーとしては、Djangoのアプリを引き継いでも、そこですばやく開発できるスキルセットを持ち合わせていませんでした。そこで、私たちはKotlinを選んで追加開発していきました。
これはモノリスと、そのモノリスとDBを共有するサービスと、もう1つ別のマイクロサービスのようなかたちで作っていきました。
しかし、そうやっていく中で、このプロダクトの方向性では難しいということになりました。いったん、そこまで作ったものはほぼすべて捨て去って、ピボットしてイチから作り直すという時期があり、これが3つ目のフェーズです。このタイミングで私たちは、マイクロサービスに振り切ったかたちになります。

このように紹介すると、最初はモノリスで知見を貯めて、ある程度育ってからマイクロサービスに分割したように見えるかもしれませんが、実際にはそこまででもありませんでした。
確かに、請求書業務に関するドメイン知識はある程度蓄積されていましたが、ピボットで捨て去った機能も新しく作った領域も大きかったため、自信をもってサービス分割できるほどではない状況でした。
そのようなかたちで新しいサービスを作ることになり、このタイミングでどうやって作ろうか考えました。よく言われるのは、新規サービスはモノリスで作る。特にRuby on Railsとかですね。Ruby on Railsでサッと作って、それでいけるところまでいくというのが良いとされているかなと思います。
しかし、先ほどのDjangoというところにも被るんですが、Ruby on Railsが得意な人がいませんでした。では、自分たちのスキルセットでなにかいい構成があるかと考えた時に、見当たらなかったなという感じです。
モジュラモノリスというのもありました。モジュラモノリスとは、アプリケーションコードはモジュールに分割しておいたうえで、デプロイ時に1つのモノリスにすることによって、モノリスとマイクロサービスのいいとこ取りをするような作り方です。
これは最初に始めるかたちとしてはいいと言われているんですが、世の中的にはまだあんまり知見が貯まっていないと感じています。実際自分たちが作ることを考えた時に、はたしてモジュールの境界をちゃんと維持し続けられるのかは、あまり自信がなかったです。
特にデータベースに関しては、異なるモジュールで管理しているテーブルがあったとしても、それをジョインしてしまえばすごくパフォーマンスが簡単に上がる状況で、強い心を持って、ここは境界だと定めて分離し続けられるのかというところに、あまり自信がもてませんでした。
であれば、いっそうのことマイクロサービスというかたちでサービス間の分離を強制されたほうが良い設計に導かれるんじゃないかと思い、ある程度ドメイン知識も多少は貯まっていた前提で、マイクロサービスに挑戦することにしました。

Bill Oneのサービスをどう分割したのかをお話しします。(スライドを示し)先ほどお見せしたのと同じ図なんですが、Bill Oneではこのように3つのサービスに分割しました。右側のBill Oneを契約した企業、受領側の企業の範囲で閉じる領域をinvoiceという名前を付けました。
左側の請求書を発行する企業のアップロードとか、メール、郵送といった領域とか、企業とのつながりですね。取引先の管理という領域。ここをnetworkという名前にしました。残りは、テナントとかユーザーを管理するので、tenantという名前のサービスにしました。
振り返ってみると、これはわりとうまくいった分割だったと思っています。というのも請求書を送るという時に、送付側から受領側に送られてきた請求書というのは、送付側に戻ったりしないという点です。
1つのデータを複数のサービスで変更し合うみたいな分割にすると、けっこう厳しい感覚があって、そうではなかったのはうまくいった点だなと思います。また、3つというところで、エンジニアの人数が少ない段階ではあまり小さく分けすぎないところも、よかったと思っています。

次は、実際どういう効果があったのかという話です。最初にもお話ししましたけれど、新機能をすばやくリリースしていけるという点と、障害発生時の影響を局所化できるという点でメリットを感じています。
Bill Oneではローンチから1年の間、週2、3つのペースでユーザーに価値のある機能をリリースし続けられました。ユーザーから開発スピードに驚かれたり、改善スピードの速さが受注の決め手になったみたいなケースもありました。これはすごくよかったと思います。
また障害という面では、もちろん障害が発生するのは良くないんですけれども、仮に受領側で障害が発生していても請求書を受領するところは別のサービスになっていたので、請求書の受領は継続できていました。それもメリットだったなと思います。
実際にどのような実装方針でやっていったのかをお話ししたいと思います。考えた時に、世の中にマイクロサービスのアンチパターンはけっこう出回っていたので、そこはなるべく踏まないように意識しました。
サービスの独立性を重視する点で3つ、そのうえでなるべく開発や運用の効率を落とさないという点で2つ。この5つについて順にお話ししていきます。
まず1つ目はサービスごとにデータベースを持つことすね。最初にお話したように、Cloud RunとCloud SQLを使っているんですけれども、それぞれのサービスで組み合わせを持っていて、互いに影響し合わないというかたちになっています。仮に1つのデータベースのインスタンスを再起動するとなっても、ほかのサービスには影響を与えずに済みます。

2つ目がキューによる非同期のデータ連携ですね。複数のサービスがあると、どうしてもデータのやりとりが発生しますが、その際にサービス同士での同期的な呼び出しは基本的に避けるようにしました。必要なデータは事前に連携しておいて、ローカルのデータベースから取得するかたちにしました。
例えば請求書を送付する例では、送付ユーザーが請求書を送付するのは最初networkというサービスで受けるんですが、それをCloud Tasks……これはGoogle Cloudのキューのサービスですね。これを経由してinvoiceという受領側のサービスに届けられます。そして受領ユーザーに届きます。
こういう実装になっていまして、それぞれ同じ請求書であったとしても送付ユーザーにとっての請求書と、受領ユーザーにとっての請求書は、別々のデータとして管理されているかたちになります。これも、障害時とかにほかのサービスの影響を受けにくいという点で役に立っていました。

3つ目が、共有ライブラリは作らずに重複を許容するというところです。サービスを独立して開発していると、似たようなコードは発生するんですが、そこはあえて共有化せずに重複したコードを許容するかたちにしました。
サービスごとに若干要求が違ったりするケースもありますし、そういう中で1つ共有されているコードを変更すると、複数のサービスに影響があって、その影響範囲の調査をしなきゃいけないのはリリースに時間がかかる原因になってしまいます。そういうところを回避できました。これも、ほかのサービスから独立して変更できるという意味で、良かったかなと思います。
次は運用の負担を減らすというところなのですが、やはり複数のサービスがあるとログが見づらくなるのは、課題の1つです。これは、Google CloudのTrace Contextという仕組みを使ってうまく回避できました。
Google App Engineでは、外からHTTPリクエストがやってくると自動的にX-Cloud-Trace-Contextというヘッダーが付きます。そのヘッダーをほかのサービスを呼ぶ時に引き回してあげることによって、サービスの中でちゃんとログが出力できる。
この値をログに出力することによって、このxxxxxxという部分がTrace IDと呼ばれるものなのですが、この値で検索することにより、サービス横断でログを閲覧できます。ですから、1つのリクエストで全部のサービスの流れを見れて、非常に運用しやすいです。

最後、モノレポ化というところです。もともと、それぞれのサービスごとにGitHubリポジトリを作っていましたが、コードの重複を許容するということで、やはり全部のサービスを一度に変更したいということはたまにありました。
その時に、3つプルリクエストを作るんですが、それは少し面倒くさかったので、これを1つのリポジトリにまとめて、それぞれのディレクトリで区切ったモノレポというかたちに変更しました。これによって、1つのプルリクエストで全部のサービスを変更できるようになり、開発がやりやすくなりました。
もともと、リポジトリを分けていた理由としては、CIとかCDの設定が簡単というところがありました。モノレポにしたあとも、私たちはCIにCloud BuildというGoogle Cloudのサービスを使っていますが、そこで変更のあったパスだけビルドする設定が可能なので、それを使って、あまりCI/CDの体験を悪くすることなく開発できています。

最後にまとめです。サービスの分割方針としてある程度プロダクトの方向性が見えてきてから分割したのは、良かったかなと思います。またデータの時系列が違う、データが行き来しないようなところで分割するというところと、小さく分割しすぎないところが良かったかなと思います。
作り方としては、サービスの独立性を重視するのは大事でしたし、それで開発・運用効率を落とさないところもある程度はできていたのかなと思います。
今後の課題もいくつかありますが、もし興味があれば、このあとの時間でAsk the Speakerで聞いていただけるかなと思います。
参考文献として、このあたりを当時読んでいたものを共有します。また、採用していますので、もし興味があればぜひ応募していただければと思います。


以上です。ご清聴ありがとうございました。
続きを読むには会員登録
(無料)が必要です。
会員登録していただくと、すべての記事が制限なく閲覧でき、
スピーカーフォローや記事のブックマークなど、便利な機能がご利用いただけます。
すでに会員の方はこちらからログイン
名刺アプリ「Eight」をご利用中の方は
こちらを読み込むだけで、すぐに記事が読めます!
スマホで読み込んで
ログインまたは登録作業をスキップ
Sansan株式会社
関連タグ:
この記事をブックマークすると、同じログの新着記事をマイページでお知らせします
PR2025.11.27
数理最適化のエキスパートが断言「AIブームで見落とされがちな重要技術」 1,300社が導入した「演繹的AI」が意思決定を変える
 PR
PR2025.11.28
「あの人がいなくなったら仕事が回らない」を解決 属人的な業務から脱却する「最適化」の実践方法
 PR
PR2025.11.28
「計画と運用」をごちゃ混ぜにすると崩壊する ビジネスに使える最適化システムの“境界線”の引き方
 PR
PR2025.11.27
9割がリピーターでも“飽きられない”仕掛け 馬渕磨理子氏×オリエンタルランドが語る、体験価値と「成長の3本柱」
 PR
PR2025.11.28
“テーマパークの外”への挑戦で売上1兆円を目指す 馬渕磨理子氏が迫る、オリエンタルランドの新領域戦略
 PR
PR2025.11.28
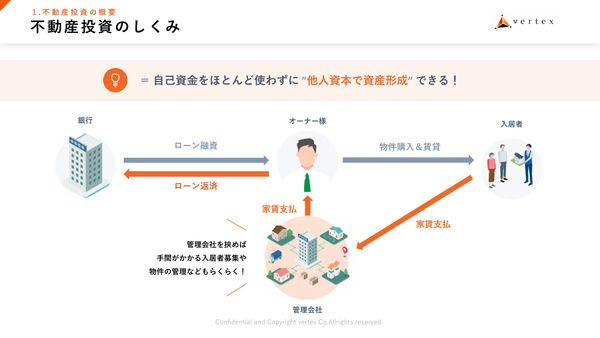
物価上昇時代の“もう1つの収入源” 自己資本約10万円から始められる、不動産投資の仕組みとリスク解説
 PR
PR2025.11.27
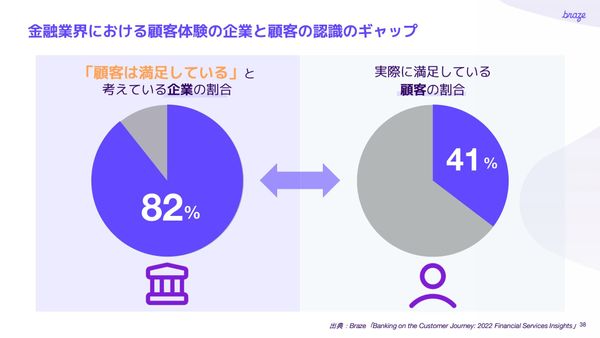
AIで激変する顧客体験──「金融機関」と「消費者」の関係を再設計 Brazeが描く“真の顧客エンゲージメント”とは
 PR
PR2025.11.28
金融機関の休眠顧客をアクティブユーザーへと転換 Brazeが提供する、収益改善を実現する「パーソナライゼーション」事例
 PR
PR2025.11.28
管理職に求めすぎる組織の限界 役割分割で生まれる新しいチーム運営
 PR
PR2025.11.27
「考えろ」と言うだけの上司が組織を壊す 自律型人材が育たない本当の理由
PR2025.11.27
数理最適化のエキスパートが断言「AIブームで見落とされがちな重要技術」 1,300社が導入した「演繹的AI」が意思決定を変える
PR2025.11.28
「あの人がいなくなったら仕事が回らない」を解決 属人的な業務から脱却する「最適化」の実践方法
PR2025.11.28
「計画と運用」をごちゃ混ぜにすると崩壊する ビジネスに使える最適化システムの“境界線”の引き方
PR2025.11.27
9割がリピーターでも“飽きられない”仕掛け 馬渕磨理子氏×オリエンタルランドが語る、体験価値と「成長の3本柱」
PR2025.11.28
“テーマパークの外”への挑戦で売上1兆円を目指す 馬渕磨理子氏が迫る、オリエンタルランドの新領域戦略
PR2025.11.28
物価上昇時代の“もう1つの収入源” 自己資本約10万円から始められる、不動産投資の仕組みとリスク解説
PR2025.11.27
AIで激変する顧客体験──「金融機関」と「消費者」の関係を再設計 Brazeが描く“真の顧客エンゲージメント”とは
PR2025.11.28
金融機関の休眠顧客をアクティブユーザーへと転換 Brazeが提供する、収益改善を実現する「パーソナライゼーション」事例
PR2025.11.28
管理職に求めすぎる組織の限界 役割分割で生まれる新しいチーム運営
PR2025.11.27
「考えろ」と言うだけの上司が組織を壊す 自律型人材が育たない本当の理由

