【3行要約】・キャリア開発では従来型の「スタティックデータ」に限界があり、個人の変化に対応できないという問題が長らく存在していました。
・田中研之輔氏は、AIによるパーソナライズドなコンディショニングデータ取得が可能になり、キャリア開発の革新が始まったと指摘。
・企業は組織エンゲージメントからキャリアエンゲージメントへと視点を転換し、データドリブンなキャリア開発で超少子高齢化社会に対応すべきです。
前回の記事はこちら 「キャリア開発はデータ不足だった」
田中研之輔氏(以下、田中):はい、栗原さん、ありがとうございます。私も冒頭からずっと聴いておりまして、非常にまとまっていてわかりやすく、今の、そしてこれからの我々が取り組むべき課題をシャープにまとめていただいたと思っています。栗原さんと、そしてみなさんと、課題を共有しながら考えていきたいなと思っています。
栗原さんのバトンを受けて、最初の入り口として、今何が起きているのかを私からお伝えしていくと、今までキャリア開発は一辺倒でした。
これ、言い方を変えると、例えば一括採用で新人研修をやったらプロジェクトは一緒でした。あるいは階層別で、ミドルシニア向けなど、それぞれの階層・ターゲットに向けて同じコンテンツを届けてきました。
その時に起きてきたのは、ある種主観的なフィードバックでした。プログラムが統一でそれぞれ属人的なフィードバックをしていたので、人材開発領域において決定的にデータがなかったというのが問題でした。
「データがなかった」とお伝えすると、「ありましたよね?」とおっしゃる方がいます。確かにありました。それは何かというと、スタティックデータなんですね。パーソナリティ診断、MBTI、ストレングス・ファインダーなどです。
例えば田中さんとか栗原さんがいて、それぞれの持っている強みとか、変わりにくいもの、特性、パーソナリティ、性質などのデータはありましたが、それはターゲット化されたグループを分類する時に使いやすいデータでした。
例えば、キャリア開発なら、「田中はこういうマインドセットやグローススキルを持っているので、新規事業開発に向いていますね」とか、「栗原さんはこういう経験があるから経営企画に向いているよね」とアサインをする。
人事におけるアサインは、できるだけ主観的にやらないようにしなきゃいけないという反省があったのでデータを取り入れたんだけど、そのデータはスタティックだった。
AIでパーソナライズドなデータが取れる
田中:このAIによってパーソナライズドコンディショニングデータが取れます。フィードバックもできます。つまりAIは、業務の効率化、あるいは改善化、あるいは生産性や競争力の改善といったスキームのみならず、我々の人的資本の能力開発の、まさにディベロップメント側面に寄り添ってくれるんです。
栗原さんのお話にもあったように、我々一人ひとりの性質ではなく能力を上げていく。例えば筋力トレーニングと一緒で、じゃあ、50キロ上げられるという人が10人いて、55キロ上げられるようにする時って、ぜんぜんアプローチが違うわけだよね。重いのを持たせれば55キロが上がるようになる人もいれば、もう少し小さな筋肉の張り具合を作っていくと上げられる人もいる。
私は5年前から医療の予見医療と、アスリートのトップパフォーマンス分析、これが2つ抜けていると(考えていました)。キャリア開発はここが遅れているということで追いかけてきたんです。
今回、キャリア開発診断、60設問を独自開発して、今ミニマムで1万人ぐらいのデータがそろってきていますが、今、栗原さんがオープニングでおっしゃってくださったところで、栗原さん、この28ページをちょっと一緒に見ましょうか。
栗原和也氏:(以下、栗原):28ページ。はい。
2軸×4象限で「組織の状態」をゾーンとして可視化する
田中:4象限の図があるところかな。グロースゾーン、チャレンジゾーン。これは組織における、例えば2:6:2と整理されたんですが、これを我々は2軸の4象限でやっているので、ゾーンで組織を可視化することができます。
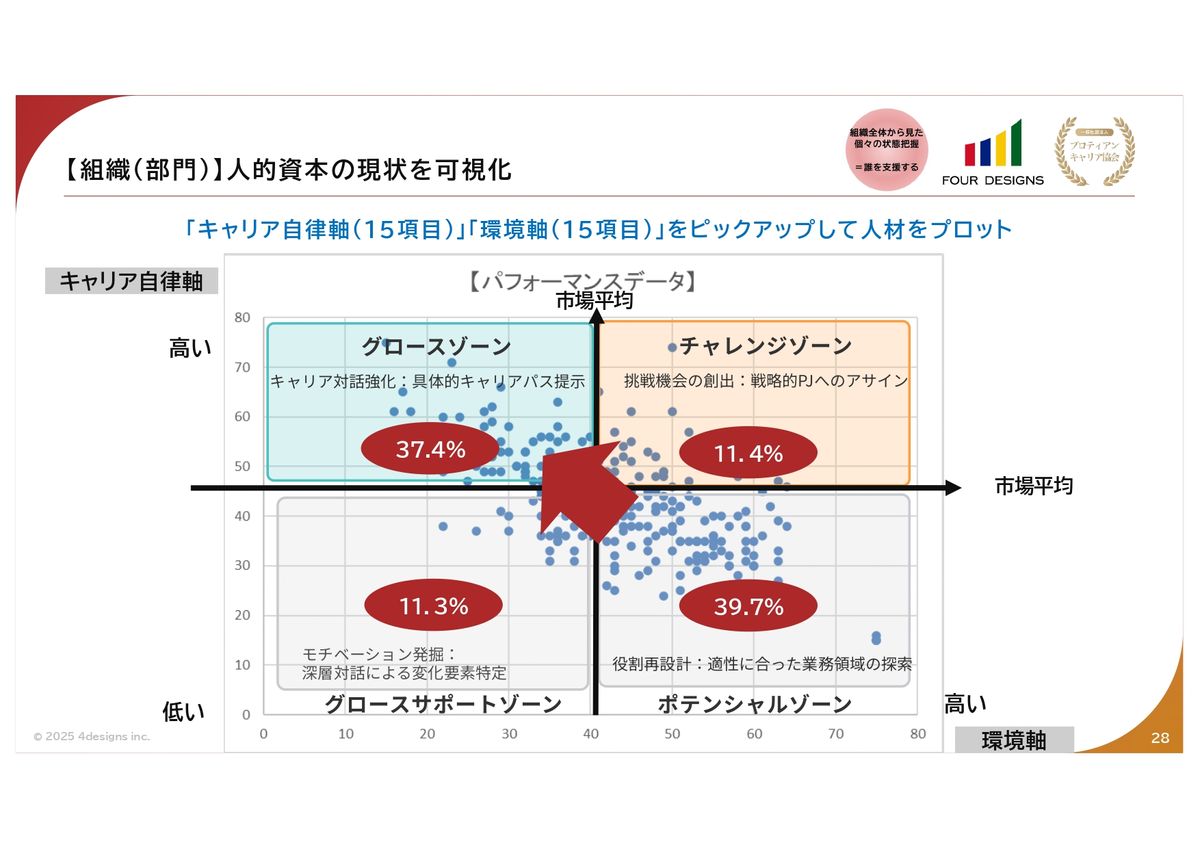
一人ひとりのデータに寄り添うこともできるし、チームストレングスも把握することができます。例えば、商社でエネルギーの部署に300人のメンバーがいます。その時に中を開けてみて分析していくと、どこにいるのかがわかるんだよね。グロースゾーンなのか(グロース)サポートゾーンなのか、このあたりをしっかり分析していくことができる。
なので、外付けの知識ではなくて、内側からの必要なグロースデータ、あるいはグロースアプローチに取り組めるようになってくるということだよね。当然、望ましい方向へと導けばいいので、データがあれば客観的に、そしてより的確な、もっと言うならば最適化したデータを届けていくことができる。
開示できない項目もあるが「6カテゴリー設問」で重要領域を抽出する
田中:30ページ。ある種特許的でもあるので、カテゴリー分析のところの内容項目は、ここの平場でみなさんに丸ごとお見せすることができないんですけど。

6カテゴリー設問というのは、これからのキャリア開発にとって欠かせない、キャリア資本とか、あるいはここに置いてある自己理解力とか、変化適応力とか、必ずここが必要ですねというところを抽出できるようにしました。
例えば25歳の若手、女性、前職経験がある・なし……等々入れて抽出もできます。4designs株式会社とプロティアン・キャリア協会は、ある種ソフトデータに寄り添っていくと。
追うのは「スタティック」ではなく、変化に寄り添うソフトダイナミクス
田中:個人のソフトダイナミクスデータ、個人が変わりゆく。ハードスタティックデータじゃなくて、ソフトダイナミックデータを追いかけていくことができる。
これは従来型のパルスデータと何が違うんですか、あるいはエンゲージメントデータとどう違うんですかというと、変化の機微に寄り添っていけるからやはり違うんだよね。
僕も「日本の人事部」で連載しているのでそこで触れさせていただいた時ので言うと、例えば四半期で取っていく時の、同じ設問群でパルスであったとしても、スタティックデータをもとにしたら何が起きるかというと、その性質がどう変わったかでしかないんです。
エンゲージメントデータも、組織コントリビューションのデータ抽出に過ぎない。非常に大事なのは、「どう変わっているのか? どう変わっていくのか?」ね。
「刺さった研修」を持続させるためにAIコーチングを使う
田中:資料の20ページを映していただいて……行動する新人が38パーセントから80パーセントに増加したというのは、かなり効果的なプロジェクトを動かせたということで、つまり、平たく言うと、この研修は刺さったんですよね。
これぐらいの変化が起こり得るよということを把握できる。そして、これに甘んじることなかれと。つまり、80パーセントのデータが持続するという理想論を掲げるんじゃなくて、持続させ続けていくために、AIやAIによるキャリアコーチングを使う。
あるいはリアルのキャリアコンサルタントとか、4d(4designs株式会社)、あるいは(プロティアン・キャリア)協会にも、プロティアン・メンターやプロティアン・ファシリテーターが、500名、600名というふうに全国各地で活躍してくださっていますが、みんなでより良い状況を作っていく。
制度も技術も「キャリア開発を盛り上げる土壌」が揃い始めた
田中:少しダイアログの中で長くなっちゃっていましたが、今どういう状況で考えているかというと、ようやくキャリア開発をみんなで盛り上げていける土壌が、制度的にもテクノロジー的にも、いわゆる企業が求める中計の戦略スキームの中でも一つひとつのパズルがはまってきたのが2025年の師走かなと思っていて、すごく希望的観測を持っています。
実は、プロティアンを届けなきゃって思った時は、70歳の雇用の努力義務が始まったりしていました。あるいは超少子高齢化と言われる中で、『
LIFE SHIFT』のリンダ・グラットンなんかは、「とはいえ、ペシミスティックになるな」。つまり「悲観的になり過ぎないでくれ」と言っています。
つまり、「日本社会というのはグローバルで見た時に、超少子高齢化が進むロールモデルである」と。「だから、長寿化する我々のモデルを出してください」と序文で書いているわけじゃないですか。
だから、我々がそのお言葉に返信するのであれば、「整ってきていますよ」と。つまり、長寿化する社会というのは、役割や働きがい、そしてそれぞれのパフォーマンスを5年、10年働いていって停滞するんじゃなくて、5年、10年働いていく中で、より最適化させて、より働きがいを高めながら、心理的幸福度を高めていく。
「組織エンゲージメント」から「キャリアエンゲージメント」へ
田中:そしてエンゲージメントは、私、2026年1月に『
キャリアエンゲージメント: ミドルシニアの自律と越境』という、電通にいらっしゃる桝中(美佐)さんと共著で書いたものを出版しますが、組織エンゲージメントからキャリアエンゲージメントへと(変わっていく)。
このキャリアエンゲージメントというのは、組織の中のエンゲージメントではなくて、まさにプロティアン・キャリアで言ってきた、「キャリアをより良いものにしていく舞台が組織である」です。だとすると、組織エンゲージメントっておかしくないかと。主役は本人だから、キャリアに寄り添う本人が、誰に、どの組織に、どのチームにエンゲージメントしていくのかという。
つまり、組織エンゲージメントからキャリアエンゲージメントへ変化してきており、それを本にまとめましたが、全部このあたりが連動するかたちで、かつデータドリブンでいきたいということが実現するようになってきたということです。
データバンクを「3万〜10万人規模」へ
田中:今日参加されているのは人事や経営者の方が多いと思います。あるいはこれが録画で公開されていった時に見てくださる方が多いと思うんですが、どうかみなさんの組織のキャリア状態を可視化していって、ソフトダイナミクスデータをみんなで共有してください。
今、(データとして溜まっているのは)1万人ですが、およそ2026年、ミニマムで3万人、もしくは5万人、願わくは希望的数字で言えば10万人ぐらいのデータが溜まっていけば、キャリア開発におけるデータバンクとして一定程度の客観的な数値を発揮できるようになると思います。
だから我々が目指しているのはみなさんと一緒です。超少子高齢化の中でもAIが伴走してくれて効率化もキャリア開発も共にやってくれるわけだから、一人ひとりが停滞している世の中って超少子高齢化の中ではあまりにももったいない。
AIで「誰でも4〜5倍」の生産性へ、という見立て
田中:いっとき、私が収集したキャリアに関するデータを因子分析して導き出したのはプレAIの時、いわゆるDX化の中で2.7倍でした。1人は2.7倍、テクノロジーによって生産性を発揮できるという数字を出していたんですけど。
今みなさんがAIを使うと、「生産性ってどれぐらい向上できるの?」というと。可処分時間計算とか、いわゆるアウトプットプロダクト計算でもいいんですけど、そういうのをやっていくと、まだしっかりした数値はみなさんにお届けできないんですが、たぶん4倍とか5倍ぐらいの生産性を誰でも発揮できるようになるところまで来ていると思います。
定性的な事例でお伝えするんだったら、法政大学の教員だよね。教員だけど、会議やゾーン科目群も持っているんですよ。専門科目群も持っているけど、「じゃあ、50年前の教員がこういう働き方をできたかな?」というと(違います)。
例えばSlackで卒論を読んで、学生たちにも生成AIをしっかりリライティングに使ってもらって、より良いものを使いながら走っているので、2025年の働き方は激変しているわけ。
なので、本当に悲観的には思っていなくて、こういう状態の中でより良いキャリア形成をみんなでしていきたいなという思いが一層高まっている、あるいは深まっているこの頃を過ごしています。
栗原:今まさにおっしゃっていただいた「みんなで作っていく」って、私、2019年以来のタナケン先生ファンの1人ではありますけれども(笑)。やはりみんなで作っていくって、もう当初からずっと言っていただいているなって思っています。


 PR
PR





 PR
PR PR
PR PR
PR PR
PR PR
PR PR
PR PR
PR PR
PR PR
PR
