
 PR
PR2026.04.07
若手社員の7割が「管理職になりたい」を選ばない 調査でわかった課題と打開策
コピーリンクをコピー
ブックマーク記事をブックマーク
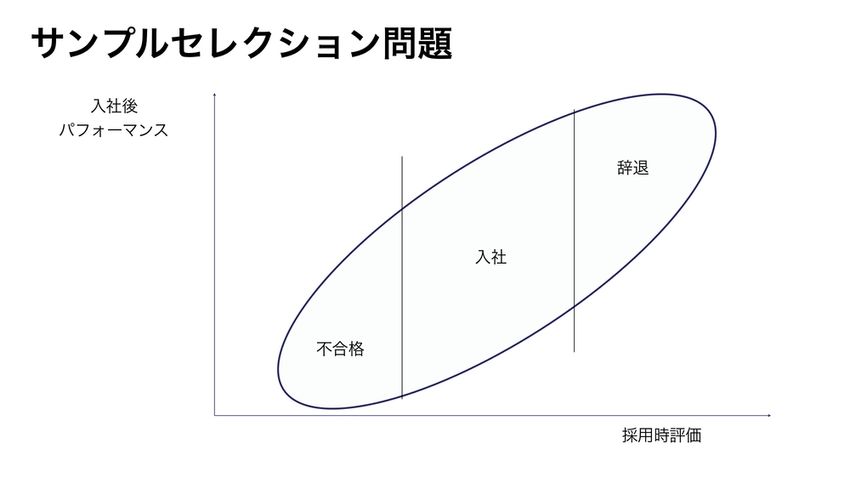


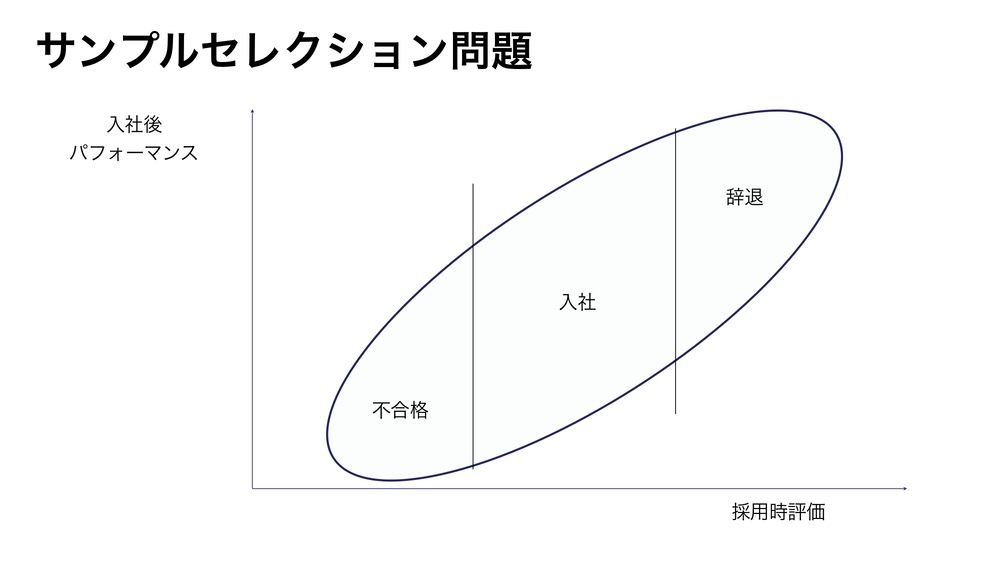
続きを読むには会員登録
(無料)が必要です。
会員登録していただくと、すべての記事が制限なく閲覧でき、
スピーカーフォローや記事のブックマークなど、便利な機能がご利用いただけます。
すでに会員の方はこちらからログイン
名刺アプリ「Eight」をご利用中の方は
こちらを読み込むだけで、すぐに記事が読めます!
スマホで読み込んで
ログインまたは登録作業をスキップ
この記事をブックマークすると、同じログの新着記事をマイページでお知らせします

2026.03.13
マネージャーの仕事は「管理」ではなく「なんとかする」こと 伊藤羊一氏が語る、37年のビジネス人生で見えたマネジメント論

2026.03.16
「サボっていると思われないか」を過剰に気にする社員たち 仕事とは「作業をすること」ではない

2026.03.17
コカコーラの管理職は「自分の後任者」を2〜3人育てている 優秀な人が辞めてもチームが回るマネジメント術

2026.03.17
組織に属しているけど「協働しない人」の問題点 共通の目的を目指して「肩を組む」重要性
2026.03.19
うまくいったらご褒美、失敗したら罰…「指示待ち社員」を増やす組織の仕組み 社員の自主性がなくなる逆効果な施策
PR2026.04.07
若手社員の7割が「管理職になりたい」を選ばない 調査でわかった課題と打開策
 PR
PR2026.03.24
「成果より努力を評価してほしい」 Z世代新入社員に広がる“プロセス重視”の背景
 PR
PR2026.03.25
新人の配属1〜3ヶ月目は「自信がなくなるフェーズ」 部下のタイプ別育成アプローチ
 PR
PR2026.03.16
製造業の6割が警戒する自然災害 予期せぬリスクで事業を止めないための「BCP×保険」の現実解
 PR
PR2026.02.26
メール共有しても二重対応や漏れ・・・ コールセンターの悩みを解決する「楽楽自動応対」の4つの機能
 PR
PR2026.02.27
「印象評価」からの脱却 経営層や現場を巻き込む“タレントマネジメント”の正しい進め方
 PR
PR2026.02.27
人事と現場が抱える「3つのズレ」とは 組織の成長を加速させる「タレントマネジメント」活用術
 PR
PR2026.01.19
業務フローを変えずに、メール1通3分を削減 自動でAIにナレッジが貯まる問い合わせシステム「楽楽自動応対」
 PR
PR2026.01.26
新規開拓でBtoBマーケターが直面する2つの課題 アポ獲得コストを2分の1にする、楽楽メールマーケティング活用法
 PR
PR2026.01.08
入社4年目の社員が“暗黒のExcel時代”を改革 売上金額2倍、年間110万円のコストカットを実現した方法
PR2026.04.07
若手社員の7割が「管理職になりたい」を選ばない 調査でわかった課題と打開策
PR2026.03.24
「成果より努力を評価してほしい」 Z世代新入社員に広がる“プロセス重視”の背景
PR2026.03.25
新人の配属1〜3ヶ月目は「自信がなくなるフェーズ」 部下のタイプ別育成アプローチ
PR2026.03.16
製造業の6割が警戒する自然災害 予期せぬリスクで事業を止めないための「BCP×保険」の現実解
PR2026.02.26
メール共有しても二重対応や漏れ・・・ コールセンターの悩みを解決する「楽楽自動応対」の4つの機能
PR2026.02.27
「印象評価」からの脱却 経営層や現場を巻き込む“タレントマネジメント”の正しい進め方
PR2026.02.27
人事と現場が抱える「3つのズレ」とは 組織の成長を加速させる「タレントマネジメント」活用術
PR2026.01.19
業務フローを変えずに、メール1通3分を削減 自動でAIにナレッジが貯まる問い合わせシステム「楽楽自動応対」
PR2026.01.26
新規開拓でBtoBマーケターが直面する2つの課題 アポ獲得コストを2分の1にする、楽楽メールマーケティング活用法
PR2026.01.08
入社4年目の社員が“暗黒のExcel時代”を改革 売上金額2倍、年間110万円のコストカットを実現した方法
2026.03.13
マネージャーの仕事は「管理」ではなく「なんとかする」こと 伊藤羊一氏が語る、37年のビジネス人生で見えたマネジメント論
2026.03.16
「サボっていると思われないか」を過剰に気にする社員たち 仕事とは「作業をすること」ではない
2026.03.17
コカコーラの管理職は「自分の後任者」を2〜3人育てている 優秀な人が辞めてもチームが回るマネジメント術
2026.03.17
組織に属しているけど「協働しない人」の問題点 共通の目的を目指して「肩を組む」重要性
2026.03.19
うまくいったらご褒美、失敗したら罰…「指示待ち社員」を増やす組織の仕組み 社員の自主性がなくなる逆効果な施策
