【3行要約】・「ハイパフォーマーと同じタイプを揃えれば勝てる」という安易なデータ活用は、組織の多様性と変化対応力を奪い、長期的には「一様化」という致命的なリスクを招きます。
・人材研究所の代表・曽和利光氏は、AIが過去の偏ったデータを学習し、特定の属性を排除し続ける「統計的差別の自己成就」や、アルゴリズムのブラックボックス化に警鐘を鳴らします。
・人事に求められるのは、データを「絶対的な正解」と過信せず、常に違和感を持ちながら検証を繰り返す「仮説検証の習慣」と、人間の納得感を引き出す説明責任の両立です。
前回の記事はこちら ハイパフォーマーだけ集めてもうまくいかない理由
曽和利光氏:2つ目なんですけど、(スライドを示して)今度は多様性と創造性の影響というのも、データドリブンな人事に関して問題じゃないかと言われているところですね。

データによって判断するってなると、ものすごく純粋なゼロイチの判断みたいな感じになっちゃうんですね。分析結果に従って機械的に人や組織をいじることで組織が純化、一様化してしまうと。
例えば、さっきクラスター分析して、1型、2型、3型、4型とかありましたよね。もし結果として「3型の人はハイパフォーマーばっかりだ」みたいな表示が出たとすれば。素朴に考えたら「じゃあ、3型の人ばっかり集めればいいじゃん」みたいに思いますよね。ところがそれがいいのかってことです。
昔の話になりますけど、野球の巨人が他の球団の4番バッターばっかりトレードで集めて、1番バッターから9番バッターまでみんな4番を作っても意外と勝てなかったとか。サッカーで、ものすごいスター選手というかフォワードみたいな点取り屋ばっかり集めたってダメなわけですよね。やはりそれぞれの役割があると。
ミドルパフォーマーだからダメ、極端に言ったらローパフォーマーだからダメではなくて、その人たちにも役割があるかもしれない。なのに3型がハイパフォーマーってなったらそればっかりでやってしまうと、多様性が薄れてしまう。それによって、創造性とか変化対応力……変化対応力っていうのは例えばこの環境だと、今の環境だから3型がいいと。
だけどまた別の環境だったら別のタイプが良くなるってことありますよね。つまり平時に強い人と乱世に強い人っていうのがあるじゃないですか。そういったものが、もしかしたらあまりにもデータばっかりによって、判断を極端にしていくことで、対応できなくなるんじゃないかということです。
組織には「適切なランダムさ」がある
多様性っていうのも、とにかくランダムにいろんなものがあればいいかっていうとそうでもないと思うんですね。世界はランダムかもしれません。でも、会社・組織っていうものは、適切なランダムさがあると思います。
人材ポートフォリオって言葉はよく使われますけど、こういうタイプの人は何パーセントぐらい欲しいっていうふうに、意図的にこういう構成にしたいっていうのを計画的に作っていくことが必要だと思います。
ですからこの多様性に関しては、人材ポートフォリオマネジメント、先ほど言ったように、どんなタイプを何パーセントっていうのを意図的に作っていくのが大事なわけですけど。それがまず、できるかどうかっていうことも大事ですね。
意図した多様性を精緻に作れるように、ピープルアナリティクスを用いることもできると思うんですけど、これができているところがどこまであるんでしょうかということです。
ただちなみに、おもしろい情報というか、迷っちゃう情報かもしれませんが、多様性=創造性の源みたいなことを、今ぱらっと言っていましたけど。いろんなエビデンス、研究を見ていくと、決定的な証拠が出ていません。
ダイバーシティ、多様性の高さっていうのは、イノベーションの優位な正の関係を持つという研究もあれば、ダイバーシティっていうのは、イノベーションの優位な負の関係を持つと。つまり、一貫した結果が得られていないということですね。
ダイバーシティとの企業業績の関係は実証されていない
考えればわかると思うんですけど、要は違う人たちがいっぱいいると、そのぶんコミュニケーションコストもかかるわけです。マイナスになる場合もあれば、それが良いって場合もあります。だからダイバーシティとの企業業績の関係っていう、思いっきり実証されているわけでもないという感じです。
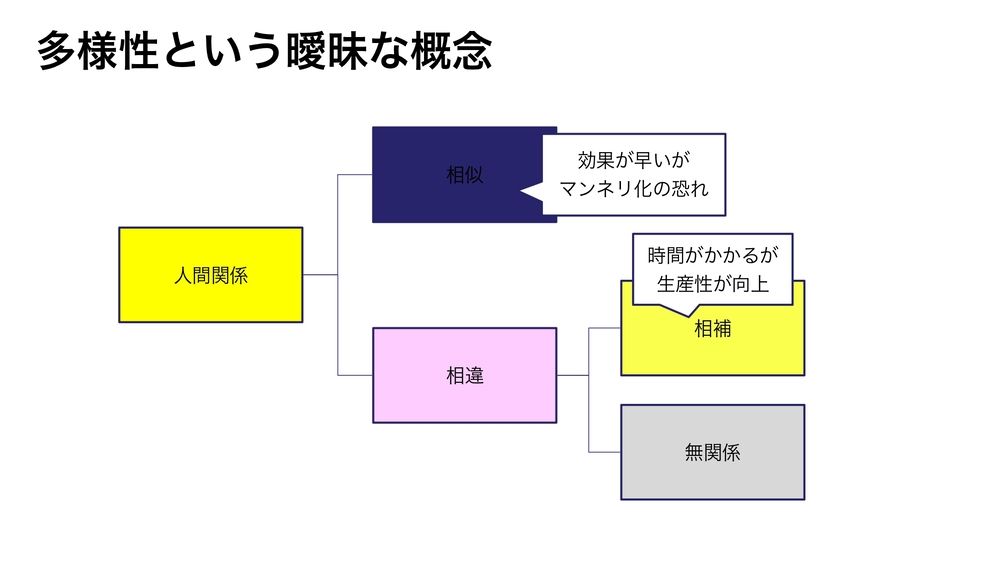
なんでこんなことになっているのかというと、多様性が、曖昧すぎるのかなと思っています。例えば、似てる・似ていないっていうのがあっても、似ていない中でも補い合う関係と、本当に似ていないだけで潰し合うような関係って違いますよね。
それを1つ、ダイバーシティっていう度合いで、測ってしまっているので、先ほど見たような、多様性が創造性とか生産性につながるかっていうのは、わからないってなっているのかなと思います。
これは学者さんにきちんと検証していただければと、思っているんですけど。素人仮説ですが、私が思うには、本当は似ているっていうのは、そのコミュニケーションコストが減って生産性が高まる。ただマンネリ化で創造性が低いかもしれない。でも、違うってやつも、この無関係は最悪なのかもしれませんけど。
補完関係にある場合は、ちょっとコミュニケーションコストがかかるけど、そのうち違うもの同士が集まることによって、新しいものを生み出すためにはものすごく創造性を高めるんじゃないかとか。
こういう結果を、きちんとこうやって、単にダイバーシティっていう多様性じゃなくて、どう多様さなのかっていうのをきちんと見ていけば、そういう結果が出るんじゃないかなと、今のところ思っています。
合否判定にAIを活用することへの批判
3つ目ですね。(スライドを示して)倫理的な問題。これは先ほど言いましたけど、結局なんでも、科学的にできるからと言ってやっていいかっていうと、そういうもんではないということです。

2つほどここで挙げたいのは、まず統計的差別と自己成就性。難しい言い方なんですけど、後で解説します。差別をむしろ、生み出してしまう可能性があるんじゃないかっていう問題です。
次が、納得度。データドリブンな人事評価、人事判断にさらされる側の納得度の問題ですね。これに書いていますけど、適性検査よりエントリーシートのほうがいいっていう人、未だに多いですね。AIで裁かれるのが嫌だっていう人も一定数いると。
だいぶ変わってきていますけどね。……みたいなところをこれからどう乗り越えていくのかっていうのが重要な問題になってくるということです。
まず1つ目、統計的差別の自己成就っていうのがいったい何かということなんですけど。例えばこれ、昔の例で、それぞれ改善はされていると思うんですけど。(スライドを示して)このGoogleのアルゴリズムの出力にバイアスがあったっていうことですね。例えばアルゴリズム、AI、あるいはデータドリブンで、いろいろものすごいやっているわけですけど。
画像検索で「hands」とか「Babies」を検索すると白人の画像ばっかり表示されるとかGoogleフォトで黒人の男女の写真に「ゴリラ」っていうタグをつけてしまうとか、ぐちゃぐちゃな状況っていうのが昔はあったんですね。もうだいぶ精度が上がっているかもしれません。
ただもちろん今のところ完璧ではなくて、似たような、そこまでひどいものはなかったとしても、今でもあるかもしれない。
これも昔の例ですけど、AmazonさんがAI採用をやっていた時に、教師データとして学習した履歴書のパターンが技術職のほとんどが男性だったということで、男性のほうが技術職、エンジニアとしてはいいんだと学習してしまったが故に、AI自身が女性差別をしていたみたいなことですね。





 PR
PR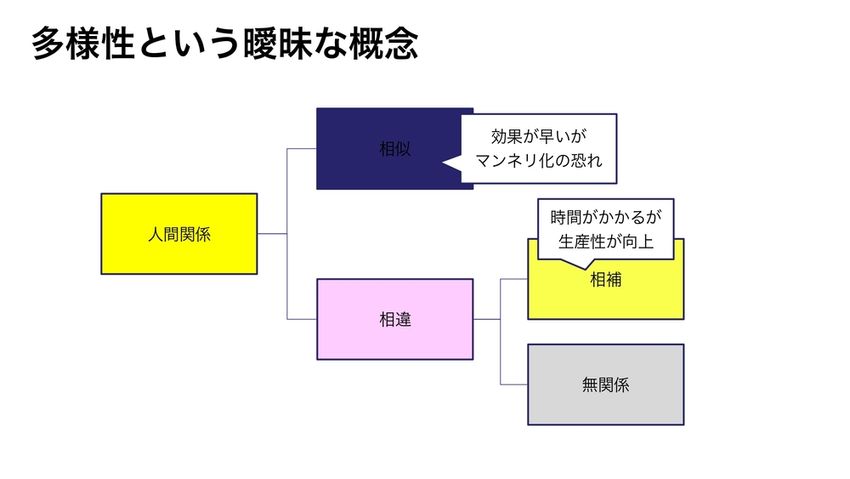
 PR
PR PR
PR PR
PR PR
PR PR
PR PR
PR PR
PR PR
PR PR
PR
