

 PR
PR2025.11.27
数理最適化のエキスパートが断言「AIブームで見落とされがちな重要技術」 1,300社が導入した「演繹的AI」が意思決定を変える
提供:LINE株式会社
コピーリンクをコピー
ブックマーク記事をブックマーク
河村勇人氏:それでは始めたいと思います。河村勇人といいます。みなさん、こんにちは。LINEでシニアソフトウェアエンジニアをしています。現在は、全社向けに提供されているKafkaのプラットフォームを開発・運用しているチームのリーディングをしています。

個人的にパフォーマンスエンジニアリングがすごく好きで、Apache Kafkaのオープンソースのコミュニティでもアクティブに活動をしていて、過去にはいくつか大きな場でパフォーマンスエンジニアリングに関する話をしています。Kafka Summit2017年・2018年や、去年のLINE DEVELOPER DAYでも、今日お話しするようなパフォーマンスエンジニアリング・リライアビリティエンジニアリングに関わる話をしました。
さて、今日はLINEにおいてKafkaがどのように使われているかという話から始めるのですが、その前に1つみなさんにお伝えしておきたいのは、今日私がみなさんにお伝えしたいことは、我々がどのようにKafkaを使っているかやKafkaがどれだけ優れているかといったことでもなければ、Kafkaを使う上でのベストプラクティスでもありません。
我々がこのKafkaのプラットフォームを運用していく上で日々行っているリライアビリティエンジニアリングの考え方や、言語やソフトウェアに固有ではない応用可能なテクニックについて、なるべく一般化したかたちでみなさんにお話しできればと思っています。
まず、その前提として、LINEにおいてKafkaがどのような環境でどのように使われているかを話したいと思います。
KafkaはStreaming Data Middlewareと呼ばれるものです。オープンソースで、高いスケーラビリティとパフォーマンスを備えた分散システムです。
特徴としては、データのpersistencyがデフォルトであること、またPub-Subと呼ばれるデータのディストリビューションモデルをサポートしていることがあります。Kafkaのサーバ自体はScalaで書かれていて、JVMの上で動作します。
LINEにおけるKafkaの使い方としては大きく2つあります。1つはサービス間のイベントプロパゲーションです。これは、あるサービスにおいて発生したさまざまなデータのアップデートに関心がある、ほかの多くのサービスに対して、このアップデートの内容を伝搬するためのハブとして用いられています。
もう1つはバックグラウンドにおける非同期のタスクプロセッシングです。これは、例えばあるサービスのWebサーバにおいて、リクエストを処理する過程で発生した非常に重たい処理、これをそのWebサーバの中で処理をするのではなくて、Kafkaを分散キューイングシステムとして用いて、別のプロセスで動くタスクプロセッサーに対して処理をデリゲーションする。こういった目的で用いられています。

現在、LINEにおいて、Kafkaは非常に多くのサービスから使われています。LINEメッセージング、広告のプラットフォーム、LINE Pay、ブロックチェーン、そのほかにもさまざまな多くのサービスに使われています。
LINEでKafkaが使われ始めてまだ数年なんですが、すでにLINEにおいて最もポピュラーなミドルウェアの1つになっています。今日においては、我々のプラットフォームは60を超えるサービスに利用されています。
結果的に、我々のクラスタに入ってくるデータの量も非常に大きなスケールになっていて、レコードの件数はDailyで3,600億件。また、クラスタに1日の間に出入りするトラフィックの総量は550TB(テラバイト)を超えています。これは単一のクラスタとしてはおそらく世界最大級だと思います。
また、我々のKafkaプラットフォームは非常に多くのサービスからバックエンドとして依存されているために、そこに求められるサービスレベルも非常に高いものになっています。
我々は、社内のサービス向けにSLO(Service Level Objective)を決めて提示しているのですが、今日はその中でも重要な値を2つ持ってきてみました。

まず、クラスタのアベイラビリティに関しては、99.999パーセント、いわゆるFive Ninesが設定されています。これは年間で累計のダウンタイムが5分未満であることを意味します。また、Kafkaクラスタの重要なAPIのレスポンスタイムについては、99パーセンタイルで40ms(ミリセカンド)以下という非常に厳しい条件が設定されています。
さて、今お話ししたトラフィックのスケール、そして高いサービスレベルの要求、これらは単独であっても非常にチャレンジングなものなのですが、おもしろいのはこれらが2つ組み合わさったときに起きることです。
非常に大きなスケールのトラフィックを捌きながら高いサービスレベルを維持するのは、一種の究極的な挑戦になります。なので、我々のチームにおいては、日々多くの時間をリライアビリティエンジニアリングに費やしているわけです。

我々が考えるリライアビリティエンジニアリングの責任範囲は比較的広くて、ここに書かれているような活動をリライアビリティエンジニアリングと位置づけています。

まずはSLOのビジュアライゼーションです。これは、サービスレベルを継続的に測って、SLOに実際どれだけ沿えているのかを観測し続けるためのメトリックを選択ないし開発して、それをビジュアライズしていく作業です。
また、オートメーションも非常に重要です。これには大きく2つのモチベーションがあります。1つは、誰が行っても同じオペレーションであれば一貫したワークフローで行われるようにすること。また、我々がオペレーションにかけなければならない時間を削って、我々の時間をより高度なレベルのエンジニアリングに割けるようにするためでもあります。
また、アーキテクチャの提案。これは、我々のチームではKafkaのクライアントライブラリの開発や、また我々の考える理想的なKafkaクライアントの設定、またその使い方をリファレンス実装のようなかたちで見せることによって、各サービスが理想的なかたちでクライアントをコンフィギュレーションして我々のプラットフォームを使えるように努めています。
最後は、トラブルシューティングと、そこから発生する予防的なエンジニアリングです。
今日はこれらの活動のうちいくつかについて具体例を紹介したいと思うのですが、まずはSLOのビジュアライゼーションです。
SLOを定めるためには、SLI(Service Level Indicator)を決める必要があります。これはサービスのパフォーマンスを直接的に表すシンプルな値である必要があります。
一般的には、サーバ側で観測されるAPIのレスポンスタイムやAPIのエラーレートといったものをレイテンシーやアベイラビリティの指標として用いることが多いと思います。しかし、それで十分なのかということを考えると、Kafkaのような分散システムにおいては、クライアント側からの視点が非常に重要であるということがわかります。
Kafkaのような分散システムにおいては、クライアント側とサーバ側は非常に密に協調して動作をします。協調しながら、リトライやフェイルオーバーといったようなことを処理していくわけです。
なので、例えばKafkaを通じたメッセージのデリバリーのレイテンシーを正しく計測しようと思った場合には、まずKafkaに対してデータを書き込むProducerというクライアントが呼び出すAPIのレスポンスタイムは当然関わってきます。
それに加えて、もしここでBroker側でフェイルオーバーが起きれば、そのフェイルオーバーにかかった時間、そしてその間クライアントがリトライをしていた時間。そして、フェイルオーバーが起きたことによってクラスタ側のメタデータをクライアントに反映する必要がありますが、当然そこに要した時間を考慮する必要があるわけです。
また、Consumer側、Kafkaからデータを読み出す側においては、Fetchというデータを読み出すAPIがありますが、これのレスポンスタイムだけではなくて、Consumerが複数の分散したインスタンスで動作しているときにどのインスタンスにパーティションをアサインするかを決めるコーディネーションという処理があります。ここに要した時間も考慮する必要があるわけです。
これらを踏まえて、Kafkaを用いたメッセージデリバリーのパフォーマンスを測るためには、クライアントライブラリの中で行われる処理も経た上での状態に対して観測を加える必要があります。
この目的のためには、実際のサービスで使われているクライアントは用いることができません。実際のサービスで使われているクライアントは、当然そこに実装されたビジネスロジックからの影響を受けます。また、ここで使われるクライアントは、我々がプラットフォームの提供者側として考える、理想的な状態でコンフィギュレーションされて、理想的な使われ方をしているクライアントであるべきだからです。
その目的のために、我々はProberというコンポーネントを開発しました。これはメトリックの計測専用に用意されたクライアントです。
普通のサービスで使われるクライアントと同様に、複数のインスタンスで分散して動作をして、実際のサービスから使われているクラスタに対して動いているので、クラスタ側で起きたフェイルオーバーなどの影響をダイレクトに受けることになります。
また、Prober自体は複数のインスタンスで構成されており、それぞれが同等のメトリックを出しているため、例えばローリングリスタートしてProberを更新している最中においても、メトリックのロストがないようにデザインされています。
Proberのアーキテクチャとしてはこのようになっています。

Proberは複数のインスタンスで動作をするのですが、1つのProberの中にWriter・Reader・Reporterという3つのスレッドが動作しています。
Writerは、Kafkaのクラスタに対して継続的にレコードを書き込みながら、その書き込もうとしたレコードのIDをRedisにストアします。
一方で、Readerは、Writerが書き込んだレコードをKafkaクラスタからconsume、読み出しながら、読み出せたそのIDを同じくRedisに記録します。そして、もしここで実際のクラスタで例えばフェイルオーバーが起きた場合には、Proberも当然その影響を受けるわけです。
Writerがクラスタに対して書き込んだIDをRedisにストアする際には、そのタイムスタンプによってウィンドウイングされたバケットを用います。タイムスタンプによってウィンドウイングされた現在のバケットに対してIDを書き込んで、Readerはクラスタからレコードを読み出しながら、そこに記録されたタイムスタンプから同じようにバケットを計算して、読み出したIDをバケットに記録します。

そして、ここで3つ目のスレッド、Reporterというものがあるのですが、Reporterはこのウィンドウイングされたバケットのうち、一定時間が経過してタイムアウトしたバケットについて、WriterとReader側の2つのバケットを集めてきて、その内容を比較することによって、その差分をロスレートとして記録します。
Proberは、Scenarioと呼ばれるコンフィギュレーションを複数設定できるようになっています。このScenarioというのは、クライアントの実装、またその使い方、それからクライアントのコンフィギュレーション、そして書き込むデータのスループットや求められるデリバリーのレイテンシーといった、個別の条件を表すものです。

我々のプラットフォームは社内の非常に多様なサービスから使われていて、それぞれが異なるrequirementやワークロードを持っています。例えば、あるサービスにおいてはスループットが非常に重要。また、あるサービスにおいてはレイテンシーが非常に重要。また、あるサービスにおいては、スループットもレイテンシーもそれほど重要ではないのですが、とにかくデータがロストしないことが重要といったような要件もあります。
Proberは、この右側に示されているような15行程度のYAMLを追加することで、こういった個別のScenarioについて、統一された一貫性のある観測指標を生成できるようにデザインされています。
これを用いて、我々はSLI Dashboardというものをメンテナンスしています。これはただ数字が並んだだけの非常に簡素なダッシュボードなのですが、これだけでも非常に有効です。

例えば、我々がクラスタのメトリックを見ていてなにか異常な兆候を観測した際に、それが実際にクライアントにまで波及しているのかを判断するために用いたり、あるいは、我々のプラットフォームのパフォーマンスは、どれぐらい我々の提示したSLOに追随できているのかを追跡するために用いています。
これに示されているのは、各クラスタごと、また、そこで設定されているScenarioごとのアベイラビリティの値なのですが、ご覧のように、いくつかのScenarioにおいては少しのエラーがあったことを示すリアルな値が見えていると思います。
続きを読むには会員登録
(無料)が必要です。
会員登録していただくと、すべての記事が制限なく閲覧でき、
スピーカーフォローや記事のブックマークなど、便利な機能がご利用いただけます。
すでに会員の方はこちらからログイン
名刺アプリ「Eight」をご利用中の方は
こちらを読み込むだけで、すぐに記事が読めます!
スマホで読み込んで
ログインまたは登録作業をスキップ
LINE株式会社
関連タグ:
この記事をブックマークすると、同じログの新着記事をマイページでお知らせします
PR2025.11.27
数理最適化のエキスパートが断言「AIブームで見落とされがちな重要技術」 1,300社が導入した「演繹的AI」が意思決定を変える
 PR
PR2025.11.28
「あの人がいなくなったら仕事が回らない」を解決 属人的な業務から脱却する「最適化」の実践方法
 PR
PR2025.11.28
「計画と運用」をごちゃ混ぜにすると崩壊する ビジネスに使える最適化システムの“境界線”の引き方
 PR
PR2025.11.27
9割がリピーターでも“飽きられない”仕掛け 馬渕磨理子氏×オリエンタルランドが語る、体験価値と「成長の3本柱」
 PR
PR2025.11.28
“テーマパークの外”への挑戦で売上1兆円を目指す 馬渕磨理子氏が迫る、オリエンタルランドの新領域戦略
 PR
PR2025.11.28
物価上昇時代の“もう1つの収入源” 自己資本約10万円から始められる、不動産投資の仕組みとリスク解説
 PR
PR2025.11.27
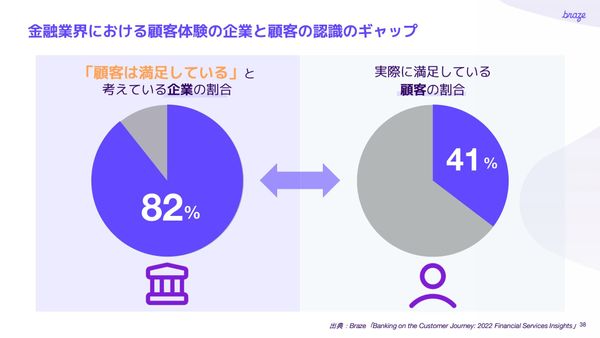
AIで激変する顧客体験──「金融機関」と「消費者」の関係を再設計 Brazeが描く“真の顧客エンゲージメント”とは
 PR
PR2025.11.28
金融機関の休眠顧客をアクティブユーザーへと転換 Brazeが提供する、収益改善を実現する「パーソナライゼーション」事例
 PR
PR2025.11.28
管理職に求めすぎる組織の限界 役割分割で生まれる新しいチーム運営
 PR
PR2025.11.27
「考えろ」と言うだけの上司が組織を壊す 自律型人材が育たない本当の理由
PR2025.11.27
数理最適化のエキスパートが断言「AIブームで見落とされがちな重要技術」 1,300社が導入した「演繹的AI」が意思決定を変える
PR2025.11.28
「あの人がいなくなったら仕事が回らない」を解決 属人的な業務から脱却する「最適化」の実践方法
PR2025.11.28
「計画と運用」をごちゃ混ぜにすると崩壊する ビジネスに使える最適化システムの“境界線”の引き方
PR2025.11.27
9割がリピーターでも“飽きられない”仕掛け 馬渕磨理子氏×オリエンタルランドが語る、体験価値と「成長の3本柱」
PR2025.11.28
“テーマパークの外”への挑戦で売上1兆円を目指す 馬渕磨理子氏が迫る、オリエンタルランドの新領域戦略
PR2025.11.28
物価上昇時代の“もう1つの収入源” 自己資本約10万円から始められる、不動産投資の仕組みとリスク解説
PR2025.11.27
AIで激変する顧客体験──「金融機関」と「消費者」の関係を再設計 Brazeが描く“真の顧客エンゲージメント”とは
PR2025.11.28
金融機関の休眠顧客をアクティブユーザーへと転換 Brazeが提供する、収益改善を実現する「パーソナライゼーション」事例
PR2025.11.28
管理職に求めすぎる組織の限界 役割分割で生まれる新しいチーム運営
PR2025.11.27
「考えろ」と言うだけの上司が組織を壊す 自律型人材が育たない本当の理由

