


 PR
PR2025.11.27
数理最適化のエキスパートが断言「AIブームで見落とされがちな重要技術」 1,300社が導入した「演繹的AI」が意思決定を変える
コピーリンクをコピー
ブックマーク記事をブックマーク
鈴木雄太氏(以下、鈴木):具体的なコードの一例を示したいと思います。ちなみにこのコードは公開しているので、もしよかったら見てみてください。Optuna Examplesからもリンクを貼ってもらっています。
このObjectiveの中ですが、マシンラーニングを見慣れない方は、マシンラーニングのハイパーパラメーターも見慣れない感じかと思います。
例えば、シグナルのバックグラウンドの下に、シグナルとは別に信号が乗っています。バックグラウンドをフィッティングするための関数をカテゴリカルで選んだりとか、そのバックグラウンド関数の多項式の次数を何次まで取ればよいのかなどを記述しています。こんな感じで、Objectiveを定義して、最適化を行っています。

ここでなぜOptunaを使うのかという部分についても、少し触れておきます。まずOptunaは、ソフトウェアの出来がよかったというのが一番大きな理由です。今示したとおり、探索空間の定義が非常に書きやすいです。私みたいに、ゆるふわな人間でも使えるため、非常にありがたい限りです。
実用的な観点、工学的な観点からは、マルチノードへのスケールが容易であるのは非常に重要な点です。実際に40ノード、物理1,000CPU使ってOptunaを走らせています。右は研究で使っているスパコンの一例ですね。
開発体制も重要だと思っています。研究で使っているソフトウェアの開発が急に止まったりすると、わりと困るわけです。継続的かつ活発に開発しているという点でも、非常にありがたく使わせてもらっています。
可視化の結果の分析機能なども充実しつつありますし、これからバージョン3も控えているので、非常に楽しみにしています。あとは国産ソフトウェアなので、やはり応援したくなるというのもあります。

(スライドを示して)ここらでデモを示したいと思います。メインの真ん中にある四角の部分が、実際に測定したXRDパターンと、その計算されたXRDパターンです。この2つの差分が下の青い線です。

右がOptunaのトライアルの進行と、縦軸がエラーなので、Optunaを見てもらったほうが早いですね。
探索が進んでいくにつれて、当てはまりが改善して、Rwp(エラー)も小さくなっていく様子が見て取れるかと思います。これはちょっと地味ですが、こんな感じでけっこうなスピードで下がっていきます。

もう1回見てみましょう。最初ガクンと下がって、あとはジワジワ下がっていきます。ここでは30回でこの可視化を打ち切っていますが、実験では200トライアルのエバリューションを行なっています。
非常によく使われる、Y2O3という標準物質を用いた検証の結果です。結果から言うと、30分程度でポスドクの先輩よりもよい当てはめの結果を得られました。Optunaで見つけた当てはまりのよいRwpは、だいたい6.6パーセントぐらいです。ポスドクの先輩だと、1日がんばっても6.9パーセントぐらいなので、かなりそれよりもよい結果を得られています。

他にもエキスパートシステムを使った、非常にシンプルな既存手法もありますが、そちらも7.2パーセントくらいで、Optunaはそれよりもよい。だいたい200トライアルを回しているうちの100トライアル、30分くらいで平均して人間に勝つという感じです。
実際の結果を見てみても、実際に測定したXRDパターンに非常によく当てはまっていて、うまくいったなという感じです。もう1個、同じようにDSMOというもう少しややこしい物質についても実験しましたが、こちらも同様に30分くらいで勝っています。

これがまぐれ当たりではないことを示すために、乱数を変えて何度も繰り返して探索の安定性も調べています。その結果、100回繰り返してもだいたい9割とか99パーセントの割合で、熟練者よりもよい当てはめの結果を得られています。
先ほどチラッと言及した、既存のエキスパートシステムを使った手法ですが、こちらは簡単な物質であればそこそこ動きますが、より難しい物質だとぜんぜんうまくいきませんでした。なのでこの図の中には、もはや入っていません。
その(エキスパートシステムの元になっている)ナレッジを集めてもヒューリスティックなので、既知物質についてオーバーフィットしていますが、ナレッジが対応できないような新しい物質については、うまく動きませんでした。

一方で、このBBO(ブラックボックス最適化)を使った手法では、物理的なヒューリスティックはほとんど入れていないので、こういう新しい物質についてもうまく動くことが期待されています。これも非常に大きなメリットかと思います。
早くなって自動化できたというだけではなく、さらによい点がありました。バイアスにも関係しますが、自動化することによって、今まで人間が見つけられなかったような、新しい構造の候補を見つけられました。
左の図は、各点が1個の結晶構造に対応していて、結晶構造同士の類似性を二次元上で示したものです。右下のほうにBBOで見つけた手法や人間が見つけた結晶の構造がありますが、その左上のほうに外れ値がありますよね。
誤差の点では非常によく当てはまっていますが、ぜんぜん結晶構造が違うものがありました。具体的に右で可視化してみると、マンガンと酸素の結合角がちょっと違います。

たぶんこれだけ見ても「なんのこっちゃ」と思われるかもしれませんが、原子の相対位置が、だいたい5パーセントのズレがあります。これだけ違うと、十分に物性が変わってきますので、まったく違う結晶構造といってよいわけです。
こういう結晶構造が自動で見つかって、かつ、それが十分に実験データに当てはまっているというのは、材料側でも非常に大きな驚きをもって受け止められて、評価されています。
なので、自動化で早くなっただけではなく、こういう新しい結晶構造を見つけられるというのは、非常に大きなメリットだと思います。
最後にまとめです。今日の話のサマリーとしては、計測データへの物理モデルの当てはめを、ブラックボックス最適化の問題として定式化しました。このコード、BBO−Rietveldも公開していますので、もし興味がある方は使ってみてください。
これによって、熟練者の結果と同等の結晶構造や、よりよい当てはまりを得られます。計算時間はだいたい1ノードを使った場合で、30分から60分程度で、もちろんマルチノードに並列化できます。たぶん全ノードを使えば、本当に数分くらいで終わる可能性もあるかと思います。
こちらは学際研究ですが、こういう異分野の視点で材料の問題を見るのも非常におもしろいです。非常にシンプルにうまく解けたので、このへんは本当に学際研究のおもしろさじゃないかと思います。
このような計算機とアルゴリズムで解決可能な材料の問題は、まだまだたくさんあるかと思いますので、我々の研究グループではこういう「人間・AI・ロボットが協働する材料開発」を目指して、これからも研究していこうと思っている次第です。
あとクライミング、最近メチャクチャハマっているので、みなさんぜひ行きましょう。では、私からは以上です。ありがとうございます。

司会者:いくつか質問がきていますので、さっそく質問の時間に入りたいと思います。1つ目です。「材料系出身ですが、リートベルト解析を自動化すると、互いに違った構造が出てくるのは、非常におもしろいです。オープン化されていますか?」という質問です。
鈴木:はい、されています。こちらのコードのリポジトリからもリンクがあるので、そこから見てもらったほうが早いですが、この『Automated crystal structure analysis based on blackbox optimisation.』という論文を2020年Nature系のジャーナルに出しました。こちらもオープンアクセスなので、ぜひ興味があれば読んでみてください。
司会者:すごいですね。2つ目はTwitter上でピックアップした質問です。「今回行った実験は、結晶多形はない想定なんでしょうか」という質問です。
鈴木:そうですね。そこは想定していません。結晶多形は、同じ組成の物質であっても、結晶構造が異なったものが混ざっているものですが、そういう混ざり合いはなくて、シンプルに1つの物質の1つの結晶構造であることを想定しています。
司会者:ありがとうございます。もう1つ質問がきています。「セラミックスの合成を専門としていますが、リートベルト解析の大変さを知っているためとても感動しました。GitHubや論文も拝見し、exampleのデータを動かそうとしたのですが、正直あまりうまくいきませんでした。よくあるうまくいかない理由を筆者の視点から知見いただけますと幸いです」。よろしくお願いします。
鈴木:実際のユーザーからですね。ありがとうございます。そうですね、うまくいかないのは、たぶんうまくエラーが下がらないというか、最適化が進まないことだと理解して返事します。
司会者:もう少し補足で、自分のサンプルではうまくいかなかったということですね。
鈴木:私も実際に自分の研究でいろいろ使ってみて、多少サンプルに合わせた作り込みが必要になるケースはあります。なので原因はさまざまだと思います。
原因が多すぎてなかなか答えるのは難しいのですが、初期値として使っている初期結晶構造があまりよくないというケースは、たまにあります。
つまり、ある程度その初期結晶構造がその材料に対応していないと、最小化するメトリック(Rwp)がその結晶の類似性をうまく反映できないので、最適化自体がうまくいかないケースはあります。
それ以上の具体的なケースになってくるとなかなか難しいので、共同研究みたいなかたちでよければ、コレスポンディング・オーサーに直接連絡いただければ、返事はできるかなとは思います。一般論で答えるのはちょっと難しい部分があります。
質問者:質問した者です。ありがとうございます。初期結晶構造のCIFファイルがずれているんじゃないかという話だと思いますが、その場合ははじめに手動でリートベルト解析して、ある程度合った状態から行わないと、局所解みたいな状態に陥ってしまうことはありますか。
鈴木:そういったことはあり得ると思います。例えば予めの原子位置の制約や、コンストレイントは導入できると思いますが、同じような原子位置で、不純物元素がどこにあるといった制約を入れることができると思うので、ある程度そこらへんを設定したうえでやるのは、ありだと思いますね。
質問者:やはりそうですよね。いろいろと占有率が複雑なやつで、けっこう欠損がいっぱいあったので、やはりうまくいかないのかなって。
鈴木:それ、相当ややこしいですね。自動ではなく、たぶん手動でやっても相当難しいケースだと思います。差し支えない範囲でよいので、チラッとどっかに書いていただけると、僕らも今後拡張の参考にできると思います。
司会者:ありがとうございます。多くの人がこの領域に興味があって、質問も続いていますが、いったんこの時間で質疑応答は終わらせたいと思います。発表ありがとうございました。
鈴木:ありがとうございます。
続きを読むには会員登録
(無料)が必要です。
会員登録していただくと、すべての記事が制限なく閲覧でき、
スピーカーフォローや記事のブックマークなど、便利な機能がご利用いただけます。
すでに会員の方はこちらからログイン
名刺アプリ「Eight」をご利用中の方は
こちらを読み込むだけで、すぐに記事が読めます!
スマホで読み込んで
ログインまたは登録作業をスキップ
この記事をブックマークすると、同じログの新着記事をマイページでお知らせします
PR2025.11.27
数理最適化のエキスパートが断言「AIブームで見落とされがちな重要技術」 1,300社が導入した「演繹的AI」が意思決定を変える
 PR
PR2025.11.28
「あの人がいなくなったら仕事が回らない」を解決 属人的な業務から脱却する「最適化」の実践方法
 PR
PR2025.11.28
「計画と運用」をごちゃ混ぜにすると崩壊する ビジネスに使える最適化システムの“境界線”の引き方
 PR
PR2025.11.27
9割がリピーターでも“飽きられない”仕掛け 馬渕磨理子氏×オリエンタルランドが語る、体験価値と「成長の3本柱」
 PR
PR2025.11.28
“テーマパークの外”への挑戦で売上1兆円を目指す 馬渕磨理子氏が迫る、オリエンタルランドの新領域戦略
 PR
PR2025.11.28
物価上昇時代の“もう1つの収入源” 自己資本約10万円から始められる、不動産投資の仕組みとリスク解説
 PR
PR2025.11.27
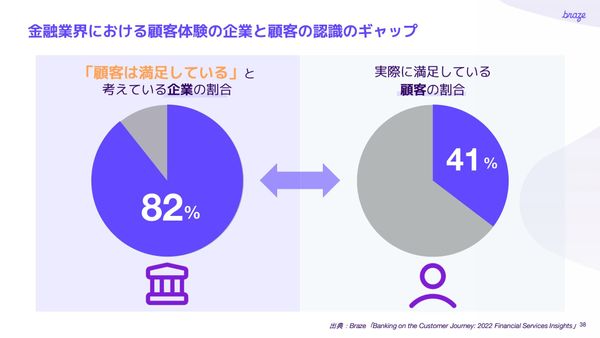
AIで激変する顧客体験──「金融機関」と「消費者」の関係を再設計 Brazeが描く“真の顧客エンゲージメント”とは
 PR
PR2025.11.28
金融機関の休眠顧客をアクティブユーザーへと転換 Brazeが提供する、収益改善を実現する「パーソナライゼーション」事例
 PR
PR2025.11.28
管理職に求めすぎる組織の限界 役割分割で生まれる新しいチーム運営
 PR
PR2025.11.27
「考えろ」と言うだけの上司が組織を壊す 自律型人材が育たない本当の理由
PR2025.11.27
数理最適化のエキスパートが断言「AIブームで見落とされがちな重要技術」 1,300社が導入した「演繹的AI」が意思決定を変える
PR2025.11.28
「あの人がいなくなったら仕事が回らない」を解決 属人的な業務から脱却する「最適化」の実践方法
PR2025.11.28
「計画と運用」をごちゃ混ぜにすると崩壊する ビジネスに使える最適化システムの“境界線”の引き方
PR2025.11.27
9割がリピーターでも“飽きられない”仕掛け 馬渕磨理子氏×オリエンタルランドが語る、体験価値と「成長の3本柱」
PR2025.11.28
“テーマパークの外”への挑戦で売上1兆円を目指す 馬渕磨理子氏が迫る、オリエンタルランドの新領域戦略
PR2025.11.28
物価上昇時代の“もう1つの収入源” 自己資本約10万円から始められる、不動産投資の仕組みとリスク解説
PR2025.11.27
AIで激変する顧客体験──「金融機関」と「消費者」の関係を再設計 Brazeが描く“真の顧客エンゲージメント”とは
PR2025.11.28
金融機関の休眠顧客をアクティブユーザーへと転換 Brazeが提供する、収益改善を実現する「パーソナライゼーション」事例
PR2025.11.28
管理職に求めすぎる組織の限界 役割分割で生まれる新しいチーム運営
PR2025.11.27
「考えろ」と言うだけの上司が組織を壊す 自律型人材が育たない本当の理由

