


 PR
PR2025.11.27
数理最適化のエキスパートが断言「AIブームで見落とされがちな重要技術」 1,300社が導入した「演繹的AI」が意思決定を変える
ゲーム開発におけるパフォーマンスチューニングの原理 (全1記事)
提供:株式会社テクロス
コピーリンクをコピー
ブックマーク記事をブックマーク
木元将輝氏(以下、木元):用意したスライドがちょっと少なめですが、始めさせていただこうと思います。
自己紹介をさせていただきます。

木元将輝と申します。今までは、主にゲーム開発やソフトウェア開発をやっております。略歴は、いろいろあちこち節操なく勤めて、最終的にドリコムさんでお仕事をさせていただいておりました。

現在は、フェローなので研究職を中心に、並列して開発、ディレクションの一部もしています。
コンサルタントというのは名前ばかりで、あまり大きく動いてはいないのですが、そういったこともやっています。
趣味はゲームをやることぐらいしかないです。タイトルも書いてあるのですが、だいぶマイナーっぽくて、ご存じない方がほとんどではないかと思います。ですので、「いい感じの」という、ざっくりしたかたちでお話をさせていただこうかなと思います。
ただ、ざっくりとしたお話の中でもけっこう細かいことがあって、あまりソフトウェアでは馴染みがないような部分に関しても、お話をさせていただければと思います。
さっそくですが、「パフォーマンスチューニングの始まり」です。そもそもパフォーマンスチューニングをしなければいけない状態になる前に、大抵こういった、いくつかの現象が要因やきっかけとなることが多いのかなと思います。

これらは、ほとんどの場合はFPSが出ていない、足りない状態となっています。このあたりに関して、とりあえず思い当たることを列挙してあります。「スペック」「リソース」「描画」「バグ」「コード」あたりを、最初に修正しなければいけないのではないかと想定されます。

1つずつ見ていこうと思います。スペックですが、これは端末のスペックのことを指しています。端末を疑うという意味で、スペックが足りていないのではないかということです。
当てはまる問題なんですけれども、(むしろ)ここは最終的にたどり着く場所ですね。なので、ここに関してはすぐにどうこうという話ではないです。
次にリソースですね。基本的にデザイナーさんとのやり取りの中でリソースを製作していかれると思うんですけれども、そのリソースが問題になっている可能性を次に疑います。とは言っても、「この順番で疑わなきゃいけない」という話ではないです。主に疑われる原因としては、やっぱりこのへんが非常に多くなると思います。
ここは経験上、とても多いところで、あまりコミュニケーションが取れていないような気がします。どちらかというとワークフロー的な部分で、いざふたを開けてみると……当時はそんなものはないんですけど、今のいわゆる4Kみたいな画質のテクスチャーがあったり、大部分のものでは透過処理、アルファが入っていたり、画像のファイル形式で非圧縮のものを使っていたりします。
このあたりは本当に単純なミスなんですけど、見落としがちです。ここに関してですが、デザイナーさんに絵を発注するみたいなかたちでお仕事されている方もいらっしゃるかもしれないですが、顔を突き合わせて、ちゃんとお願いする、もしくは確認をするということをワークフロー的にやる必要があるんじゃないかと思っております。
次に、描画です。描画はシステム周りに近く、とくに昨今ではゲームエンジンのようなかたちで利用されるプロジェクトも多いと思います。ここに関しては、このあとでお話をしようと思いますが、パフォーマンスチューニングの対象になると思います。
この「バグ」と書いてあるところは、基本的にフレームワークとライブラリを多用することが多くあると思います。こちらのフレームワーク内、もしくはライブラリ内でのバグももちろんありますし、利用の仕方を間違っていたり、これらに係る問題を解決していけば修正されるようなこともあります。
そうした場合、だいたいパフォーマンスチューニング云々ではなく、「通常の処理のバグを直していたら直った」「パフォーマンスが改善した」ということが十分にあり得ます。
コードですね。最終的に、パフォーマンスチューニング的には、プログラマーが自分で書いたコードに関して修正をする可能性が残っています。ですので、こちらを確認する必要があるのですが、ここらへんですね。処理の重複であったり、再帰処理であったり、負荷となるような処理がどこかにあるかを基本的には探すことになります。
ただ、最近に関しては、WebのAPIを使われるようなものも多いと思います。WebのAPIを使う上で、おそらく非同期で使っていると思いますが、「非同期で使っているつもりが同期をとってた」ということが意外と多いです。このあたりはネットワーク周り、もしくはスレッドを分けた中をちょっと気をつけて見る必要があるかと思います。
これらのボトルネックの特定をする必要があって、みなさんご存じのプロファイラです。

プロファイラ自体は、アーキテクチャやOSによってそれぞれ違いますし、またメーカーが提供しているものもあれば、そうでないもの、サードパーティーが提供しているものもあります。こちらは使い方がそれぞれ違っていたり、計測できるものが違っていたりします。今回は割愛させていただきます。
このプロファイラは、わりと万能感があるんですけれども、意外とボトルネックを特定するのは難しいんです。これは冗談でもなんでもなく(笑)、最終的にプリントデバッグです。本当に初歩的なもので、初歩の初歩ですけれども、おそらくみなさんも使ったことがあると思います。
単純に、ログを標準出力に出力するだけですが、最終的に特定する場所を、コードの一行一行で特定していくためには、結局これが必要になります。ただ、先ほど少しお話ししたんですけれども、スレッドが分かれているような場合ですと、正常に標準出力に出力されないことが多いというか、ほぼ出力されない状態になりますので、その場合は素直にデバッガーを使って行う必要があるのではないかと思います。
今度は「ボトルネックが特定できない」ということで、今見たボトルネックを特定する方法を使っても特定できない場合です。これは、「このへんじゃないか?」と調べるためのあたりをつける方法になります。

先ほどから出ているんですけれども、リソースの見直しです。これはかなり重要な部分ですね。「テクスチャサイズ」「縦横の長さ」と書いてありますが、要するに全部「サイズ」です。一番下はファイルサイズみたいなものですし、真ん中もピクセルのサイズです。1ピクセルあたり、どれぐらいの色深度があるかとかですね。
「色空間」と書いてあるのは、色の数だと思ってください。「透過」は、アルファブレンディングですけれども、1ビットの透過もありますし、8ビットの透過もありますので、これもまた見直しがいると思います。最大32ビットですかね。現在だと64ビットの深度もあるんですけれども、だいたい32ビットぐらいです。
ボトルネックの特定ができない場合には、この4つのリソースを見直すことが、非常に重要になってくるかと思います。
先ほど端折った描画ですが、これもまだ先があります。

ざっくりと、文章でひと言で言うと、オーバードローです。ほとんどがこれですね。オーバードローというのは、スライドの下にありますけれども、ポストプロセスやアルファブレンディングのことを指しています。
一般的に言うシェーダー、もしくは通常の透過処理をした場合など、このあたりはすべてオーバードローと呼びます。同じピクセルに何度も書き込むことをオーバードローといって、その部分が大抵、描画では最終的にオーバードローでパフォーマンスが落ちていることが多いです。
ここから、非常に今まで評判が悪かった(笑)、ハードウェアの重要性についてもお話をしたいんです。あとは今回、Cocos2d-xをもとにお話をするということだったので、そちらをもとに話したいと思います。
こちらがパフォーマンスチューニングです。

5年前や10年前など、いつパフォーマンスチューニングをやっても、結局、同じ箇所でパフォーマンスは落ちます。そこを少し詳しくお話ししようと思います。
Cocos2dをもとにお話をしているんですけれども、UnityやUnreal Engine、もっと言ってしまうとCryEngineやFrostbiteなど、いっぱいあるんですけれども、全部同じです。有名なところが作ったエンジンでも、自家製のエンジンでも、まずここが問題になります。
「CPU側の問題」と書いてありますけれど、Draw CallがCPUの問題です。「GPUが描画をする」というと、当然GPU側の問題と思われる方もいらっしゃると思いますけれども、これはあくまでもCPU側の問題です。

ざっくりソースが出てきましたけれども、読む必要はありません。今回はOpenGLをもとにしていますので、最終的な描画処理としてglDrawElementsが呼ばれることになって、このglDrawElementsを発行するために必要なAPIの数が、これだけあります。
値をセットしてやるんですけれども、実際にはこれだけ多くの設定が必要になります。描画でのDraw CallでCPUリソースを圧迫するのは、これが理由になります。Unityなどを使っていらっしゃる方は「Draw Call」はよく聞くと思うんですけれども、そのDraw Callは、結局(スライドを指して)これ全部のことを指しています。
本来Draw Callと言ったらDrawElementsの数なんですけれども、DrawElementsの数が多いのが問題ではなく、DrawElementsを実行するために、ほかのAPIを呼び出さなければいけないことが問題になっています。
あくまでも今は、OpenGLの部分で話しているので、Draw Callに関して、OpenGLで呼び出しの回数がボトルネックにつながるのは、これが理由になります。APIの数が多いからということですね。
ここからCocos2dです。

少し見づらいですが、上の5行と、その下のグリーンの7行ぐらいと、後処理が2行残ってます。色が違う部分ですね。赤いほうではなく緑色の部分なんですけれども、Cocos2d-xの手法としてはキャッシュというかたちで実装してます。一度設定してしまえば、あくまでも次のDrawElementsを呼ぶまでに変更がなければ、このDrawElementsだけで済むという最適化をしています。
これは何が最適化されているのかというと、昔は「スプライト」と言っていたんですけれども、2Dですので、1つのフラグメントを生成するのに必要な処理をキャッシュしていて、まったく同じか、もしくはほんの少し違うだけ、ぐらいのテクスチャを表示するときには、これで最適化されます。
ただ、いろんな種類のテクスチャをたくさん出そうとすると、当然、前の設定の部分が全部変わりますので、結局このDraw Callをだいぶ多く呼び出すことになります。ですので、これも使い方の問題ということになります。
結果、CPU側の問題としては、Cocos2dはわりとAPIの呼び出し回数が削減されて、最適化はきちんと行われています。ただ、最適化の手法を理解した上で使わないと、最適化されている、要するにパフォーマンスチューニングがすでにされているにもかかわらず、それに則って速度を稼ぐことができないということになってしまいます。ですので、手法を理解した上で、手法に沿って行うことが大前提です。
そして、GPU側の問題、ピクセル処理の問題ですね。まず、一番大きな問題が、画面の解像度です。

例えば、通常のPC画面、いわゆるフルHDと言われているようなもの……だいたい2K、3Kと言われる「1920×1080」や「2560×1600」は、今のスマホの解像度に比べるとかなり低いです。2560までいくとやや近くなってきますけれども、ピクセル処理はあくまでも画面の解像度に対しての処理になります。現在のモバイル機器、スマホの解像度は非常に高い状態です。
ピクセルを描画するフィルレートが高いということにもなってきていますが、ほとんどパフォーマンスは上がらない状態が続いています。今後もほぼ間違いなく続くと思われるんですけれども、なぜそれが続くのかは、後ほど話したいと思います。
そして、ラスタライズです。

実際に描画される描画のパイプラインが内部的に……今回で言うとCocos2dなんですけれども、Unityもそうですし、もちろんUnreal Engineもそうなのですが、ベースとなるグラフィックスパイプラインがある中で、ラスタライズを行うところがあります。
ラスタライズは、2Dの各ピクセルに対して処理を行うところで、実際に平面上で見えます。3Dの場合は2D化し、2Dのものは当然2Dのまま、テクスチャが描き込まれた面を表示する部分です。
ここは、直接手を加えられない、プログラマブルではない部分です。ではどうするのかという話で、結局こちらも先ほどポストプロセスとアルファブレンディングとお話しした、オーバードローの問題が大きく関わっているということです。
ですので、なるべく1つのピクセルに対して処理を1回、もしくは数回で済むようにしましょうというお話です。
先ほどの繰り返しになりますけれども、具体的には、透過しているものを透過したり、10個も20個も重ねたりするのは……とくに透過した場合には、透過した時点で既に描画の回数は2回になりますので、それをもう1枚出すと4回や8回など、どんどん増えていきます。そのあたりは気をつける必要があります。
そして、これはフィルレートに関する部分です。PowerVR、Adreno、Tegreはもうないんですけれども(笑)。このあたりに関しては、プログラマブルシェーダーと呼ぶ部分なので、飛ばそうと思います。
こちらは先ほど書いたオーバードローですね。フラグメントシェーディングは、シェーダーと呼ばれる部分です。よく「シェーダーを書く」「シェーダーを作り直す」のようなかたちで使われています。
このフラグメントシェーディングに関しては、ハードウェア毎でだいぶ特性が違うので、一律「このシェーダーを作っておけば大丈夫」とは言えない状態です。
先ほどお話しした、2回、3回と描画が重なる理由は、もう単純に、奥から手前へ描画しますので、システム的なことです。これはエンジンがどうという問題ではなく、単純にパイプライン上の仕組みとして、基本的に奥から手前に描画します。ここでオーバードローが発生しやすいですよ、ということです。
アルファブレンドをするときに重要なことです。

あくまで一例ですが、左側の緑色の丸以外の部分が仮に透過だとすると、こういう作り方をされることがけっこう多いんですね。
なぜかというと、基本的に座標を書くのに、キャラクターごとなど、とにかく表示するもの……基準にするのは左上か、もしくは真ん中を基準にされると思うんですけども、ここはデザイナーさんときちんとコミュニケーションがとれていないと……(例えば)「この代わりにこれを差します」「このキャラクターの代わりに、このキャラクターをスライドします」と言うと、デザイナーさんは、枠を同じにした状態で、中や表を変えてくることが多々あるんです。
これは非常にもったいないと言いますか、本来であればギチギチに絵が入っている状態で、アルファで抜いている部分が少なければいいんですけれども、「今回は、ひと回り小さいな」というものでも、やっぱり同じだけの領域をアルファで抜いている状態のものもよく見受けられるんです。
このあたりは技術的な問題というよりは、運用、ワークフローの部分ですので、そういうところもいろいろ気にされるといいかと思います。
そして、いきなりCocosの受け売りになるんですけれども、一応、原理だけお伝えしようと思います。

これはCocosで使われているパフォーマンスチューニングの1つで、SpritePolygonというかたちです。
絵を見ていただいたらわかると思うんですけれども、(左側は)単純に一枚絵で、実際に必要なキャラクターを描いて、周りを抜いているだけです。これに対して(右側の)SpritePolygonは、キャラクターとして描いてある部分だけを分割しています。ですので、パフォーマンス的にはいいです。
ただし、どれにでも対応しているものとして、これだけをバーッと使うのは厳しいですね。使い方や、実際にどうするかは、技術的なことよりもワークフロー的な部分になるかなと思います。
そして、シェーダーのパフォーマンスです。これも先ほど言っているんですけれども、シェーダーのパフォーマンスを改善する必要があります。「シェーダーのパフォーマンスを改善する」とひと言で軽く言っているんですけれども、シェーダーのパフォーマンスはけっこう上げにくいです。

まず1つは、分岐をなくすことです。ちょっと戻りますけれども……(スライドを指して)これがCPUのパイプラインとGPUです。時期的にES2.0になっておりますけれども、シェーダーはこちらで言うと下から2番目ですね。
Fragment Processingで実際にシェーダーが読み込まれて、それを実行している部分です。何度も申し訳ないんですけれども、このパイプラインはOpenGL上でのパイプラインなので、必ずしも全部このかたちには沿っていないです。
例えばDirectXとか……思わず今、DirectXと言ってしまいましたけれども、それ以外にもいくつもあります。それぞれのパイプラインが違いますので、あくまでも一例として見ていただきたいということです。
Fragment Processingの部分は、ハードウェア的にどうするかというお話になってしまいます。あくまでもこれはドライバレベルで、実際のGPUに対して、OpenGLがCPUの機能を使って実装しているドライバの部分です。
Scissor Test、Fragment Shading、Stencil Testというものがあるんですけれども、Scissor TestとStencil Testの間に挟まれたFragment Shadingがシェーダーと言っているもので、それを最終的にここで回します。
ハードウェア的にCPUとGPUがあって、基本的には役割が違います。CPUは複雑で大量の命令を実行するために作られています。一方、GPUは単純で大量な演算をするために設計されています。CPUとしては、本来の命令のフェッチやキャッシュがあるのですが、GPU側はそういうものを積んでいないので、もし1つでも分岐があると、その分岐に対する負荷がものすごく高くなります。
シェーダーは、基本的にGPU上で実行するものなので、GPU上で複雑な分岐があった場合には、それが如実に出てきてしまいます。ですので……本当はシェーダーについてもっとお話ししたいんですけど、時間がないので(笑)……先に進ませていただきます。
先ほどのとおり、複雑な処理を避けることと、分岐の数を減らすことです。分岐をなくすというのは、おそらくふつうのコーディングでも当然そうだと思います。あとは演算精度を下げます。
演算精度を下げるのは、やっていい場合と悪い場合があるため、なんとも言えないんですけれども、なるべく大きいサイズの数値を使いません。大きいサイズと言うか、浮動小数点を使う場合でも、短いものを選びます。
doubleといったものをけっこう使わないといけないというのは、あまり考えにくいとは思うんですけれども、doubleを使っているところをfloatにするといったかたちで、演算精度を下げることで、だいぶ速くなります。具体的に今お話しできる部分がないのと、ちょっと時間がないためアレですけれども……。

ということで、GPU側の問題は、オーバードローとシェーダーですね。とくにサードパーティ製のシェーダーはわりとゴリゴリ書いてあります。最適化されているという意味ではなく、わりと自由に書かれているため、ここに関しては確認が必要になります。

Cocos2D上でもCPU・GPUの理解はあったほうがわかりやすいかなというのが1つです。
では、CPUとGPUの共通の問題であるメモリの帯域幅ですけれども、ここも意外と見落とされることが多いんです。

ご存じの方もいらっしゃると思うんですけれども、いわゆるVRAMです。

スマホの話というか、SoC、チップを積んでいる機械に限った話なんですけれども、ビデオメモリとCPU側で使っているメモリが共有されています。
メインメモリと呼ばれるほうを、そのままVRAMとして使っているような状態です。わけているんですけれども、そういう状態です。それ自体はあまり問題にはならないんですけど、一番大きなのは、この帯域幅をCPUとGPUで共有しているんですね。
例えば、ものすごく大きいサイズのテクスチャの転送をしているときは、CPU側で使えるメモリの帯域幅はすごく小さくなります。ですので、この小さいメモリの帯域がもし足りない場合は、CPU側が待ちます。逆も然りなので、大量に転送する必要がある場合は、気にされたほうがいいかもしれないですね。
ただし、とくにこれはゲームやエンターテインメント系でけっこう引っかかっていることが多いです。最終的には「小さいデータでやりましょう」という話になってしまうんですけれども、そこで引っかかっていることもありますよ、ということです。あとは、スレッドの生成もできなくなりますので、結局、サイズと数の削減ですね。

そして、これは個人的な意見ですが、圧縮テクスチャは、ぜひ使ったほうがいいと思います。圧縮テクスチャだけだとあまり、パッとイメージが沸きづらい方もいるかもしれないですし、当然ストレージの容量が減りますし、サイズが小さくなるんですけれども、なによりこれが一番有効なのは、ハードウェアの機能を使えるということ。ソフトウェア上ではなく、ハードウェア上で圧縮されたものを展開してくれますので、パフォーマンスチューニングの中では非常に有効です。
ただし、取り扱いがけっこう面倒くさいこともあります。これは、どうしてもチューニングしたい場合に使ったらけっこう効果は出ますが、実装したり調整するのはちょっと大変になります。

(CPU・GPU共通の問題は)パフォーマンスに大きな影響を与えるんですけれども、表面化しづらいということです。よって、こちらも気にされたほうがいいかと思います。

これがCocos2dの、バージョン2とバージョン3系のもので、実際にレンダリングされるまでの流れの違いなどです。プログラム上での話なんですけれども、こういうかたちで実装されていますよ、ということですね。
OpenGLでは、新しくレンダラーというかたちでDisplay listがあります。ESのほうではなく、通常のOpenGLで、Display listのかたちで、命令をずっと積んでいくんです。
もちろん、本家のOpenGLでは、ここに関してはDisplay listがきちんと実装されているんですけれども、ESにはないです。機能的には足りなくて、パフォーマンスとして本来出るはずのものは出ないんですけれども、それが擬似的に実装されているものがこちらになります。
ここまでいろいろとお話ししたんですけれども、根源的な問題として、「ゲームエンジンとは」というお話です。そもそもゲームエンジンなんですが、実装のコストと実装する人の学習コストを低減するために、汎用性を求めて作られたものなんですね。

対して、パフォーマンスの追求を行う場合には専用性が求められます。ハードウェアももちろんそうですし、ソフトウェアのドライバの部分もそうです。その機種専用であれば、そのハードウェアの恩恵をフルに受けられる状態になるんですけれども、汎用とした途端にいろんな制約がつきますので、一気にパフォーマンスは失われます。その代わり、先ほど言ったような実装コストや学習コストを担保している状態になります。
ですので、そもそもゲームエンジンを使うこと自体が、パフォーマンスチューニングと相反する状態にあります。ゲームエンジンを使っている状態でパフォーマンスチューニングをするという状態は、最終的にはどうしても、利便性を削ってパフォーマンスを得るというかたちになります。そううまい話はないということで、必ず対になっている部分だということを留めていただきたいです。
では、ハードウェアがいかに重要かという話をします。ハードウェア上でソフトウェアを動かしている以上は必ずそうであるものだと理解いただけると思うんですけども。

こちらはPC、デスクトップの構成ですね。

こちらがラップトップ。よく見る形式だと思います。

スマホの場合はこういうかたちで、マザーボードに近いんですけど、マザーボードがチップになったみたいなかたちで考えていただければと思います。オンチップなので、AndroidもiOSも、全部こういう状態になっています。
先ほど少しお話ししたCPUとGPUのところですけれども、CPUの特徴もまとめてさっき言いましたが、基本的には命令の実行とそのキャッシュで、レイテンシーの低減を目的としています。
キャッシュの種類は、データキャッシュと命令キャッシュがあります。これは、GPUがそれぞれ別にキャッシュを持っているんですけれども、それに加えて分岐予測……命令の分岐の予測ですね。

この予測が意外と重要で、キャッシュミスを起こすとペナルティが発生するんです。このペナルティをなるべく減らすために、日々Intelの方々ががんばっているんですけれども、これがCPUの主な役割です。
GPUも、先ほど少しお話ししましたが、命令の実行です。命令自体を実行することはGPUにも当然必要なので、GPU側にもできます。キャッシュも一応あります。こちらもレイテンシーの低減を目的として使われています。
命令のキャッシュがないので、キャッシュはCPUより少ないです。ただ、「ない」と自分で言っておいて、すぐに訂正するのもアレなんですけれども、一部を除くと言いますか、最近のものは全部(命令のキャッシュが)乗っています。
ただ、スマホのSoC上でのGPUにあるかどうかについては、今はまだそこまでいってないんですけれども、たぶんまだないと思います。
このキャッシュも当然、CPUのほうが速いです。

GPU側は遅くて小さいので、いいところが1つもないです。当然、分岐予測もありません。処理の流れとして、Fetch、Decode、Execute、Memory Access、Write BackあたりはCPUですね。
GPUはこちらです。

基本的には、CPUは実行するのが目的なんですね。GPU側は、もちろんピクセル化するのは必要なんですけれども、このラスタライゼーションでフラグメントの前の段階……シェーダーをかける前の段階が、プロセス的に1つの目安になります。

そして、CPUのパイプラインとGPUのパイプラインについては、「ES2.0相当」と書いたんですけど、基本的に3は少し増えます。

こちら、複雑で大量な命令の実行と、単純で大量な演算ですね。
ここに「本題」と書いてあるんですけど(笑)。
(会場笑)
もう時間的に厳しいとは思いますから、本当に駆け足でいきます。

(スライドを指して)このへんですね、極めて評判が悪かった……。
(会場笑)

以前に勉強会で作ったものなんですけれども、とにかくこういうことをやりますよ、ということがスライドに書いてあります。パイプライン上では、これだけのことを実際に行っていますので、ここに負荷がかかるのは当然のことだというのはわかっていただけると思います。

ESだと、このTransform Feedbackもプロセスとして入りますので、より複雑にと言うか、より処理がかさみます。
そして、各ステージの概要がバーッとあり、シェーダーの概要があります。

これもお話しするまでもないと思うんですけれども、Vertex ShaderとFragment Shaderで、ふだん「シェーダー」と言われているほうは、おそらくFragment Shaderのほうです。

当然、Vertex Shaderもあるんですけど、2Dではだいたい固定で、3Dでも余程凝ったことをしなければ基本的には固定で大丈夫なので、プログラマブルではあるんですけれども、あまりやらないかなと思います。
そして、DiscreteとUnifiedに関しても、ちょっともう……あと、ここだけ最後に見ていただきたいです。

シェーダーのユニットはこういうかたちで、「一般的には4~8」と書いてあるんですけれども、当然、ハードウェアのスペックが上がっていけば、これも上がっていくという話ではあります。このくらいで、だいたいシェーダーの処理をしているんですね。

ただ、だいぶ前のTegre K1は、Unifiedという汎用的なユニットを積んでいたんですけれども、あまり評価されなかったわけじゃないとは思いますが、人気が出ず、需要がなくなり、なんとなく消えていった状態です。
ここに関しては、先ほどからずっとお話をしていたパフォーマンスチューニングに関する中で逆説的な話になってしまうんです。「そもそもユーザーは、そこまで求めていないんじゃないか」という説があって、現状だとだいぶ違いが出にくい状態になっています。とくにPCやPS4あたりも違いが出にくいところです。
それ以上になると、最近は、横にスクリーンショットなどを並べて比較してもほぼわからないレベルになってきています。そういう意味では、画質などのクオリティを落として、パフォーマンスのほうに割り当てるのもいいかなと思います。
クオリティとパフォーマンスはトレードオフになっています。それ以外のところも基本的に、開発中であるものはだいたいトレードオフをしなければならないという選択を迫られることが多いと思います。
このままハードウェアのスペックがどんどん上がっていけば、パフォーマンスのチューニングも必要なくなるんじゃないかと思われる方もいるかもしれないですが、それは永遠にあり得ません。基本的には、このトレードオフを続ける必要が、これからもずっと出てくると思います。
少なからず、チューニングやハードウェアに興味を持っていただければと思います。最終的にハードウェア以上のものは出ないので、そこになるべく近いところまで引き上げる。ただ、汎用性を捨てることになりますので、そこは内部でご相談いただいて、やっていただければと思います。
すごく雑に説明したかもしれないんですけれども、こちらで今日の私の時間は終了とさせていただきます。ありがとうございました。
(会場拍手)
続きを読むには会員登録
(無料)が必要です。
会員登録していただくと、すべての記事が制限なく閲覧でき、
スピーカーフォローや記事のブックマークなど、便利な機能がご利用いただけます。
すでに会員の方はこちらからログイン
名刺アプリ「Eight」をご利用中の方は
こちらを読み込むだけで、すぐに記事が読めます!
スマホで読み込んで
ログインまたは登録作業をスキップ
株式会社テクロス
関連タグ:
この記事をブックマークすると、同じログの新着記事をマイページでお知らせします
PR2025.11.27
数理最適化のエキスパートが断言「AIブームで見落とされがちな重要技術」 1,300社が導入した「演繹的AI」が意思決定を変える
 PR
PR2025.11.28
「あの人がいなくなったら仕事が回らない」を解決 属人的な業務から脱却する「最適化」の実践方法
 PR
PR2025.11.28
「計画と運用」をごちゃ混ぜにすると崩壊する ビジネスに使える最適化システムの“境界線”の引き方
 PR
PR2025.11.27
9割がリピーターでも“飽きられない”仕掛け 馬渕磨理子氏×オリエンタルランドが語る、体験価値と「成長の3本柱」
 PR
PR2025.11.28
“テーマパークの外”への挑戦で売上1兆円を目指す 馬渕磨理子氏が迫る、オリエンタルランドの新領域戦略
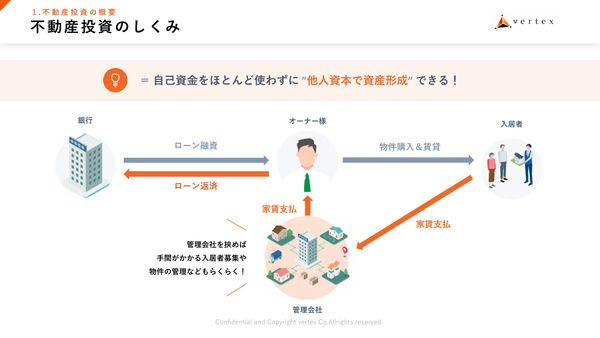 PR
PR2025.11.28
物価上昇時代の“もう1つの収入源” 自己資本約10万円から始められる、不動産投資の仕組みとリスク解説
 PR
PR2025.11.27
AIで激変する顧客体験──「金融機関」と「消費者」の関係を再設計 Brazeが描く“真の顧客エンゲージメント”とは
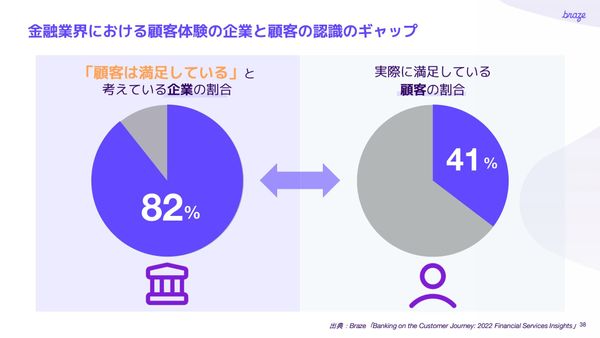 PR
PR2025.11.28
金融機関の休眠顧客をアクティブユーザーへと転換 Brazeが提供する、収益改善を実現する「パーソナライゼーション」事例
 PR
PR2025.11.28
管理職に求めすぎる組織の限界 役割分割で生まれる新しいチーム運営
 PR
PR2025.11.27
「考えろ」と言うだけの上司が組織を壊す 自律型人材が育たない本当の理由
PR2025.11.27
数理最適化のエキスパートが断言「AIブームで見落とされがちな重要技術」 1,300社が導入した「演繹的AI」が意思決定を変える
PR2025.11.28
「あの人がいなくなったら仕事が回らない」を解決 属人的な業務から脱却する「最適化」の実践方法
PR2025.11.28
「計画と運用」をごちゃ混ぜにすると崩壊する ビジネスに使える最適化システムの“境界線”の引き方
PR2025.11.27
9割がリピーターでも“飽きられない”仕掛け 馬渕磨理子氏×オリエンタルランドが語る、体験価値と「成長の3本柱」
PR2025.11.28
“テーマパークの外”への挑戦で売上1兆円を目指す 馬渕磨理子氏が迫る、オリエンタルランドの新領域戦略
PR2025.11.28
物価上昇時代の“もう1つの収入源” 自己資本約10万円から始められる、不動産投資の仕組みとリスク解説
PR2025.11.27
AIで激変する顧客体験──「金融機関」と「消費者」の関係を再設計 Brazeが描く“真の顧客エンゲージメント”とは
PR2025.11.28
金融機関の休眠顧客をアクティブユーザーへと転換 Brazeが提供する、収益改善を実現する「パーソナライゼーション」事例
PR2025.11.28
管理職に求めすぎる組織の限界 役割分割で生まれる新しいチーム運営
PR2025.11.27
「考えろ」と言うだけの上司が組織を壊す 自律型人材が育たない本当の理由

