事例:クラウドにアップされた画像から、口臭を判定
西尾敬広氏:これは消費財メーカーであるライオンさんの事例です。「NONIO」という口臭ケア商品がありまして、その販促ツールで「NONIO MIRROR」というサービスがあります。みなさんもぜひご利用いただければと思います(笑)。
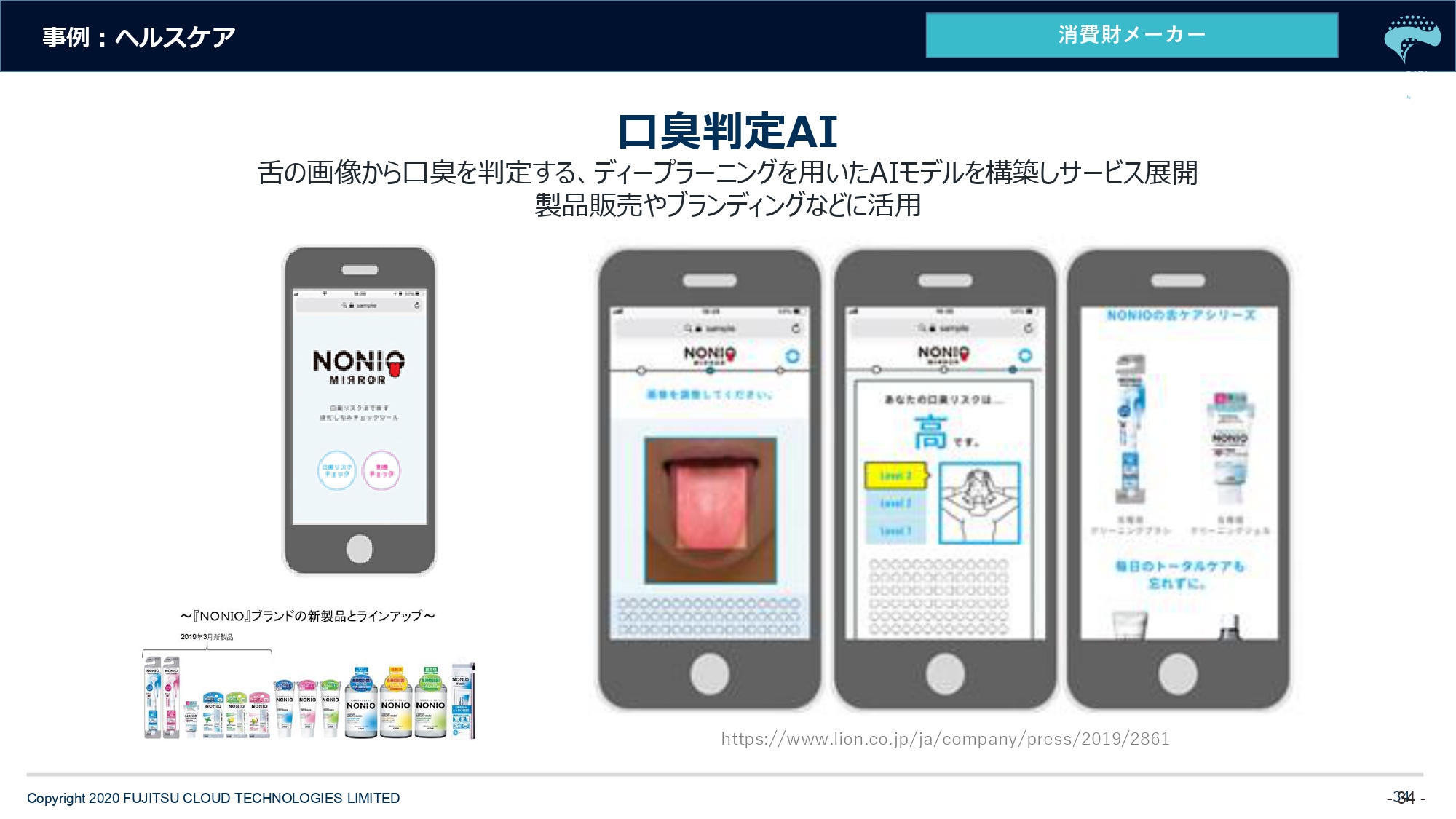
舌の画像をスマホで撮りクラウド側でその画像を解析し、みなさんの口のニオイのレベルを判定してくれます。その口臭判定アルゴリズム(AI)を私どものほうで開発し、ご提供しています。
これも人が見ようと思えば見られますし、わかる人が見たら「この人は臭い」とか「この人は臭くない」とわかるそうなんですけど、まさかクラウドに上がってきた無数の画像を人が見るわけにいきませんし、精度を上げていくために人工知能を使ったという事例になります。
ヘルスケアの分野ではありますが、これはあくまで販促の事例でして。ニオイの判定レベルが悪かった人に対して、じゃあ「NONIOのこの製品を買いましょう」という感じでECサイトへ誘導するなどしています。ブランディングとプロモーションの事例として、こんなところでも使われています、ということでご紹介しました。
事例:AIが物件の家賃を決定
次は業務バリバリのところですけども、不動産の事例です。すでにプレスリリースされているのでお名前を申し上げられますが、大東建託さんという会社さんです。日々入ってくる物件に対して、人がいろいろなところのデータを引っ張ってきて、不動産鑑定士とかそういう人にも聞いて「この物件は家賃●万円」という値決めをやっているらしいんですけど。取り扱う物件の数がとても多いです。拠点も人も多いですし、これをソフトウェア化すると非常に集約効果が大きいよね、ということでAI化を実施しておられます。
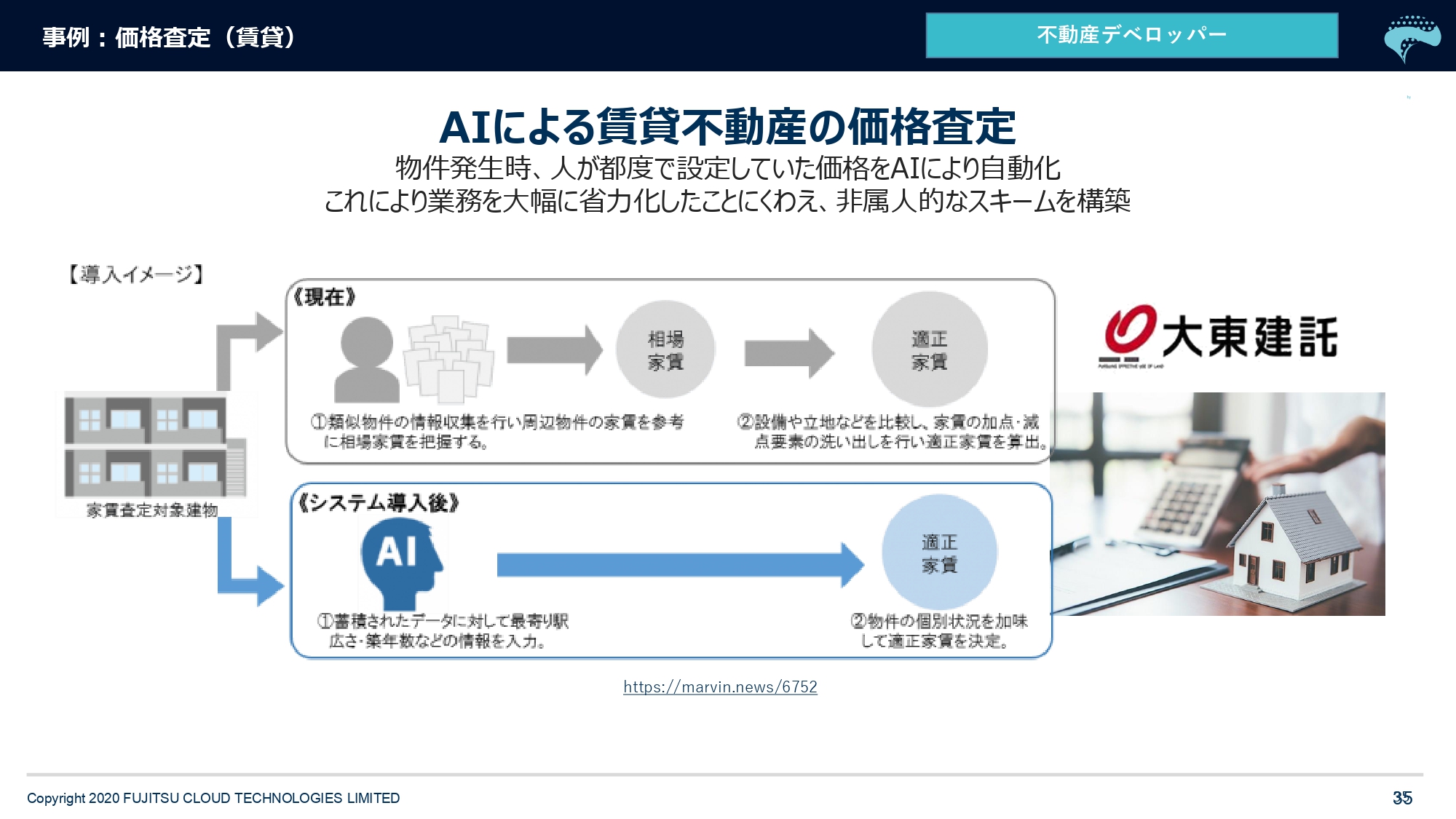
今「不動産テック」と呼ばれるもののうち、多くの取り組みが、この価格査定なんですね。弊社は賃貸以外にも、別のデベロッパーさんの中古マンション販売のAI開発なども担当させていただいております。これも先ほど申し上げた王道のスキームと同じでして、とても多くの人が多くの工数をかけてやっているという、このバリューチェーンをなんとか改善したいよねということで、人工知能を取り入れられている事例になります。
事例:アンケート自由記入欄の言語解析
次にアンケート解析の事例です。商品企画やサポート品質の改善に使われていらっしゃいます。例えば金融機関さんなどでアンケートを取ります。アンケートは通常、定量化できるように設計されていて「ラジオボタンで3つの中から選択」など、後から集計できるようになっています。
一方で、フリー記述欄がありますね。アンケートのフリー記述欄は実はほとんど使われていなくて、見られることもほとんどないと。でも実はそこには、けっこう貴重な気付きが埋まっているらしいです。
それをポジティブ・ネガティブなど、自然言語解析の技術を用い解析し「この人、ネガティブに見えて、実はすごくポジティブなこと言ってますよ」とか「全体で出てくるキーワードはこういうキーワードですね」という解析をすることで、次にアンケートを設計するときにはそこのパラメータを定量化していくというようなことをされています。
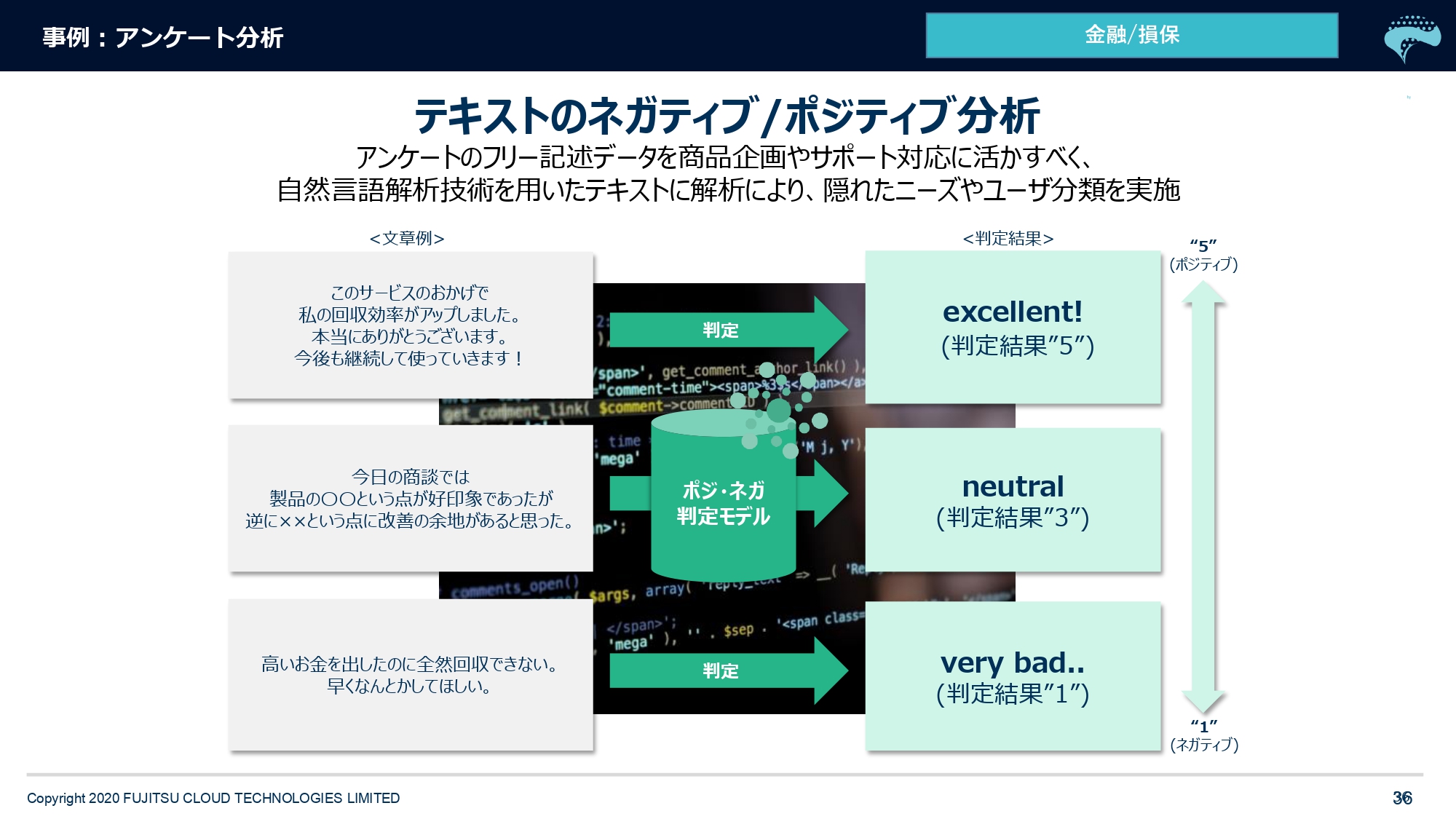
こちらは金融機関さんの事例ですけど、金融機関さんに限ったことでもなくて、みなさんがお客さまから取られたアンケートについて、CRMの一環としてAI(自然言語解析)で分析していくことは、今後増えてくるんじゃないかなと思います。
事例:飲食チェーンの来店数&発注数予測
最後の事例です。これも王道なんですけど、リアル店舗の需要予測。弊社は、ある大手飲食チェーン店さんの来店数を予測するお手伝いをさせていただいています。
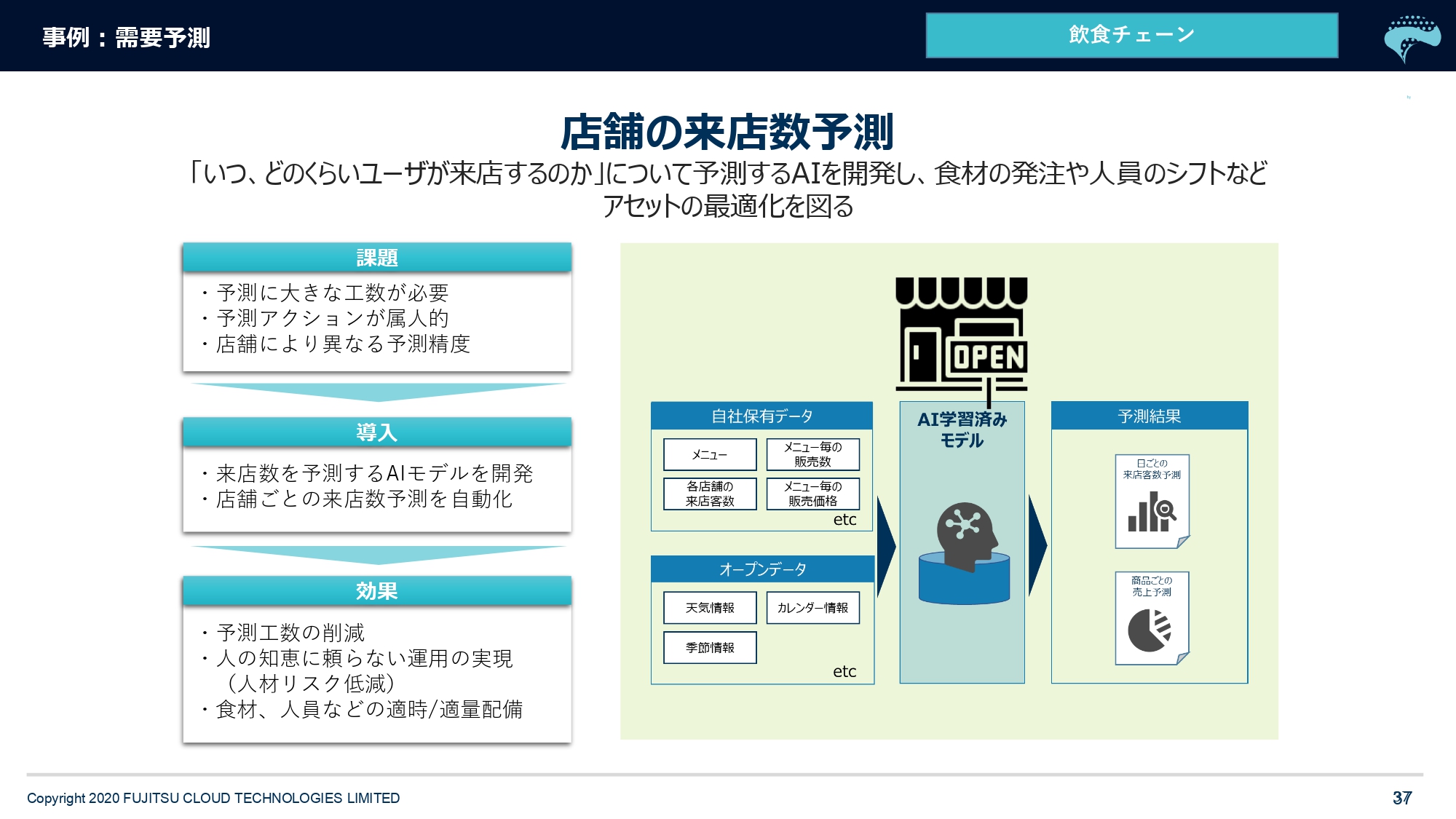
POSデータで販売データや来店数、どのぐらいのメニューが出たかといった過去のデータを用い「1週間後にお客さまがどのぐらい来るか?」などを予測します。
飲食店さんにはやっぱり生ものがありますので、(効果の)1つは、まず食材の発注に非常に効いてきます。もう1つが人の配置ですね。今の日本は、アルバイトさんを非常に見つけづらい国になってきているそうです。
そういった限られた人員資源を的確に配置しないといけない。人の来ない日に大量に配置してももったいないですし、逆も然りということです。来店数やメニュー数がどのくらい出るかは、各社さんが回帰分析のような統計を使って分析されているんですけど、それをさらに高度化しようということで、機械学習を使った取り組みが増えてきています。
これはコンシューマ向け店舗の需要予測ですが、例えば製造業さんの「調達する原料の購入を最適化するために、どのぐらい自社の製品が売れていくかを予測する」というのは、どの会社さんでもやられているかなと思います。そのような販売予測だったり、自社製品の供給予測というのには、人工知能は非常に使われ始めているというか、もうすでにけっこう使われている分野かなと思います。販売管理ソリューションのオプション機能として提供されているケースも多いですし、みなさんも今取り組んでおられるんじゃないかなと思います。
「AIの価値」を決める、3つのポイント
ここまでが事例になります。ではここから重要なところに入っていきますが「成功確率を上げるポイント」について、お話をさせていただきたいと思います。

すごく重要なスライドですので、再掲をさせていただいています。AIの価値は、大別をしますと「非属人化できる」点、人の手間・工数を省ける「省力化」、それから「品質(精度)向上」の3点があると思っています。
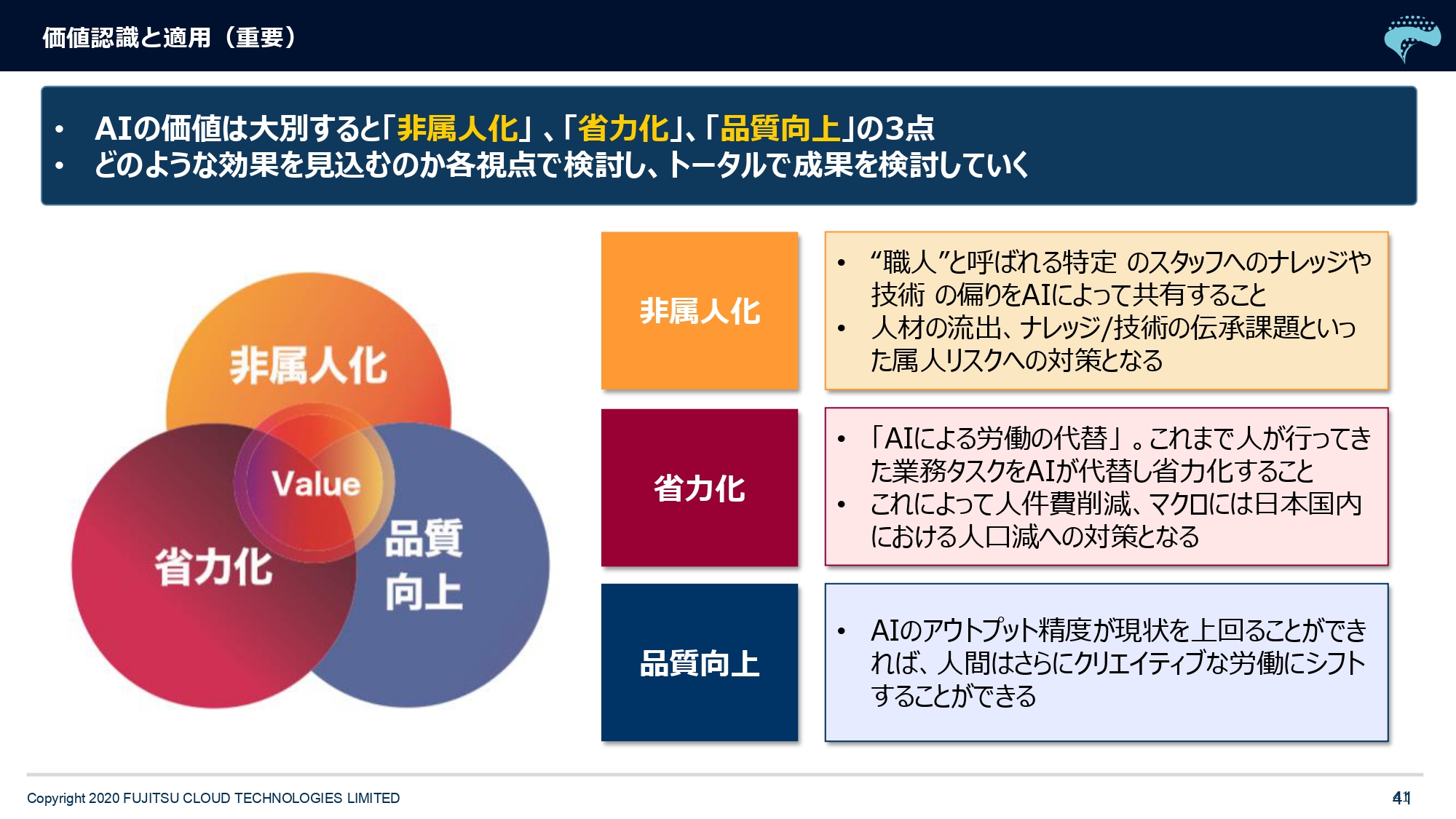
メディア扇動による過度な期待値も相まって「AIはなんでも予測してくれる、魔法の杖だ」という風潮が広まっているわけですけど、それってどこにフォーカスされてるかというと、品質や精度向上にフォーカスされています。「AIは人の予測を超えるんだ」と。例えばガンの予測にしても、専門の医者が診るよりもAIが診たほうが将来予測の精度が高い、みたいなことを言うんですけど。
確かにそういう分野もあります。ありますが、みなさんの仕事になぞらえて考えてみたときに、当然、精度は人より高いほうがいいんですけど、AIにはRPA(注:Robotic Process Automation/ホワイトカラーの定型作業を、AIなどの技術を備えたソフトウェアのロボットが代行・自動化する)のような要素があって。
先ほど事例を見ていただいてご認識のとおり、大量に人手をかけてやっている作業は、ごまんとあります。そういうところをAIで自動化することで、多くの人的労力をソフトウェア化できることが1つ、まずメリットだと思います。つまり省力化です。
もう1つは労力ではなくて「ベテランのスタッフしかわからない不良品の検知」や「特定の人に委ねている食品の発注」などです。「その人がいなくなったらどうするの?」といった業務は、私のチームにも実はあります。これは良くないんですけども、やっぱり業務って属人化するんですね。よく職人さんの技術承継の問題とか言いますけど、あれもまさにそうで、その人がいなかったら会社が立ち行かなくなるというのは、すごいリスクですごいボトルネックになりえます。
そういうところは、最初は精度が落ちてもいいんです。人が見たら90パーセントのところが、AIでやったら80パーセントでもいいので、AIにそれを置き換えておくというリスクヘッジをしておかないと、人口減と高齢化のなかにあって、技術承継ができなくなってきます。特定の従業員のみにたまったナレッジをソフトウェアに置き換えておきましょう、という動きは非常に重要な考え方で、気付いた会社さんはすでに始めています。
人工知能は学習するので、精度に関しては上がっていくことを前提として「今はそのぐらいの精度でいいですよ」ということでご理解をいただき、その会社さんにとってのR&Dとして一緒に取り組んでおられるような事例が非常に多いです。
属人化している業務において、その人がいなくなった時のことをちょっとイメージしていただいて。精度も重要ですけど、省力化と非属人化というパラメータで、そのプロジェクトを考えていくことが、非常に重要だと思います。
ベンダーコントロールの視点で大切なのは?
今、申し上げましたけども、精度だけで課題を整理したり選定したりしていくと、見誤ることがあります。ちゃんとしたフレームワークで課題を整理していく設計を心がけて、プロジェクトを安易に始めない。早く始めるのはすごく重要なんですけど、設計に関しては少し時間をかけたほうがいいかなと思います。

それから、自社だけでは完結しない開発があるので、我々もその1社ですけれども、ベンダーを使うことがあると思います。ベンダーを使う時に、AIは成功しない確率が少なからずありますので、契約のタームですとか、ひと工夫が必要です。
業務アプリケーションなどであれば、ガチガチに要件定義された「こういうコード書いてボタンを押すと、こういう機能が実装される」というものがあるんですけど。AIは精度という要素があるので、プロジェクトとしてはうまくいかないこともあるんです。私どものようなベンダーと契約を結ぶときには、ちょっと面倒くさいんですけど、契約のタームを短めにするようにしてください。例えば総額5千万円のプロジェクトだとして「はい、5,000万円で一括契約」ではなくて、3つか4つに契約を分けてどこかでストップできるようにしておくことが、ベンダーコントロールの視点で非常に重要だと思います。
今申し上げました2点。「開始前にちゃんと整理しましょうね」ということと「始まる前に、ベンダーと契約のタームに関して協議する」というのは、非常に重要だと思います。
外注前に自社で行っておきたい「課題の一覧化・優先順位づけ」
課題整理のところで、補足をさせていただきますと、私どもはこういう「DIVA」というフレームワークを使って、お客様の課題を一覧化するお手伝いをさせていただいています。Data、Information、Value、Achievementの略です。
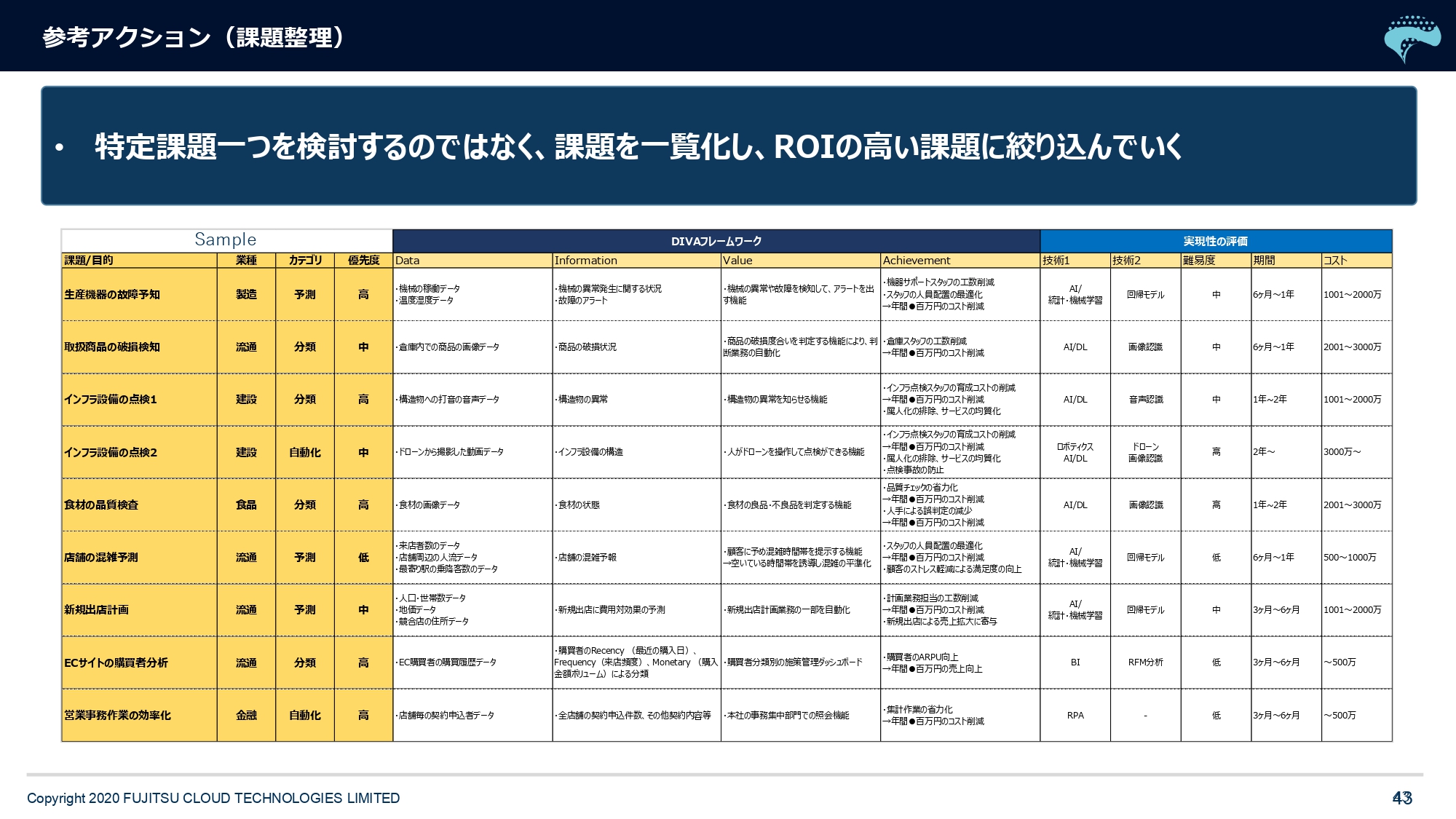
そもそも自分たちの課題は1個じゃないと思うので、いろいろな事業課題をタテに並べて「それって解決されると、誰がどのようにうれしいんだっけ?」というのがValueですね。「解決されると、どのぐらいうれしいんだっけ?」という定量的な効果がAchivementで「解決にはどのような情報が必要か?」というのがInformation。「どこにある、どういうデータを使って解決できるんだっけ?」というのがDataですね。こういう「DIVA」の中身をまずお客様に埋めていただく。
そして、私どもベンダーや情報システム部門とも連携し、それぞれの課題は「それはAIで解決できます」「それはRPAですね」「それはBIで人が見たらいいんじゃないですか」とか、あるいは「それはロボティクスですよ」とか。AIがすべてじゃないので、課題に応じた技術的な提示が必要だと思います。
そこに「それをやるにはだいたいこのぐらいのコストで」「このぐらいの期間で」「難易度ちょっと高いですよ」「低いですよ」みたいなものをくわえて一覧化すると「効果は1億円だけど、かかるコストも1億円だったらちょっと止めようかな」とかですね(笑)。そういう1個1個を見ていって、最終的には優先順位をつけて「上から3番目を最初にやろう」ということをオススメさせていただいています。
私どもは多くの企業をご支援させていただいていますが、私どもにお声掛けをいただく時点でこのような整理ががすでに(課題を整理)なされていた会社さんは、実は1社しかありません。ご自身の中でここまで整理できている会社さんは、あるようで実はないんです。
なので、願わくばこの左の、DIVAじゃなくてもいいんですが、ご自身の中で課題が一覧化されて優先順位づけがされているという状態までを、まずご自身の設計の時点でやっていただくと、たとえベンダーにアウトソースするとしても、話がかなり早く進むんじゃないかなと思います。課題整理の手法として、参考までにご紹介させていただきました。
データは“数があればいい”わけではない
ちょっと趣(おもむき)が違って、続きましては「きれいなデータ」ということで。「90万件から20万件」ということで、これは実際のAIのプロジェクトにおいて私どもがお客様から申告をしていただいたデータ数と、実際に使えたデータ数の差です。この70万件は何かというと「データ分析に使えるデータと所有データの数はイコールではない」ということですね。実際、社内にビッグデータはあるかもしれないんですけれども。

弊社もぜんぜん他社さんのことは言えなくて、Salesforceを入れているんですけど、例えば「このお客さんの売上、1円なわけないじゃん」とかですね。私も一時期、セールスのマネジメントをやっていたんですけど「埋めるべきところを、ぜんぜん埋めてくれてないじゃん」とか「実はA社とB社、同じ会社じゃない?」とかですね。あるいは画像であれば「汚くて、コンピュータで読み取れないんだけど」みたいな。

「データがある」という解釈に関しては、あればいいわけではなくて「ちゃんとコンピュータが認識可能な正しいデータ。欠損も少なくて誤りも少ない正しいデータがある」ということが、データ利活用の前提になります。
実はこれはけっこう時間がかかります。データを入力する側は、どうアウトプットされるかなんて知ったこっちゃないので、適当に入れたりするんです(笑)。「データはBIのダッシュボードにアウトプットされて、最終的に売上などの予測のために使われるから、正しいデータをみなさんに入れていただくことで、会社として正しいデータ利活用ができていくんですよ」という啓発、継続的な投げかけが、僕も口酸っぱくして言っていたんですけど、なかなかできないんですよ(笑)。
なかなかできないんですけど、続けるしかないので。「データがある」という認識をされているみなさんは、ぜひご自身のデータを一度眺めていただいて、中身がどんなものかというのは見ていただきたいなと思います。
使い分けられる「データ」という言葉
あとは先ほどから「データ、データ」と言っていますけれども、みなさんご自身の事業で持たれている自社データが「ファーストパーティデータ」です。次に、例えば製造業さんであれば物流会社さんや販売会社さんなどのパートナー会社さんが持っているデータを「セカンドパーティデータ」と言います。
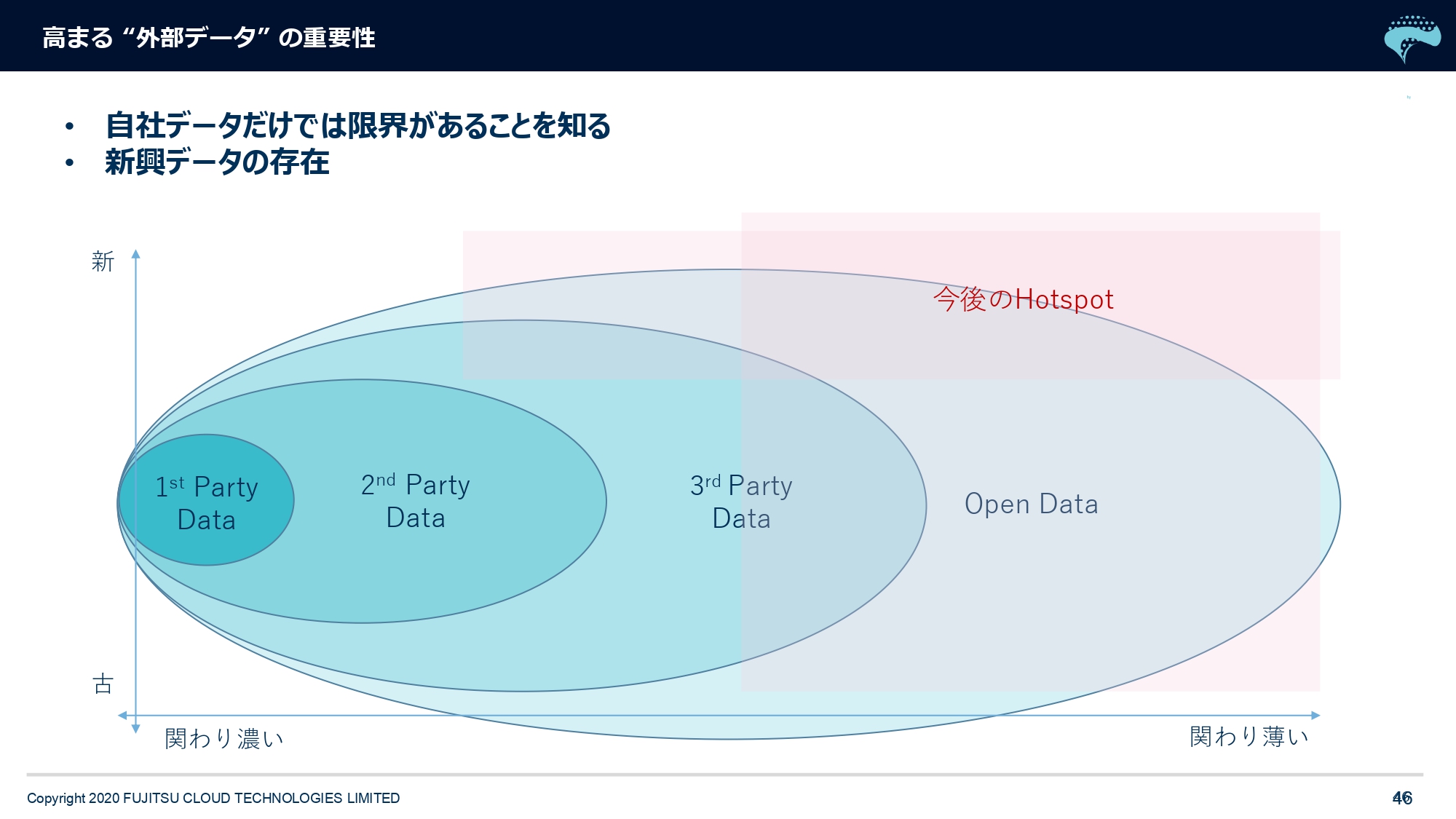
そして、自社でもパートナーでもない、まったく第三者のデータが「サードパーティデータ」と一般的に言われているんですけども。私どもは、サードパーティデータの中でも、有償か無償かで分けています。外部データの中でも2つに分けていて、有償のものを「サードパーティデータ」と呼び、無償のものを「オープンデータ」と呼んでいます。
やはり今後は、先ほど申し上げたようなオープンデータも含めて、一見すると関わりが薄そうな外部データ……例えば先ほどの飲食の需要予測などで言えば、気象庁さんの天候オープンデータを使うと「雨が降ってたらお客さまが来ないじゃないですか」というところに「天気」というパラメータが大きく分析に寄与する場合には、そういうものを持ってこないといけないので。
「外側にある新しいデータ」というものが、今はどんどん出てきています。先ほどのスマホのGPSなどもそうですけど、必ずしも(スライドを指して)この右上だけじゃないんですけど、少なくともベクトルを右上のほうにも向けて、分析のパラメータを考えていく時代だと思います。これらのパラメータのことを「説明変数」と言うんですけど、その説明変数に外部データを意識して分析を設計することは今後、非常に重要な観点だと思います。ぜひ、こういうご認識をいただければいいかなと思います。
万能なデータサイエンティストは存在しない
そして私どもは、お二人の大学の先生にアドバイザリーボードとして入っていただいています。そのうちのお一人が「万能なデータサイエンティストは存在しません」と。「ドメイン知識に基づく統計であって、機械学習です」ということをよくおっしゃいます。
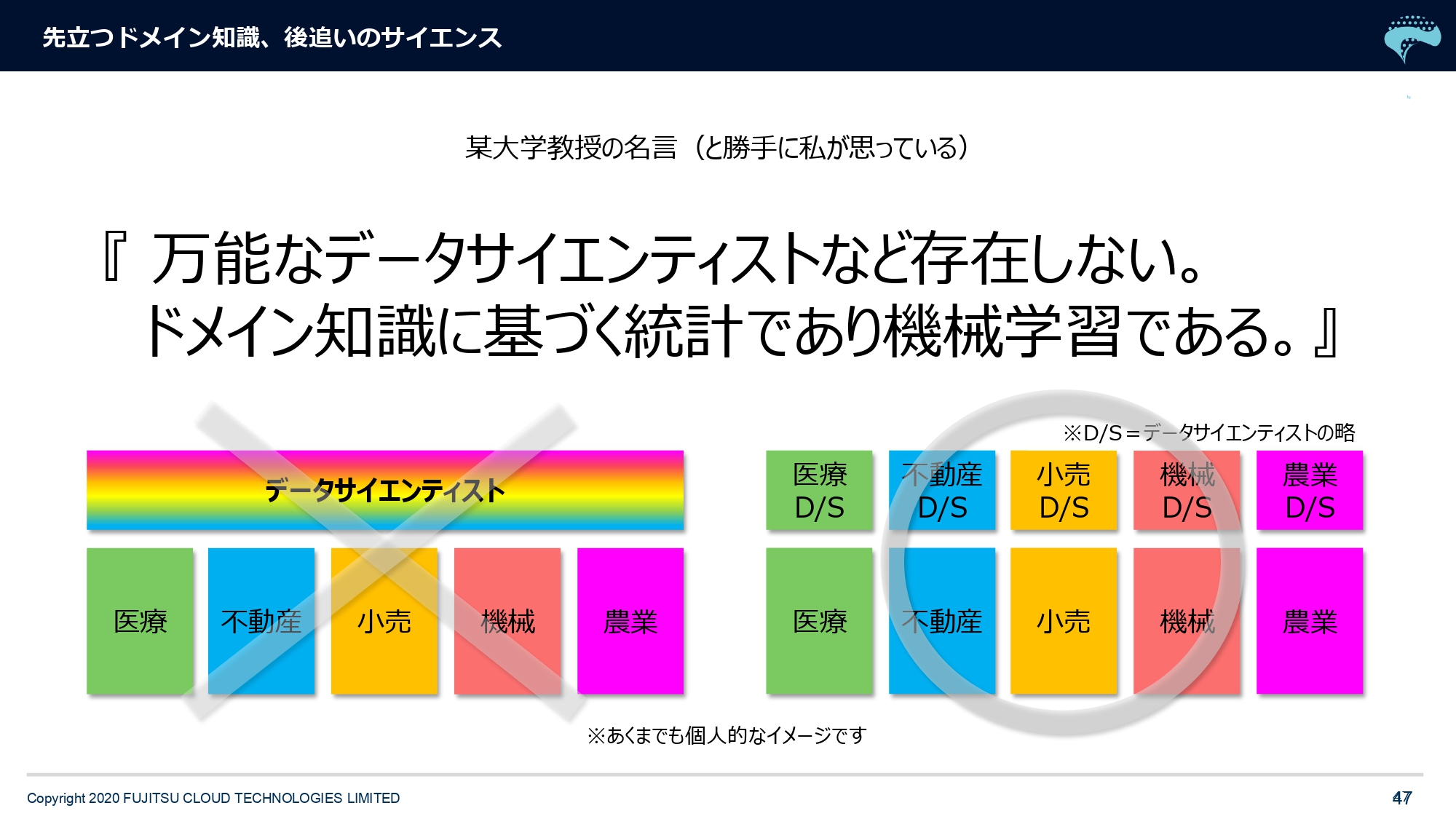
これは何かというと、データサイエンティストは「いま最もセクシーな職種だ」とか言われてるんですけど、聖人君子とかではないので、全業種に詳しいわけでもないんですね。やっぱり掛け算として、数学的な知識はもちろんベースとして持ってないといけないんですけど「製造業と農業と不動産業と小売業の、全バリューチェーンを知り尽くしている天才」というのは、一般論であり得ないわけです。
各業界の専門知識ことを「ドメイン知識」と呼んでいて、それをもとに数学的な知識を掛け算していかないと、やっぱりいいアウトプット・いい精度は出てこないんですよね。
最終的には「医療に特化したデータサイエンティスト」など「それぞれの業種に特化したデータサイエンティスト」という時代になってくるでしょう、と先生はおっしゃっています。私自身もそういうプロジェクトに参画する前は、最初は何を言っているのかわからなかったんですけど、実際にやれば「そういうことだね」とわかる。各業種のドメイン知識は深みがありますし、簡単には習得できない。それをプロジェクトに反映させないと成功確率は上がらないということです。
参考アクションですけども、プロジェクトを推進する時に仮に開発を外に出すとしても、丸投げするとうまくいかないんですよ。ある程度、ベンダー側に業界特有の知識があればいいんですけど。数学的な知識はベンダーに預けて、ドメイン知識はちゃんと自社の担当者にコミットさせるようにしないと、なかなか丸投げでは弊社の事例でもうまくいった例が少ないので。そういうところを意識していただきたいと思います。
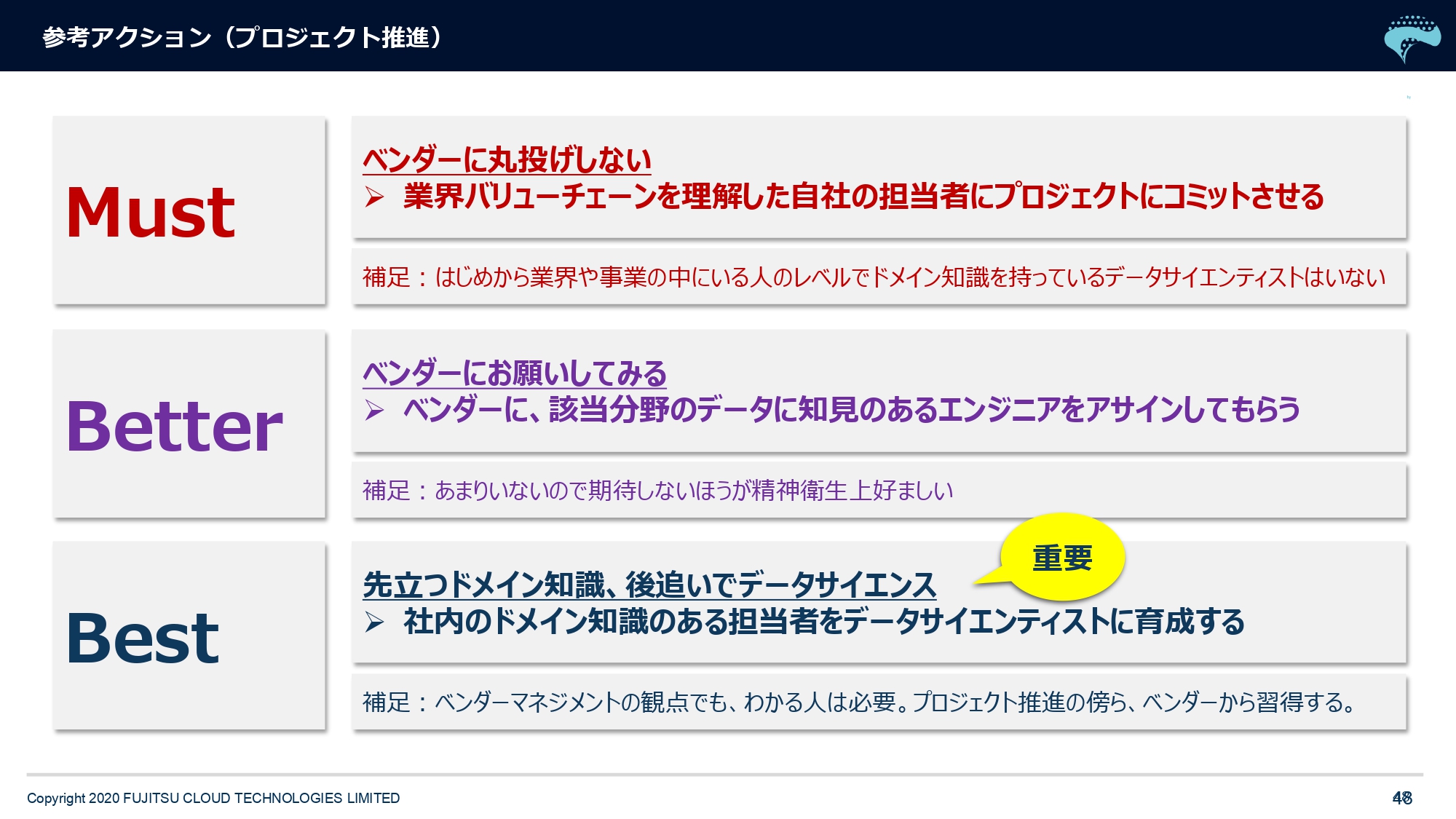
あとはベンダーに投げる時にも、できるだけその業界、みなさんの業種・業態に知見のあるエンジニア・データサイエンティストをアサインしてもらうことは重要かなと思います。
最後に、ドメイン知識が最初で次に数学的な知識という意味で……私どものような受託をするベンダーが申し上げるのも、なんなんですけれども(笑)。やはりみなさんの会社の中に、それなりに知識があって自分で統計なり機械学習の簡易設計ができて、PythonやR(などのプログラム言語)が使えて、という担当者をチームに1人作っていくという動きは、たぶん10年後には当たり前になっていると思います。
やっぱり「AIを作っていこう、使っていこう」「他社を出し抜いてやろう」という時に、ベンダーマネジメントも含めて中に詳しい者が1人もいないのは、厳しいと思います。そこはぜひ実践をしていっていただきたいなと思います。
AIの価値を正しく理解して、プロジェクト推進してほしい
最後にまとめさせていただきます。まず「DXの時代」「デジタル時代」に関しては、もう「データの時代」というのはひとつの重要な考え方だと思います。それを「違う」と言う人は、いないと思います。あと、AIは競争を勝ち抜くかなり強力な武器だと、今日のお話でご認識いただいていれば幸いかなと思います。

活用の裾野は、2~3年前までは大企業ばかりだったんですけど、今は中堅の企業さんや中小企業でも、先ほど申し上げたいろいろなラッピングツールが出てきております。ちょっと知識があったら学習済みモデル、AIのモデルを作れるようなものも出てきているので、ロングテールに広がりつつあるなと思っています。そしてツールの普及と人材の高度化が、そういうものを後押ししています。
ポイントに関して、今日一番申し上げたいのは「AIの価値を正しく理解していただいて、プロジェクト推進していただきたい」ということです。あとは設計に時間をかけましょう。データをきれいに保持する努力も必要ですし、ご自身で持たれているデータを洗い替えをしたり、常にフレッシュな、きれいな状態にしておくことも重要だと思います。
あとはデータがいろいろなところから持ってこられる。「このパラメータが必要だな」と思ったら、わりと簡単に持ってこられる時代なので、そこは諦めずに、ぜひ新興データを引っ張りにいってほしい。衛星データなども含めてありますけども、引っ張りにいってほしいなと思っています。
あとは人材のお話ですけれども、ご自身でぜひ育成をしていただいて、ベンダーパートナーを見つけるにしても、ぜひご自身の業種に知見のあるベンダーパートナーを捕まえてほしいなと思っていますし、仮にそういう人がご自身の中で用意できなかったとしても、ドメイン知識のある担当者さんは、ぜひプロジェクトにジョインしていただけるとこちらとしても非常にやりやすいです。結果的にWin-Win、精度の高いAIが作りやすいというかたちになりますので。ぜひ意識していただけるとありがたいなと思います。
私からのお話、以上になります。ご清聴ありがとうございました。