

 PR
PR2025.11.27
数理最適化のエキスパートが断言「AIブームで見落とされがちな重要技術」 1,300社が導入した「演繹的AI」が意思決定を変える
コピーリンクをコピー
ブックマーク記事をブックマーク
竹尾正馬氏(以下、竹尾):実際どうやって構築していったかを「How Did We Design It?」で説明していきます。まずScalebaseのアプリケーションは、こんなイメージです。依存性逆転の原則を適用して、上位レイヤーから下位レイヤーのみの参照を可能にしています。それぞれのレイヤーについて説明します。
Primary AdapterとSecondary Adapterは後々説明しますが、外部通信の役割を果たすものだと思ってください。アダプタ以下は、ユースケース層とドメイン層、共通ライブラリの層があります。プライマリアダプタを通してユースケースを実行し、ユースケース内でドメインロジックが呼び出されます。
DBとの接続などはセカンダリアダプタを通して行われますが、インターフェイスはドメイン上に定義されています。クリーンアーキテクチャを取っています。

プライマリアダプタとセカンダリアダプタです。プライマリアダプタは、アプリケーションを駆動させるアクターが呼び出すアダプタを指します。アダプタ自体はいくつでも用意でき、差し替えられます。
例えば、HTTPアダプタやバッチのアダプタ、あとはKinesisからコンシュームするためのコンシューマアダプタ。いろいろなアダプタがあります。それ以外にも、同じHTTPアダプタでもAkkaを使ったコントローラを作ったり、Play frameworkを使ったコントローラを用意して、それぞれのアダプタだけを差し替えたりもできます。ちなみに弊社はAkka HTTPを利用しています。
一方で、セカンダリアダプタはアプリケーションが駆動するアクターになるアダプタです。そこから情報を取得するか、あるいは通知するかを行うアダプタになっています。例えば、DBアクセスの文を記述します。ミドルウェアの実装によって、実装の差し替えができるという特徴で、MySQLからRailsに変更することが可能になります。

ここからが本題です。まず、モジュラモノリスを実現するためにsbtを使います。sbtを使って、モジュラモノリスのプロジェクトを用意していきましょう。もともとあったモノレポモノリスを分割していきます。先ほどのアプリケーションレイヤーを、縦にコンテキストごと分割するイメージで構築します。
ここにAuthZや、Subscription、Invoiceというコンテキストを例として出していますが、もともとあった横の層を、さらに縦に分割するようなイメージで、それぞれのコンテキストに対してsbtのプロジェクトを用意します。
それぞれのコンテキストごとに、前述したレイヤーを持っているので、InvoiceコンテキストもHTTPアダプタもいろいろなアダプタをもっています。セカンダリアダプタもあるし、ユースケースドメインも当然あります。

その次に、システムのエントリーポイントとして、モノリスアダプタを用意します。モノリスアダプタは、モジュラモノリスを可能にするための1つのTipsです。それぞれのコンテキストのプロジェクトを、モノリスアダプタに依存させるような構成を取ります。

なぜモノリスアダプタが、他のすべてのアダプタを参照しているかというと、デプロイユニットを1つにまとめるために存在しているのと、コンテキスト間の通信を実現するためにあります。後ほど詳しく説明します。モノリスアダプタは、各コンテキストを超えてシステムのエントリーポイントやDIセットをまとめる場所として存在していて、他の実装は一切書かないようになっています。

これが実際のbuild.sbtの一例です。モノリスアダプタに各コンテキストのアダプタを依存させるところは、こんな感じで書きます。この例は、各コンテキストのHTTPアダプタを依存するように記述しています。ここはHTTPアダプタの例だけを書いていますが、実際は他の通信プロトコルであっても、同じように依存させます。例えばgRPC、コンシューマ、Sparkもありえますね。バッチアダプタでも依存させることで記述していきます。

たったこれだけの記述で依存関係を定義でき、モジュールのコンテキストを作れます。コンテキスト境界を保ちながらデプロイユニットを統合することも簡単なんですね。sbtのプロジェクト分割の表現力はとにかく素晴らしく、非常に簡単にです。本当に助かっています。

内部のコンテキスト間の通信の方法を説明します。通信のインターフェイスは、ScalaPBというライブラリを使って自動生成されます。gRPC通信用のインターフェイスを利用します。ただ、モジュラモノリスでは、実際にはgRPC通信は使わず、単純な関数の呼び出しにDIを使って差し替えます。そのため、自動生成されたgRPC用のインターフェイスを使いますが、実際にはgRPCを使わないような工夫をしています。

共通のセカンダリアダプタに、Protocol Buffersでインターフェイスを定義します。ここも共通のセカンダリアダプタに配置することで、すべてのコンテキストから、定義されたインターフェイスが参照可能になっています。現状、Scalebase上ではContextAからContextBに通信しないといった、そういう制約は今のところありません。

これがProtocol Buffersの定義の一例です。例として、SubscriptionというコンテキストからInvoiceというコンテキストを通して、請求書のURLを取得するインターフェイスを記述しています。実際にはInvoiceのコンテキストを取得するための定義ファイルが書いてあり、Subscriptionのコンテキストから利用する説明をしていきます。ここまで、非常にシンプルです。

今話したProtocol BuffersはScalaPBというライブラリを通すことで、自動でScalaのケースクラスや関数インターフェイスを生成してくれます。RPCのインターフェイスを、我々はRemoteFunctionと呼称しています。RemoteFunctionの実装は、各コンテキストのgRPCアダプタに配置されます。

この矢印の先のgRPCアダプタに実装していきます。このアダプタは他のレイヤーや、同一のレイヤーの他のエントリーポイントからは参照できないようになっています。

RemoteFunctionの実装は各コンテキストのgRPCアダプタで行いますが、この図のコードはInvoiceコンテキスト内でインターフェイスの実装を行うときの例です。ここはfindUrlByBillingIdを実装することでデータが取得になる例で、例えば、リポジトリ経由でDBにアクセスし、データを取得することが考えられるかと思います。
この//Implementation should be here.のところに、実際にどうやってデータを取得していくかを書きます。このRemoteFunctionImplには、リポジトリ元ファンクションの実装を書いています。

gRPC通信を関数呼び出しに置き換えることを説明します。ScalaPBを使うことで、自動生成されたそのスタブ、クライアントにはgRPC通信の実装が入っています。これをそのまま利用するとgRPCを使った通信が可能なんですが、その実装を単純な関数呼び出しにオーバーライドすることで、実際の通信ではgRPCを使わずに済んでいます。
このコードの例では、自動で生成されたスタブを、関数呼び出しに変更するためにオーバーライドしています。findUrlByBillingIdのオーバーライドと思っています。オーバーライドしてRemoteFunctionを呼び出していますと。このクライアントを利用する側は、クライアントを叩くだけで通信を実施して、データを取得できます。
ここではわかりやすくオーバーライドと書いていますが、弊社ではRemoteFunctionが増えるたびにオーバーライドしなくても済むような工夫が、すでに取り入れられています。ちょっとここはボイラープレートになっています。

インターフェイスへの実装が完了したら、DIをする必要があります。モノリスコンテキストのみがコンテキスト境界をまたいで参照できることを伝えましたが、自動生成された共通セカンダリアダプタのインターフェイスに、gRPCアダプタに設置された実装を注入します。そうすると、スタブで呼び出した時に、先ほど書いた実装がgRPCアダプタで呼び出されます。
自動生成したセカンダリアダプタのインターフェイスに、gRPCで実装したものを注入することで、gRPC通信を呼び出さず関数呼び出しが実行されます。こんな感じで、自動生成されたRemoteFunctionのインターフェイスをモノリスコンテキストで実装をDIすると、実装したものが呼び出されます。

コンテキスト間通信を利用する側はSubscriptionコンテキストがInvoiceコンテキストを呼び出すとして、Subscriptionコンテキスト側はどうするかというと、自動生成された先のスタブを使います。スタブは、RemoteFunctionを呼び出すように変わっています。なぜかと言うと、関数呼び出しにオーバーライドされているからです。
RemoteFunctionの実装も完了しているため、サービス間の通信を利用した情報の取得や通知が可能になっています。この例では、Invoiceサービスに、SubscriptionコンテキストのSearchInvoiceServiceというクラスの実装をしていてSearchInvoiceService自体はドメイン層に定義されています。その実装をSubscriptionコンテキストのセカンダリアダプタでしている例になります。
ここの実装の中でinvoiceRemoteFunctionStubがありますが、これを呼び出すことで通信をします。

ここまで紹介した実装のクラスの配置は、このようなファイル構造になっています。小さくてごめんなさい。シェアードセカンダリに、Protocol Buffersを設置します。自動生成されたRemoteFunctionの実装は、InvoiceコンテキストのgRPCアダプタに設置します。
モノリスアダプタで実装の注入を行います。呼び出し元はドメイン層にあるインターフェイスで行うことで、DIされたセカンダリアダプタ経由でRemoteFunctionを呼び出し、コンテキスト間通信を実現しました。登場人物はいくつかいますが、こんな感じになっています。

次にデータベースです。データベースは、マイグレーションファイルをそれぞれのコンテキストに置いています。シンボリックリンクを使って1カ所に、この例で言うと、Monolith contextにファイル自体は集めています。1つのDBに対して1つのマイグレーションが実行されるようになり、この方法の場合、マイクロサービスの分割時にデータマイグレーションが必要になりますが、それ自体は許容しています。
図でいうと、contextBのマイグレーションファイルとcontextCのマイグレーションファイルを、Monolith contextにシンボリックリンクで置いているかたちです。

ここまでで、どうデザインしてきたかの話をしました。やってみてポジティブだった面を説明します。マイクロサービスに比べれば、かなり小さなスケールでスタートできますし、影響範囲も小さくできて、非常にいいかと思います。
ドメイン境界やドメインデザインの試行錯誤を議論しながら進められていて、ドメインのモデリングやその境界の定義が間違っていたら、修正することも比較的容易です。それが正しいドメインじゃないとか、コンテキスト境界を考えるのは非常にいい機会になっていて、僕らの考えとしては、この試行錯誤がもっとも大事であると考えています。

一方で、考慮すべきだったことや、やってみて難しいな思ったこと。コンテキストを分けないときに比べると、Protocol Buffersの定義や、呼び出し先の実装、DIなどやることが多く、ボイラープレートが多くなっています。そのため、自動生成などの改善は必要と考えています。
やはりスピードが大事なフェーズなので、時間がかかるのは、致命傷になりかねないと思っているので。改善が必要です。一方で、いくつかのボイラープレートはすでに取り除けている事実もあるので、今後も減らせる部分もあると思います。あとはDBを分けることがまだできておらず、DB分割も将来実施しないといけないな課題があります。

最後に、まとめとネクストステップです。モジュラモノリスはコンテキスト境界について考慮しながら、そして制約をかけながら開発できるいいソリューションの1つと言えると思います。マイクロサービスに比べると小さくトライできますし、ダメだと思ったら比較的簡単に止めることもできると思います。
Scalaを使っている我々にとっては、sbtとScalaPBが最高過ぎて、これを使うことで容易に実現できます。おそらく、どなたのプロダクトでも可能かなと思います。僕ら自身、まだこの取り組み自体は試行錯誤の途中なので、ドメインデザインも試行錯誤を続けています。
1回分割したコンテキストを再統合する可能性もありますし、モジュラモノリス自体を止める可能性もありますが、この“止められる”という選択肢をもつこと自体は、ポジティブかと思います。これを進めていき、マイクロサービス分割したほうが明らかに恩恵が大きそうなサービスが出てきたら、切り出したらいいかなとも考えています。前述した課題も引き続き残っているので、改善していきたいと思っています。

最後です。アルプでは、Scalebaseを一緒に開発したい方を大募集しています。僕自身、ドメインモデリングが会社のコアテクノロジーだと思っていて、複雑なドメインと向き合いたい方におすすめです。興味のある方は、お茶でも何でもさせてもらえればと思います。発表は以上です。ご清聴ありがとうございました。

司会者:竹尾正馬さん、発表ありがとうございました。質疑応答に移ります。1つ目は「Protocol Buffersのインターフェイスだけ使う場合でも、.protoファイルはフロント側でも便利に使える感じでしょうか?」
竹尾:この「フロント」というのは使う側なのかな?
司会者:たぶんそうでしょうね。フロントエンドかもしれない。
竹尾:今回の話でいうと、バックエンドのScalaのプロジェクト内の各コンテキストのシェアードの共通のセカンダリに置いてあるProtocol Buffersの定義があり、それをコンパイルすると、そのセカンダリ内にインターフェイスが生成されると。
ここで同時に生成されるスタブを、直接使う側の人たちは参照できるので。それをインポートして呼び出すだけなので、そういう意味ではフロント側でも便利に使えるというか、すぐに呼び出せるようになっています。フロント側が、別に何か同じようなものを定義しなきゃいけないことにはならないです。
司会者:次の質問です。「この全体的なアーキテクチャ、sbtにスタブ生成ツール、マイグレーションファイルの運用などの設計は、何名でどれくらいの期間で仕上げたのでしょうか?」。
竹尾:そうですね。ズルズルと考えていた経緯もあって、マイクロサービスや、常々コンテキストが分かれていないことに対する恐怖みたいなものを我々は持っていたので。「常に考え続けないといけないよね」ということで、けっこう議論はし続けていたと思います。
本格的に考え始めて実装自体は、たぶん1、2ヶ月ぐらいで運用は決めたと思っています。マイグレーションファイルはやってから気付いたみたいなところもあって、都度変えるというか、そのタイミングで変えたりしていました。その頃はバックエンドのエンジニアが7、8名だったと思うので、そんなにハイコストにやった印象はまったくなかったですね。
プロジェクトを分割する時のコスト・時間は多少大きなコミットになりましたが、それ以外はわりとスッとできましたね。
司会者:ありがとうございます。では、以上でセッションを終了します。ご視聴ありがとうございました。
竹尾:ありがとうございました。
続きを読むには会員登録
(無料)が必要です。
会員登録していただくと、すべての記事が制限なく閲覧でき、
スピーカーフォローや記事のブックマークなど、便利な機能がご利用いただけます。
すでに会員の方はこちらからログイン
名刺アプリ「Eight」をご利用中の方は
こちらを読み込むだけで、すぐに記事が読めます!
スマホで読み込んで
ログインまたは登録作業をスキップ
この記事をブックマークすると、同じログの新着記事をマイページでお知らせします
PR2025.11.27
数理最適化のエキスパートが断言「AIブームで見落とされがちな重要技術」 1,300社が導入した「演繹的AI」が意思決定を変える
 PR
PR2025.11.28
「あの人がいなくなったら仕事が回らない」を解決 属人的な業務から脱却する「最適化」の実践方法
 PR
PR2025.11.28
「計画と運用」をごちゃ混ぜにすると崩壊する ビジネスに使える最適化システムの“境界線”の引き方
 PR
PR2025.11.27
9割がリピーターでも“飽きられない”仕掛け 馬渕磨理子氏×オリエンタルランドが語る、体験価値と「成長の3本柱」
 PR
PR2025.11.28
“テーマパークの外”への挑戦で売上1兆円を目指す 馬渕磨理子氏が迫る、オリエンタルランドの新領域戦略
 PR
PR2025.11.28
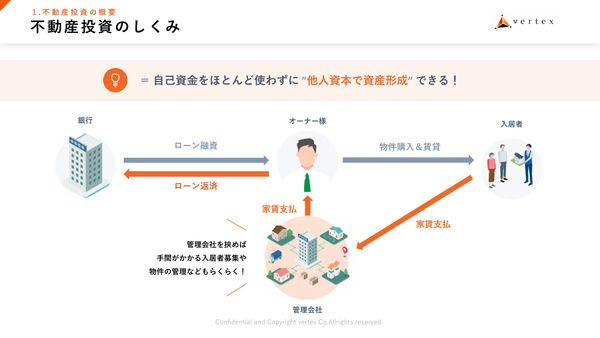
物価上昇時代の“もう1つの収入源” 自己資本約10万円から始められる、不動産投資の仕組みとリスク解説
 PR
PR2025.11.27
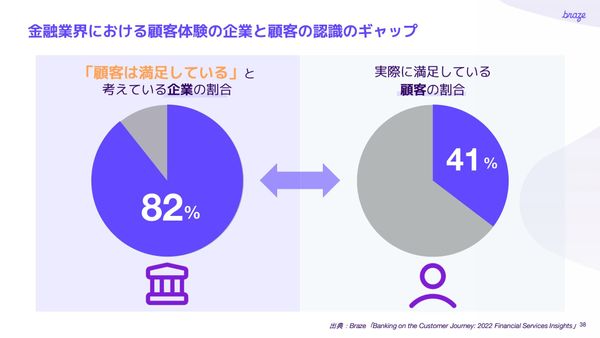
AIで激変する顧客体験──「金融機関」と「消費者」の関係を再設計 Brazeが描く“真の顧客エンゲージメント”とは
 PR
PR2025.11.28
金融機関の休眠顧客をアクティブユーザーへと転換 Brazeが提供する、収益改善を実現する「パーソナライゼーション」事例
 PR
PR2025.11.28
管理職に求めすぎる組織の限界 役割分割で生まれる新しいチーム運営
 PR
PR2025.11.27
「考えろ」と言うだけの上司が組織を壊す 自律型人材が育たない本当の理由
PR2025.11.27
数理最適化のエキスパートが断言「AIブームで見落とされがちな重要技術」 1,300社が導入した「演繹的AI」が意思決定を変える
PR2025.11.28
「あの人がいなくなったら仕事が回らない」を解決 属人的な業務から脱却する「最適化」の実践方法
PR2025.11.28
「計画と運用」をごちゃ混ぜにすると崩壊する ビジネスに使える最適化システムの“境界線”の引き方
PR2025.11.27
9割がリピーターでも“飽きられない”仕掛け 馬渕磨理子氏×オリエンタルランドが語る、体験価値と「成長の3本柱」
PR2025.11.28
“テーマパークの外”への挑戦で売上1兆円を目指す 馬渕磨理子氏が迫る、オリエンタルランドの新領域戦略
PR2025.11.28
物価上昇時代の“もう1つの収入源” 自己資本約10万円から始められる、不動産投資の仕組みとリスク解説
PR2025.11.27
AIで激変する顧客体験──「金融機関」と「消費者」の関係を再設計 Brazeが描く“真の顧客エンゲージメント”とは
PR2025.11.28
金融機関の休眠顧客をアクティブユーザーへと転換 Brazeが提供する、収益改善を実現する「パーソナライゼーション」事例
PR2025.11.28
管理職に求めすぎる組織の限界 役割分割で生まれる新しいチーム運営
PR2025.11.27
「考えろ」と言うだけの上司が組織を壊す 自律型人材が育たない本当の理由

