


 PR
PR2025.11.27
数理最適化のエキスパートが断言「AIブームで見落とされがちな重要技術」 1,300社が導入した「演繹的AI」が意思決定を変える
annbench: 近似最近傍探索アルゴリズムのベンチマーク(全1記事)
コピーリンクをコピー
ブックマーク記事をブックマーク
松井勇佑氏(以下、松井):東京大学の松井と申します。今日はベンチマークについて発表します。
東京大学の生産技術研究所というところで助教をしています。コンピュータビジョンや画像処理の研究をしています。とくに画像の検索とかその中のアルゴリズムの最近傍探索みたいなものをやっています。
最近では、2019年の夏にMIRU(ミル)という学会でチュートリアルをしまして、いろいろな最近傍探索手法をまとめましたサーベイ資料を作りました。今9.7kのビューがあるので、そこそこ見ていただいているのではないかなと思います。
他に最近やったこととしては、faiss(フェイス)があります。たぶん今日ご覧になっているみなさんはご存知の方が多いと思うんですが、Facebookが作っている強いライブラリの1つです。そこのwikiの最初のところに、サーベイ図みたいなものが載っているんです。ここは最近僕が書いて共有したものです。こういうのが、wikiに使われたりしている感じですね。
僕が話すのは、近似最近傍探索の話です。D次元のクエリベクトルがあったとします。このクエリベクトルに対してN個のデータベースベクトルがあるとします。そこに対してクエリから似ているものを探すという処理です。
これを式で書くと右のようになりまして、距離のargminを取って一番近いものを探すというような処理です。ここではユークリッド距離の2乗とかを使っています。ここでは74番目のベクトルが見つかったという感じですね。ここに書いてあるように、N個のベクトルがあり、クエリが与えられたときに一番近いものを近似的に探す。これはあくまで近似なので、速度とかメモリと精度のトレードオフになっています。

この近似最近傍探索は、画像検索とかにいろいろと使われるすごく基本的な手法で、たくさんある。ライブラリがたくさんあって、手法もたくさんあっていったいどれを選べばいいのかというのは、けっこう簡単ではないんですね。これはここのURLから持ってきたんですけど、パッと使える、Pythonで使えるものです。こんなにたくさんあるのです。なのでどうしようという話です。

(どのアルゴリズムを選ぶのかは)ベンチマークを使っていろいろと比較をしてみて、一番いいのを使うというのが基本になると思います。こういうベンチマークがあります(https://github.com/erikbern/ann-benchmarks)。このベンチマークは非常に有名なベンチマークで、とてもよく使われています。横軸が精度で縦軸が速度です。右上のほうがいいというグラフです。この1つの色が1つの手法に対応しています。
現在は、NMSLIBという有名なライブラリとヤフージャパンが作っているNGTというライブラリがトップを戦っている感じです。

このベンチマークは、網羅的で非常にすばらしいんですが、実はいろいろと問題がありまして……。ライブラリが大きくなりすぎてしまって、すべて実行すると10時間ぐらい掛かってしまうという問題があります。また、パラメータを網羅的に調べた結果なので、少し解釈しにくいということもあります。派閥が違う人たちが作っているので、このfaissに厳しいというところもあります。
といういろいろなことがありまして……。「じゃあ、新しいのを作ろう!」ということで、このannbenchという、シンプルで軽量なベンチマークを作りました。
実は今回、その宣伝のために来たという感じです。今回のML@Loftのページには、GitHubのリンクを貼っていますので、ぜひ使ってみてください。今回のこのスライドのリンクも貼ってあります。必要に応じてそちらも見てみてください。
このannbenchライブラリなんですが、左側が実際に行う作業です。非常にシンプルです。クローンしてきたあとにpip installでライブラリをインストールします。そしてダウンロードですね。download.pyと書いて、ここに書いてあるようにdataset=siftsmallみたいなこういう書き方で、データセットをダウンロードします。
そしてrun.pyとやると走ります。ここでもdataset=siftsmallというようにデータセットを指定します。アルゴリズムはalgo=annoyというように指定して実行できます。annoyは手法のひとつです。plot.pyとあるのは、その結果を可視化する・画像にしてくれるものです。これでうまくいきます。
こんな感じでできまして、こうすると右のようなグラフができます。これもさっきと同じく、右に行くほど精度が高い、上にいくほど速いというグラフです。このように左を実行すると右ができるという感じで、非常にシンプルなものになっています。

いろいろ工夫したところがあります。まず複数のデータセットで複数のアルゴリズムを試すことを簡単にできるようにしました。実験とかをやると無限にこうしたをやる機会があると思うんですが、今回はHydraというフレームワークを使っていて、そのおかげでけっこう簡単にできるんです。
最初の行はpython run.py。--multirunを付けて、「dataset=siftsmall,sift1m」というふうにカンマ区切りで指定します。すると、この2つのスクリプトを、「ダウンロードsiftsmall」「ダウンロードsift1m」というのを2回実行してくれます。という感じで簡単に書けます。
その次の行のrunも簡単に書けます。ここも2つのデータセットをカンマ区切りで書くことで両方のデータセットで実行する。アルゴリズムは右に4つ書いてありまして、このやつです。なのでここでは4×2で8通りのものを一発でやってくれるというものになっています。
このようにカンマで区切るだけでいいので楽です。その結果、これを1行実行するだけで右下のようにいろいろなアルゴリズムで試した結果を得ることができます。これは僕がすごいのではなくてHydraというライブラリがけっこうすごいという感じです。

パラメータ設定を実際にどうするのかという話なんですが、パラメータはすべて、このYAMLファイルに保存されています。今回のこのivfpqというアルゴリズムに関して言うと、この左のようなYAMLに記述しまして……。
これも簡単です。name、つまり名前を書くというのと、インデックスパラメータ、クエリパラメータを設定します。
インデックスパラメータは、この場合2つ書かれていて、1つ目がM=8かつnlist=100というパラメータです。これを使ってインデックスを1個構築します。データ構造を1個作成するということです。今回はもう1つあって、M=16というパターンもあるので、今回はインデックスを2つ作ります。
このそれぞれが右のグラフの色に相当していて、1つ目のパラメータセットです。M=8、nlist=1,000だと青いのです。n=16、nlist=1,000だと右の黄色いほうになります。こういうふうにインデックスを作る。
基本的にパラメータというのは、まずデータ構造を作るときのインデックスパラメータと、あとは検索をするときのクエリパラメータがあるので、クエリパラメータはこの下側で指定します。
この場合だと、このnprobeを1から16まで変更することで、各データ構造に対して5回計測するというのが右側に出ています。なのでこれは2×5で10回の試行があります。
これの思想としましては、クエリパラメータというのは本来たくさんあるかもしれないんですが、本来は1つであるべきだと思っていまして……。速度と精度のトレードオフを達成するパラメータが1つだと。それがここに書かれているとなっています。こういう感じで、要はYAMLを1つ書けばできるようになっています。

最後に、これもHydraの機能なんですが、インタラクティブにパラメータを上書きできるようになっています。
1つ目のやつは、普通に初期設定のYAMLを使うパターンです。アルゴリズムを選択してデータセットを選択すると、この前のスライドであったように5つのクエリパラメータでやってくれる。これが左のグラフです。
それもできるんですけど、そうではなくて、その場でパラメータを指定することもできます。それが2つ目の#Overrideと書いてあるものになります。ここでこういうふうに、コマンドラインからnprobeのパラメータをリストのように与えてあげるとこっちで実行することができて、その結果この下の右のグラフのようになります。
というわけで、これはけっこうその場で変えたりしてみたいというときには使えたりします。

これで以上となります。ここにもう1回GitHubのリンクを書いておいたので、ぜひスターをお願いします。ぜひ使ってみてください。これはまだできたばかりなので、いくらでもこれから増えていく予定です。データセットとかアルゴリズムに関してはプルリクエスト歓迎なので、ぜひお願いします。
また、探索の理論とか応用の研究に興味がある企業の方々であるとか……。私は大学の教員なので、学生の方々とかがもしおられましたらぜひお声掛けください。
発表は以上になります。
続きを読むには会員登録
(無料)が必要です。
会員登録していただくと、すべての記事が制限なく閲覧でき、
スピーカーフォローや記事のブックマークなど、便利な機能がご利用いただけます。
すでに会員の方はこちらからログイン
名刺アプリ「Eight」をご利用中の方は
こちらを読み込むだけで、すぐに記事が読めます!
スマホで読み込んで
ログインまたは登録作業をスキップ
この記事をブックマークすると、同じログの新着記事をマイページでお知らせします
PR2025.11.27
数理最適化のエキスパートが断言「AIブームで見落とされがちな重要技術」 1,300社が導入した「演繹的AI」が意思決定を変える
 PR
PR2025.11.28
「あの人がいなくなったら仕事が回らない」を解決 属人的な業務から脱却する「最適化」の実践方法
 PR
PR2025.11.28
「計画と運用」をごちゃ混ぜにすると崩壊する ビジネスに使える最適化システムの“境界線”の引き方
 PR
PR2025.11.27
9割がリピーターでも“飽きられない”仕掛け 馬渕磨理子氏×オリエンタルランドが語る、体験価値と「成長の3本柱」
 PR
PR2025.11.28
“テーマパークの外”への挑戦で売上1兆円を目指す 馬渕磨理子氏が迫る、オリエンタルランドの新領域戦略
 PR
PR2025.11.28
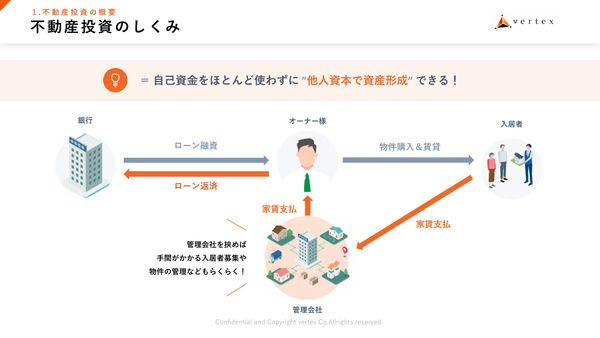
物価上昇時代の“もう1つの収入源” 自己資本約10万円から始められる、不動産投資の仕組みとリスク解説
 PR
PR2025.11.27
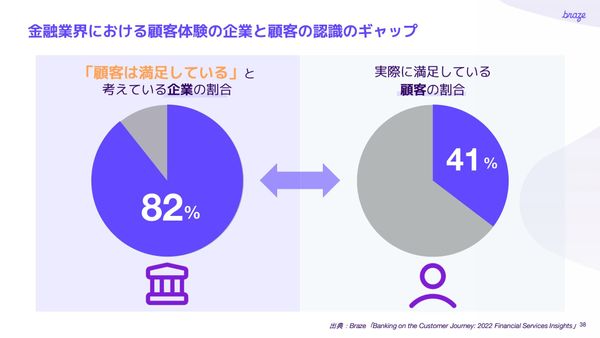
AIで激変する顧客体験──「金融機関」と「消費者」の関係を再設計 Brazeが描く“真の顧客エンゲージメント”とは
 PR
PR2025.11.28
金融機関の休眠顧客をアクティブユーザーへと転換 Brazeが提供する、収益改善を実現する「パーソナライゼーション」事例
 PR
PR2025.11.28
管理職に求めすぎる組織の限界 役割分割で生まれる新しいチーム運営
 PR
PR2025.11.27
「考えろ」と言うだけの上司が組織を壊す 自律型人材が育たない本当の理由
PR2025.11.27
数理最適化のエキスパートが断言「AIブームで見落とされがちな重要技術」 1,300社が導入した「演繹的AI」が意思決定を変える
PR2025.11.28
「あの人がいなくなったら仕事が回らない」を解決 属人的な業務から脱却する「最適化」の実践方法
PR2025.11.28
「計画と運用」をごちゃ混ぜにすると崩壊する ビジネスに使える最適化システムの“境界線”の引き方
PR2025.11.27
9割がリピーターでも“飽きられない”仕掛け 馬渕磨理子氏×オリエンタルランドが語る、体験価値と「成長の3本柱」
PR2025.11.28
“テーマパークの外”への挑戦で売上1兆円を目指す 馬渕磨理子氏が迫る、オリエンタルランドの新領域戦略
PR2025.11.28
物価上昇時代の“もう1つの収入源” 自己資本約10万円から始められる、不動産投資の仕組みとリスク解説
PR2025.11.27
AIで激変する顧客体験──「金融機関」と「消費者」の関係を再設計 Brazeが描く“真の顧客エンゲージメント”とは
PR2025.11.28
金融機関の休眠顧客をアクティブユーザーへと転換 Brazeが提供する、収益改善を実現する「パーソナライゼーション」事例
PR2025.11.28
管理職に求めすぎる組織の限界 役割分割で生まれる新しいチーム運営
PR2025.11.27
「考えろ」と言うだけの上司が組織を壊す 自律型人材が育たない本当の理由

