自己紹介とセッションのアジェンダ
小山淳平氏(以下、小山):それでは「『LINEで予約』におけるKotlinによるサーバーサイド開発」というテーマで、LINE株式会社の小山が発表します。よろしくお願いします。
まずは自己紹介します。私はOfficial Account開発室という、LINE公式アカウントに関連する機能開発を行うチームに所属しています。現在は、「LINEで予約」というサービスを提供しているシステムのサーバーサイドの開発を行っております。以前はLINE広告やSmart Channel(現トークリスト)、LINE公式アカウントの機能の開発をしていました。

それでは、本セッションのアジェンダです。まずは「LINEで予約」というサービスの紹介をします。次に、「LINEで予約」のサービスを運営するためのシステムである、予約プラットフォームのアーキテクチャを紹介します。そのあとに、予約プラットフォームのサーバーサイドでのKotlinの利用に関して紹介できればと思います。

「LINEで予約」のサービス紹介
まずは「LINEで予約」のサービスの紹介です。「LINEで予約」は、一言で言うと、LINE上で簡単にお店の予約ができるサービスです。(スライドを指して)こちらの図にあるように、お店が運営されているLINE公式アカウントや、LINE内の検索機能や、「LINE PLACE」というスポット検索サービスから、予約可能なお店を探すことが可能になっています。
そこから、予約したい時間を検索して予約をする。また、予約して友だちとシェアする体験が、LINE上で行えるサービスとなっています。
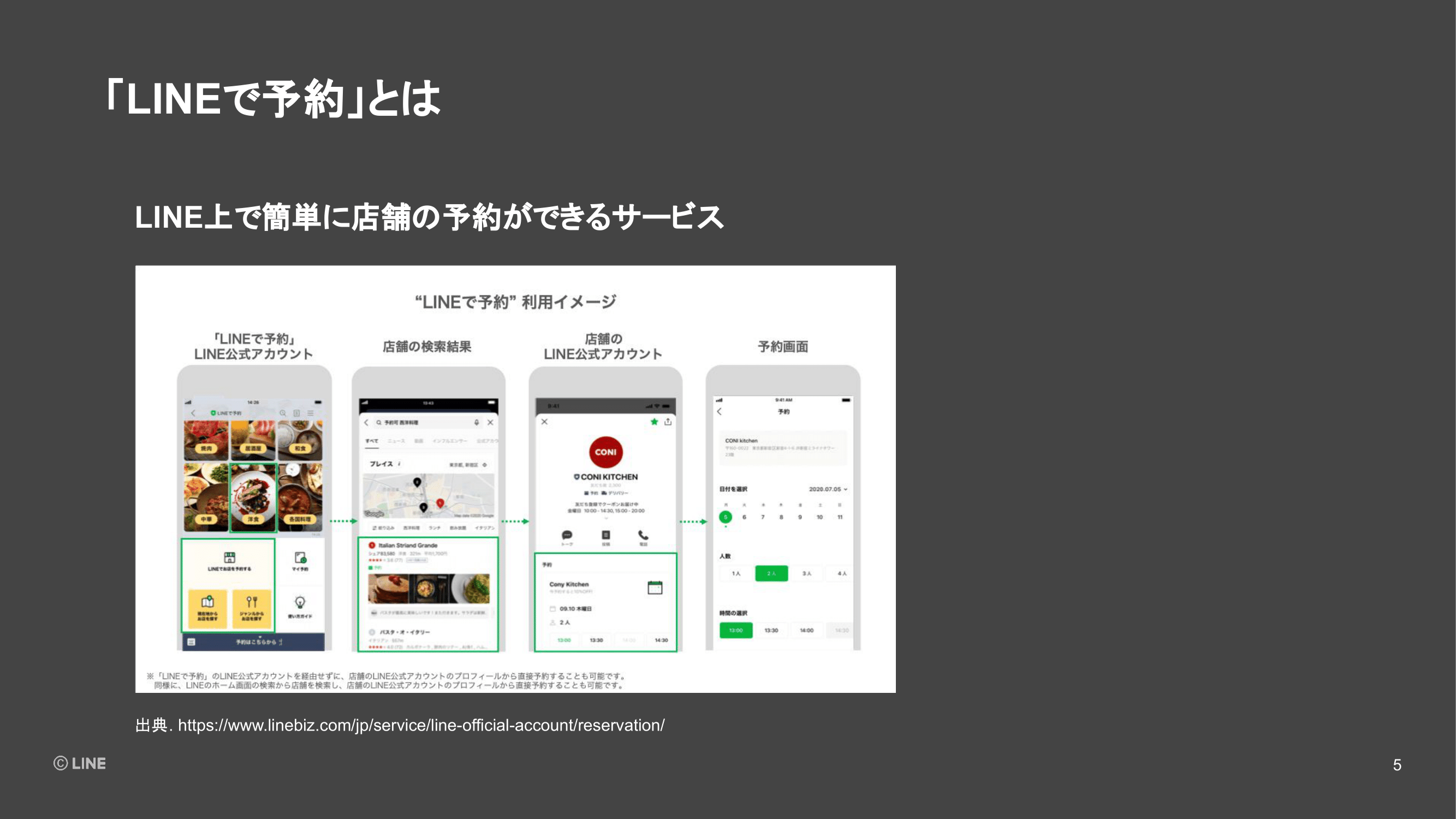
予約可能なお店の情報や在庫の情報はパートナーさまから連携いただいているため、お店の方が「LINEで予約」を使ってLINE上で予約を可能にしたいという場合は、現状は連携パートナーのシステムからの申し込みが必要になります。また、連携パートナーからのお申し込みで、LINE公式アカウントと連携が可能です。
お店で運営されているLINE公式アカウントと連携することによって、LINE公式アカウントの友だちに対して予約を訴求するメッセージ配信を行ったり、予約フォームへのリンクをリッチメニューなどでの設定が可能になります。

「LINEで予約」のプロダクトの状況としては、現在は飲食店予約の機能のみを提供していて、飲食店予約の媒体としてあるべき機能開発を行っている段階です。2020年11月にローンチして、ちょうど1年ほど経ちました。徐々にトラフィックが増加している段階になります。ここまでが「LINEで予約」のサービスの説明になります。

予約プラットフォームとアーキテクチャ
では次に、「LINEで予約」のサービスを運営するためのシステムである予約プラットフォームと、そのアーキテクチャについて紹介したいと思います。
このLINEにおける予約プラットフォームが何を指すかと簡単にいうと、連携パートナーから予約可能なお店の情報や予約枠の情報を受け取り、LINE上で予約可能なサービスの「LINEで予約」を提供することで、お店と人との距離を縮めるためのプラットフォームであると考えています。
システム構成としては、連携パートナーとユーザーの間に構築されていることになります。

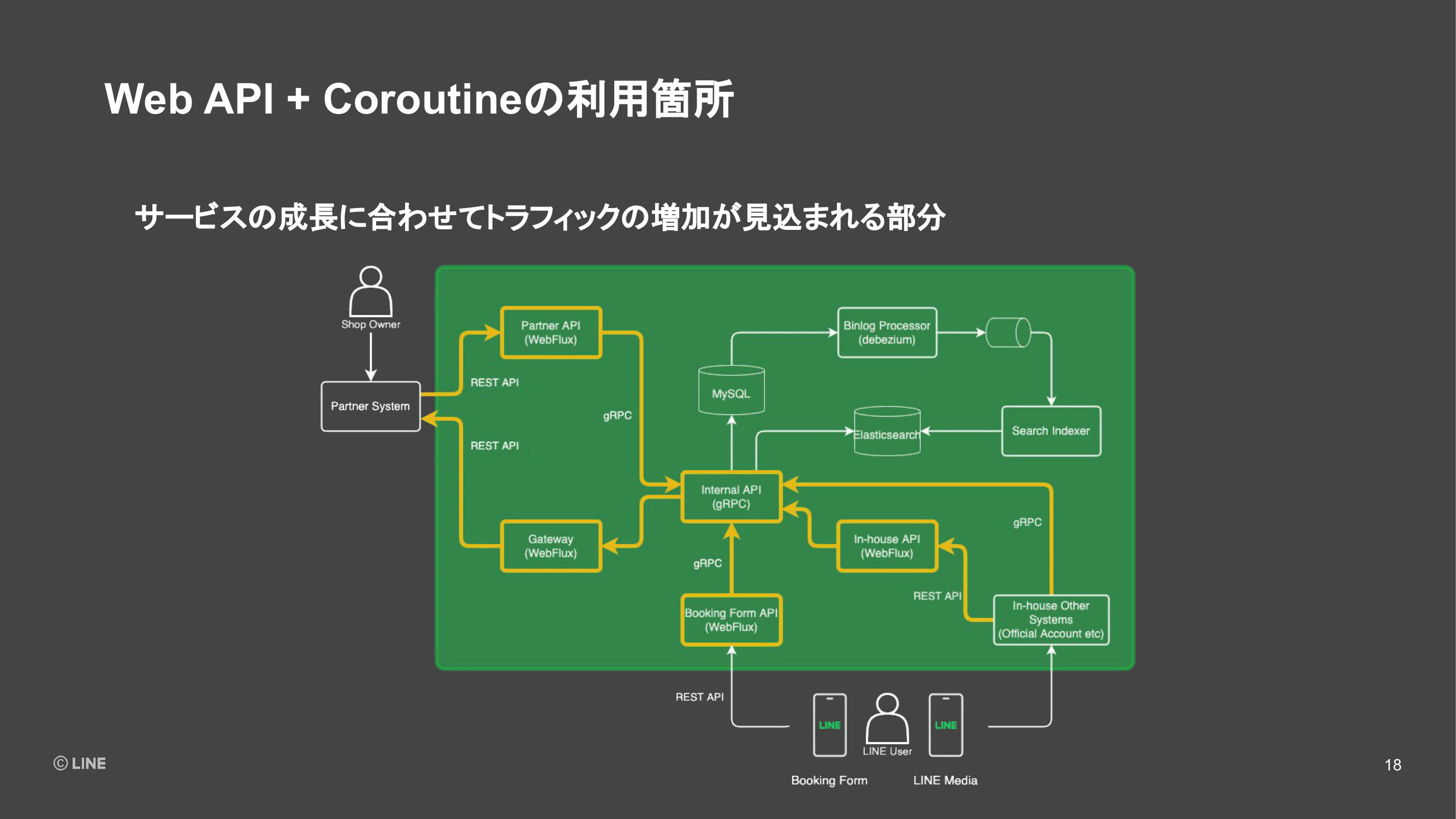
そのシステム構成について、大まかなデータの流れを追いながら紹介をしていこうと思います。(スライドを指して)まず登場人物としては、左側に記載しているのが連携パートナーのシステム。緑色で囲った部分が、予約プラットフォームのシステム。下に書いてあるのが、LINEのユーザーになります。
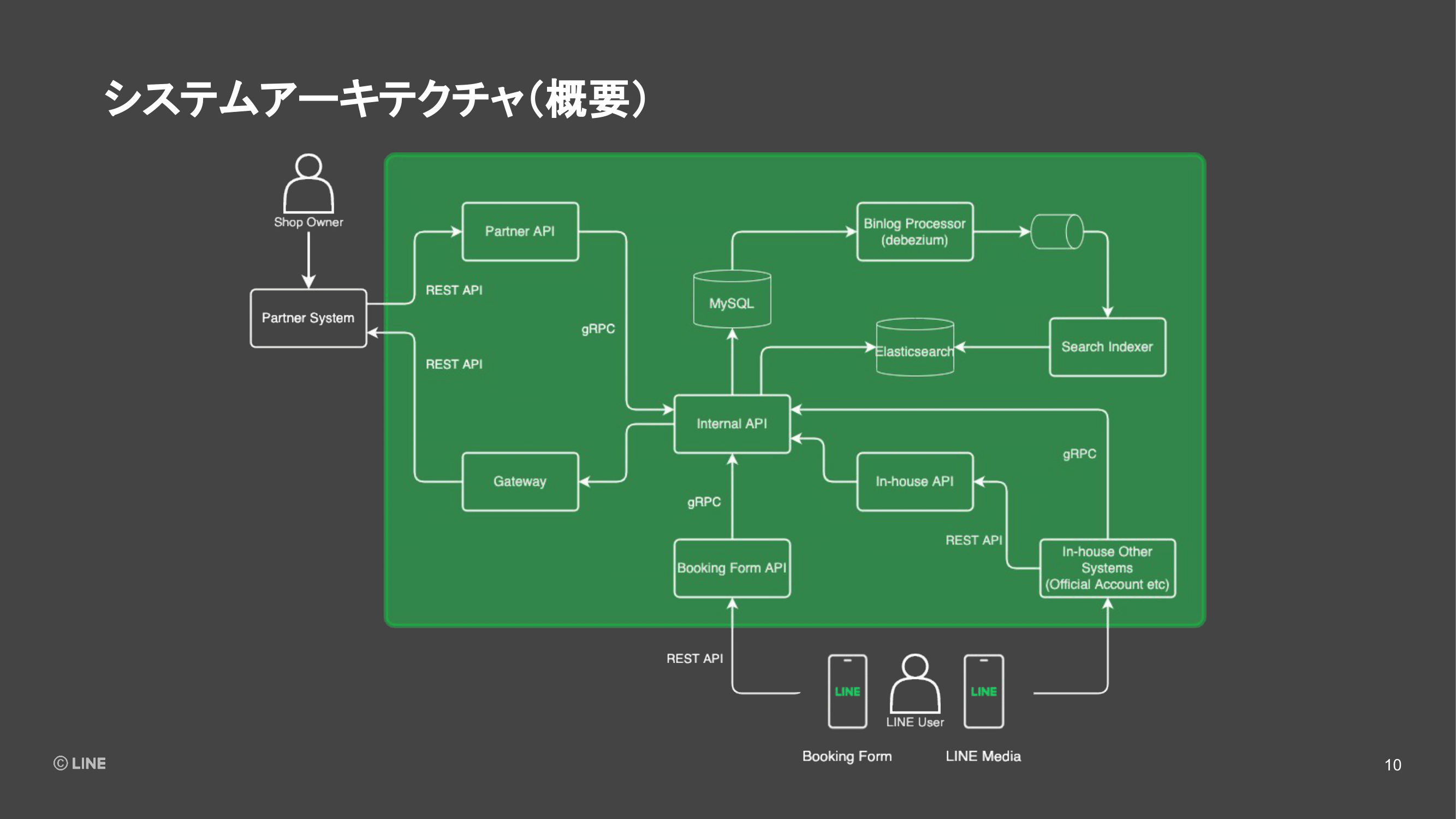
まず、連携パートナーから、お店の情報や予約枠のデータを連携いただくフェーズについて説明します。パートナーのシステムからはREST APIであるPartner APIというコンポーネントにデータを連携して、そこから内部のgRPCサーバーへ構築しているInternal APIというコンポーネントを通してデータがMySQLに保存されていきます。
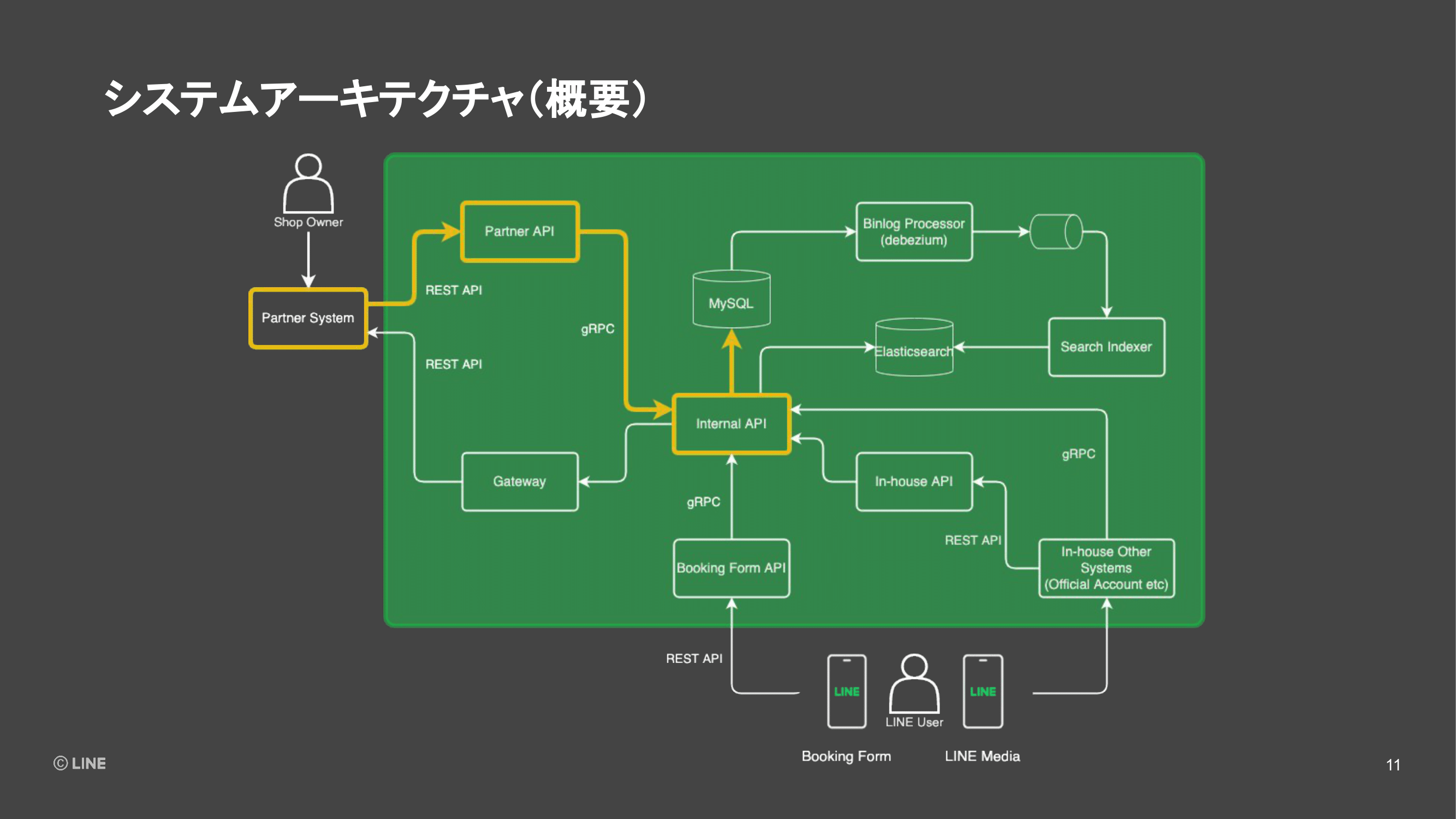
次に、連携いただいたデータから予約枠の情報を検索しやすくするために、データを生成するフェーズになります。我々のシステムでは、MySQLでの更新情報であるbinlogをパースして、ハンドリングしやすくしてくれるDebeziumというライブラリを使っています。
Debeziumから読み込んだデータは、基本的にすぐに加工してKafkaにプロデュースしておき、その先で変更情報を受け取りたいアプリケーションが、それぞれコンシュームできるようにしています。
そのうちの1つのコンシューマー、検索データを作るためのコンポーネントとしてSearch Indexerというものを実装しています。予約枠の情報の変更などを検知して、Search IndexerからElasticsearchにデータをインデクシングしていきます。ここまでで、サービスを運営するためのデータがストアされました。
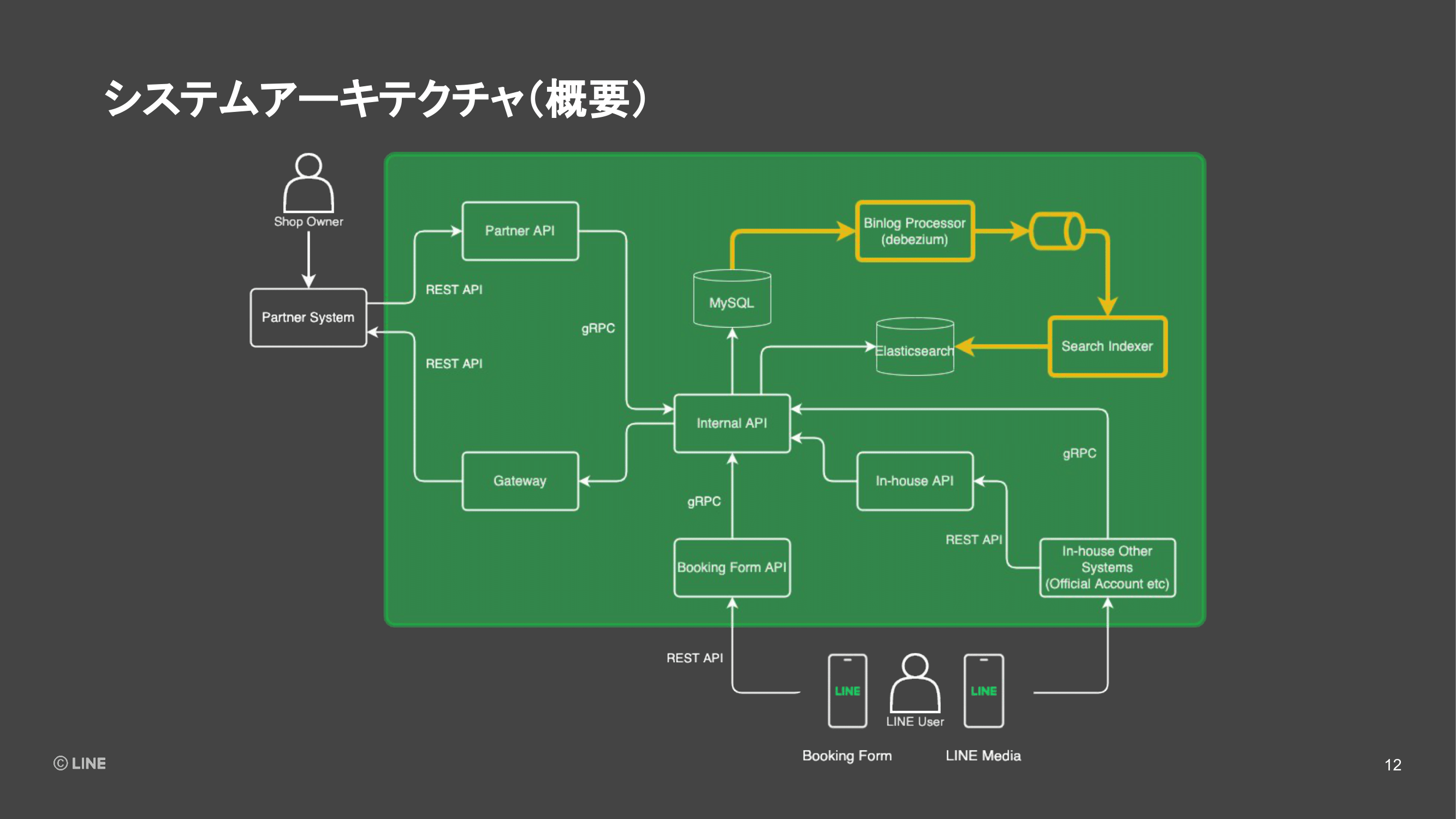
次に、連携されたデータを使うフェーズになります。ユーザーがLINEアプリの検索機能や「LINE PLACE」、またはLINE公式アカウントにおいて予約可能なお店を探したりします。それらは社内のシステムではありますが、予約プラットフォームの外のシステムにあたり、予約プラットフォームからデータを取得する必要があります。
そのため、予約プラットフォームでは社内向けのREST APIを提供したり、Internal APIにあたる部分のgRPCのクライアントライブラリを社内向けに公開しているので、それを使って予約プラットフォームへアクセスしデータを取得したり、表示したりします。
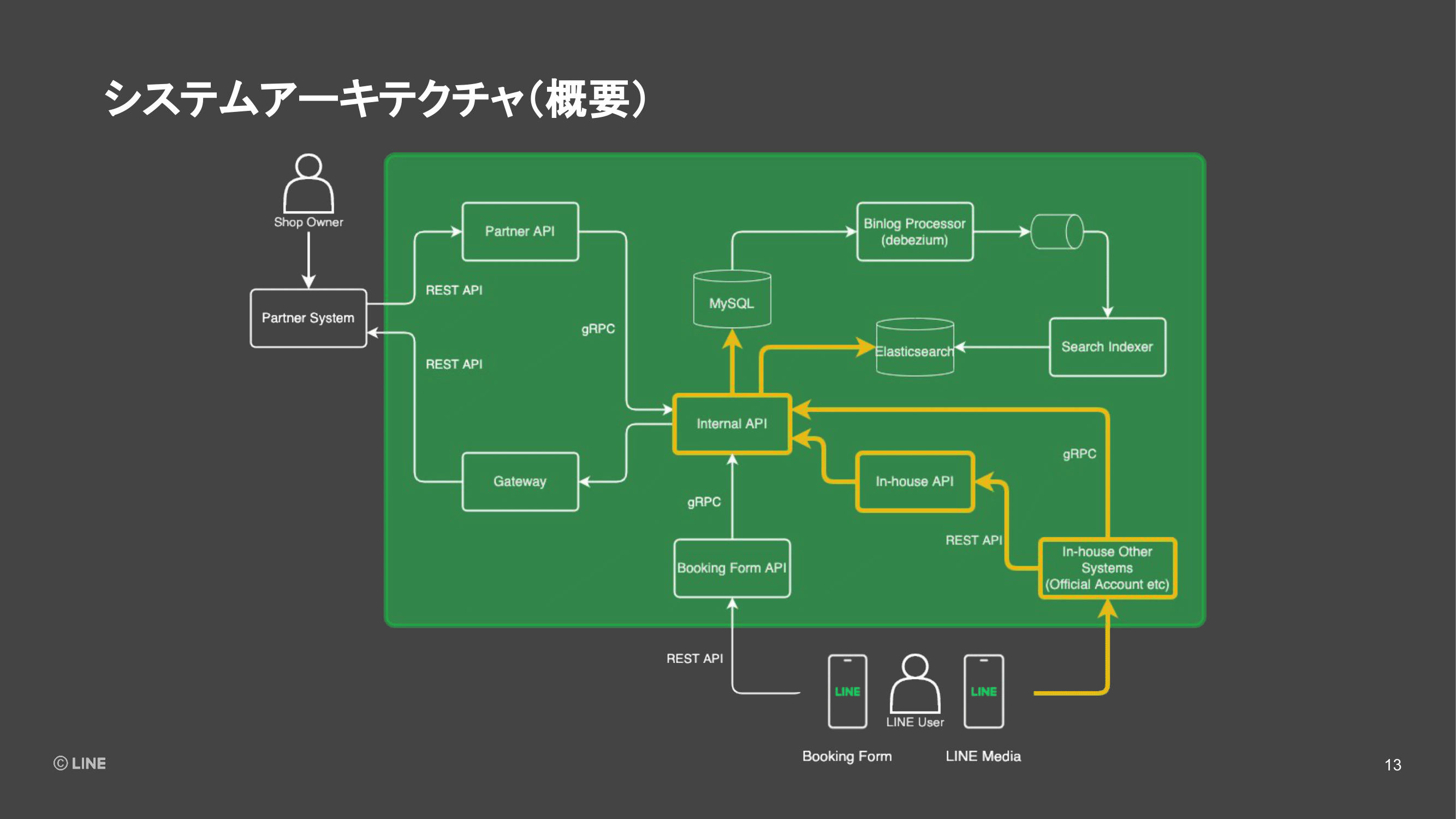
最後に予約メディアなどで予約したい店舗が見つかり、実際に予約を行っていくフェーズに入ります。予約プラットフォームが提供している予約画面のWebアプリケーションのBoocking Form部分にアクセスがきます。このアプリでは予約可能な枠の検索とか、予約情報を入力していきます。
そのWebアプリケーションの裏側では、バックエンド for フロントエンドとしてのREST APIが存在していて、そこを経由してgRPCのInternal APIにアクセスが行き、データベースを検索したり、Elasticsearchを検索したりというかたちでアプリケーションが動いています。
最終的に予約を行う際には、社外へのゲートウェイサーバーを通して、パートナー企業に予約情報が伝達される仕組みになっています。ここまでが予約プラットフォームのシステム構成の紹介でした。
サーバーサイドで利用しているKotlin
ではこれらを踏まえて、このシステムのサーバーサイドでのKotlinの利用に関する紹介をしたいと思います。まずはサーバーサイドで利用している技術の紹介です。
アプリケーションは、すべてKotlinで実装をしています。Kotlinの採用理由としては、まず新規サービスだったというのと、ちょうど立ち上げ時に部署内でKotlinを利用する波がきていたということがあります。
例えば、我々のプロジェクト以外だと、既存のJavaで構築されたアプリケーションをKotlinに置き換えるような施策も始まっており、「新しく立ち上げるのであればKotlinを使おう」みたいなかたちになっていたので採用を決めました。また、いくつかの用途でCoroutine(Kotlin Coroutine)も利用しています。ここは後ほど詳しく説明したいと思います。
あと、フレームワークにはSpring BootとArmeriaを利用しています。APIとしては、JSONのコンテントで通信をするREST APIとgRPCがあります。利用しているミドルウェアは、メインのデータストアとしてMySQL、キャッシュの機構としてRedis、コンポーネント間のデータ連携を非同期にしたい部分にはKafka、検索インデックスとしてElasticsearchを利用しています。

次に、Coroutineの利用に関して詳しく説明していきたいと思います。Coroutineについては岩谷さんの発表でも触れられていたので割愛したいかなと思いますが、我々のシステムでの主な利用用途は2点あります。
まず1つ目は、Springフレームワークで提供される、Reactive Streamsで構築されているSpring WebFluxというノンブロッキングなWebフレームワークと組み合わせたり、gRPCサーバーの実装と組み合わせてノンブロッキングなAPIを実装することに使っています。(スライドを指して)ここも「LIVEBUY」と同じようなかたちになっています。
2点目としては、バッチ処理やストリーム処理での並行・並列処理などでもCoroutineを利用しています。

Web API+Kotlin Coroutineの利用箇所
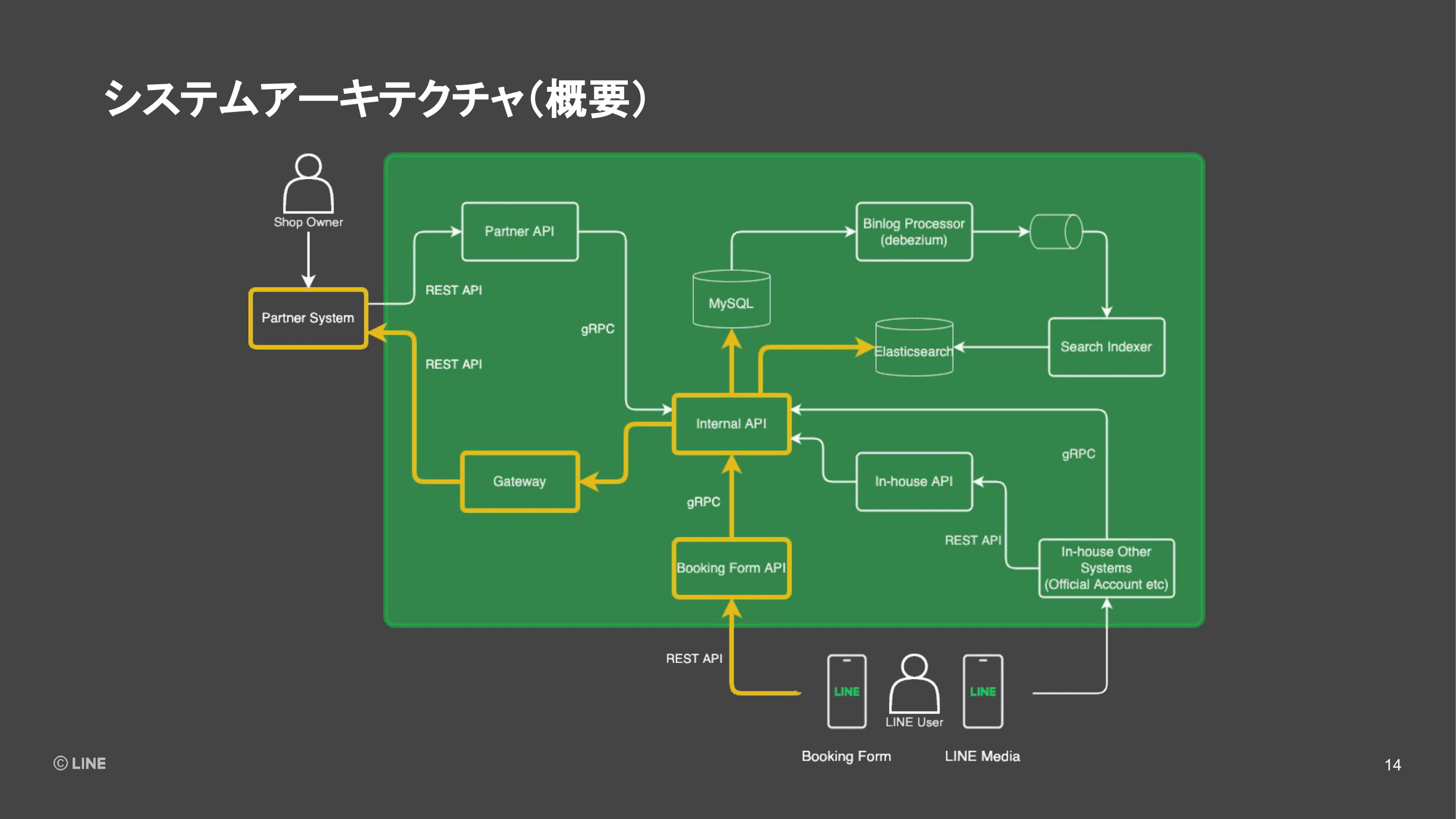
全社のWeb APIでCoroutineを利用することについて、システムのどの箇所で使われているかを紹介したいと思います。先ほどの図でいう、黄色い部分で示したところです。
これらのコンポーネントの特徴としては、サービスの成長。我々のシステムでいうと、連携企業が増えてご利用いただくお店の数が増えたり、予約していただくユーザーが増えるに連れて、トラフィックの増加が特に見込まれる部分になります。
それぞれについて、少し深掘りして紹介します。コアとなるAPI、Internal APIと呼んでいた部分についてはgRPCを採用していて、その実装でCoroutineを利用しています。基本的にビジネスロジックにあたるものは、Internal APIに載るように実装をしています。
gRPCの利用については、Internal APIにロジックを集中させるという前提で、接続するクライアントがInternal APIに対して多くなるというところで、個々のクライアント実装をそれぞれでやってもらうのは大変なので、IDLから生成されるような仕組みを導入したかったというところが1つ挙げられます。
gRPCサーバーの実装としては、まずはArmeriaのサーバー実装を利用しつつ、gRPCサービスの実装に関してはCoroutineを使っていきたいので、suspend functionの実装を提供してくれるkroto+というライブラリを組み合わせて実装しています。ただ、現在kroto+のメンテナンスが止まってしまっているので、今後はgrpc-kotlinに変えていく予定です。
エンドユーザーが触れるWebアプリケーションやWeb APIに関しては、REST APIで提供しています。そこにはWebFluxとCoroutineを使っています。
gRPCのエンドポイントを提供することも可能ではありますが、JSONのREST APIのほうが一般的なので、例えばパートナーの企業さまにgRPCの実装を強いることは難しいですし、またフロントエンドから呼ばれるAPIなどはJSONのほうが親和性が高いので、Internal APIの前段に挟まるかたちでREST APIを実装しています。
このコンポーネントでの処理ですが、gRPCにつなぐためだけのJSONからProtocol Buffers時の変換と、あとはgRPCのgRPC-Javaのfuture stubを使ってCoroutineと組み合わせてgRPCサーバーを呼ぶかたちになっています。ノンブロッキングで実装できるので、WebFluxと相性がよくなっています。
なお、前のスライドで説明したゲートウェイサーバーの部分。パートナーのシステムにつながる部分もWebFluxを利用しています。処理自体はほぼプロキシする処理だけのものもあり、WebFluxサーバーで渡させて、処理ではCoroutineを使いつつ、その中でSpring WebFluxのライブラリにあるノンブロッキングなHTTPクライアントのWebClientを使って、パートナーのAPIを叩くかたちでプロキシの処理を実装しています。

非同期なアーキテクチャを使ったWeb APIの実装をした理由
こういったCoroutineやWebFluxの非同期なアーキテクチャを使ったWeb APIの実装を採用した理由について、紹介したいと思います。岩谷さんの説明と重複するものが多いと思いますが、まず1つ目はリソースの効率がいい点です。
WebFluxのイベントログを使った多重化のデザインでは、1つのスレッドで複数のリクエストを捌くことができますし、Coroutineも前述のとおり、1つのスレッドで複数のタスクを並行処理をするため、将来的にトラフィックが増えても、サーバーを横に増やさずにスケールできるかなと考えていました。
また、Spring WebFluxの利用についてですが、Springフレームワークでは従来ではWeb MVCというブロッキングなWebサーバーが主流のため、WebFluxの知見については一般的には多くないと思います。
しかし、チーム内の他のプロダクトですでに利用されていて、安定稼働していたことから利用に不安がなかったので、我々も採用を決めました。
とはいえ、やはり非同期の実装は難しいと思います。非同期プログラミングやリアクティブプログラミングへの慣れが必要ですし、その中でブロッキングのコードを書かないということに注意を払う必要があります。

その非同期アーキテクチャと呼んでいるものの実装の難易度が高い点については、Coroutineを使うことによって比較的従来の同期的なスタイルで実装できるので、Coroutineはまず使っていきたいと考えていました。
そして、プロジェクト開始時点でKotlin 1.3がリリースされて、CoroutineがStableであったこと。あとは、Coroutineのライブラリで各種非同期ライブラリへの互換機能を提供していたことと、Spring Framework 5.2でSpringのWebフレームワークでのsuspend functionが利用可能になったので、Coroutineの採用を決めました。

Coroutineを使えば同期的なスタイルを実装できる点については、(スライドを指して)こちらのコードでも参照いただければと思います。記載の実装例ではSpring WebFluxのコントローラの中で、gRPC-Javaのfuture stubを呼んで結果を返すものになっています。左がCoroutineを使わない場合で、右がCoroutineを使ってsuspend functionで書いているものです。
gRPC-Javaのfuture stubの結果で返されるListenableFutureに対して、Coroutineが提供しているGuavaのサポートとしての.await()という中断関数を利用することによって、コード上でレスポンスのオブジェクトが触れるようになったり、あとは同期的な実装と同様に、try catchで例外をハンドリングできます。比較的理解しやすいコードかなと思います。

バッチ処理におけるCoroutineの利用例
Web APIとCoroutineの説明はここまでで、最後にバッチ処理における並列処理をするためにCoroutineを利用している点について、少し紹介をして終わりたいと思います。
(スライドを指して)こちらの例だと、FlowというAPIがありますが、そのCold streamであるFlowを使って、その中で同期的なタスクをasyncで囲みつつ、FlowのbufferというAPIを挟んでcollectの処理を非同期化させることで、同期的な処理を並列処理させるようなサンプルになります。
この処理でどういったものを解決できるかというと、例えば、大きなテーブルに対するデータマイグレーションをするような場合に、有効な手段になると思っています。そういった想定でこのコードについても軽く触れると、Flowのbuilderの部分については、ヒープをひっ迫しないサイズで、データベースから部分的にデータを取得してページングをしながら、データをemitという呼び出しで下流に流すようになっています。
かつ、そのレコードの流れてくる要素に対して下流で同期的な加工処理などを並列に処理をさせるために、asyncでまずタスクを非同期化しつつ、Flow.bufferというオペレータを挟むことで、collectの部分の中のawaitという部分の待ちが、バッファの範囲内では上流に伝わらないように書くことで、タスクを並列で処理させるようなことも可能になります。
こういったコードに関しては、大量データの更新や削除などで実際に我々は利用をしているので、もしよければ参考にしてもらえればと思います。

スケールのしやすさと見通しよく作れるKotlin Coroutine
では、まとめに行きたいと思います。「LINEで予約」でのサーバーサイドのKotlinの利用について紹介しました。Spring WebFluxやgRPCサーバーにおいて、Coroutineを利用してノンブロッキングなWeb APIを実装していること。
そういった実装を採用している理由としては、将来的なスケールのしやすさのためと、非同期アーキテクチャの実装難易度の高さに対してはCoroutineを利用することによって見通しがよくなるので、採用を決めたということを紹介しました。

私が所属するOfficial Account開発室では、Kotlinが好きなサーバーサイドエンジニアを積極的に募集しています。もし興味があってタイミングが合いましたら、ぜひご応募ください。お待ちしております。ご清聴いただきありがとうございました。