




 PR
PR2025.11.27
数理最適化のエキスパートが断言「AIブームで見落とされがちな重要技術」 1,300社が導入した「演繹的AI」が意思決定を変える
基調講演(全1記事)
提供:アマゾン ウェブ サービス ジャパン株式会社
コピーリンクをコピー
ブックマーク記事をブックマーク
平野未来氏(以下、平野):みなさん、おはようございます。シナモンの平野です。本日はどうぞよろしくお願いいたします。

シナモンがミッションとして掲げているのは「Extend human potential by eliminating repetitive tasks」です。ホワイトカラーには本当にたくさんの面倒な仕事があると思うんですが、そういったお仕事はどんどん人工知能にやってもらって、人間は人間らしい仕事に集中できる世界の実現を目指しています。

私たちの組織のユニークなところは、AIリサーチャーがたくさんいることなんです。現在、グローバルに200人を超えるメンバーがいるんですが、そのうち100人はAIリサーチャーとなっております。

ちなみに、日本全国全世代で見ても、AIリサーチャーというと400人程度しかいませんので、この100人という数字はかなりインパクトのある数字ではないのかなと思っています。
なぜこれができるのか。私たちは事業開発を日本・アメリカで行っているんですが、AIラボは理数系の強いベトナム・台湾に持っているからなんですね。そちらで数学の天才たちを見つけてきて、彼らにディープラーニングのトレーニングをする。そうすることによって、非常にハイレベルなAIリサーチャーの獲得に成功しています。

平野:本日ご紹介させていただくのは「Cinnamon AI Platform」です。

企業のデータのうち8割は、メールや画像、音声のような非構造データと言われています。非構造データがたくさんあったとしても、その中から意味のある情報を抽出するには、これまでは人間が行う必要がありました。シナモンのAI Platformでは、非構造データから意味のある構造データを抽出することができます。

私たちには、3つのresearch pillarがあるんですが、そのうち2つは認識レイヤーとなっています。

まずドキュメントを認識できる文字認識、そして音声データを認識する音声認識、この2つの技術によって、まずはお客様の非構造データをデジタル化します。そして、そのデータを自然言語理解する。それが3つ目のresearch pillarです。
これまで私たちは、自然言語理解を実現するさまざまなアルゴリズムを実現してまいりました。例えば文脈理解や情報抽出、オントロジーなどです。こういったアルゴリズムを組み合わせることによって、ビジネス上でもインパクトのあるAIをご提供させていただいております。

例えば保険業界。保険業界というと、毎日、本当にたくさんの紙を受け取ります。そういった紙をデータ化するために入力する方々がたくさんいらっしゃるんです。まず私たちは、文字認識によってその紙をデジタルデータ化いたします。それに対して、文章理解をし、そして尤度(ゆうど)解析をする。こういったアルゴリズムを組み合わせることによって、年間50億円もの削減見込みとなっております。

そして、コールセンターで、オペレーターの方とお客様の間のコミュニケーションをまずは音声認識でデジタル化いたします。そのデータに対して文脈理解をし、そして適切なFAQをレコメンドする。そして最後に要約する。こうすることによって、新人さんのようなオペレーターの方でもハイパフォーマーになることができます。

そして、契約書など。文章理解や情報抽出、Question Answering、クラスタリング、こういったアルゴリズムを組み合わせることによって、弁護士の方でも1週間かかっていたタスクが、たった30分に短縮しております。

現在、私たちは50社を超えるお客様がいらっしゃるんですが、そのほとんどが大企業となっております。

平野:ここで私たちのビジネス環境をご説明させていただきますと、まず、ベトナム・台湾にAIラボがございまして、そこでモデルの開発を行っています。
そこで開発したモデルを日本・アメリカにいるAIデリバリーがお客様にご提供しているんですが、その結果、「ここがよかった」「ここがよくなかった」みたいなフィードバックをAIラボに返し、さらにアルゴリズムの精度を高めるために、そのモデルの改善をします。

そういったサイクルが行われているんですが、より良いアルゴリズムを作るためには、そのサイクルを高速化する必要がございます。具体的には3つの課題がありました。

1つは、100人ものAIリサーチャーがいるんですが、それぞれで開発環境が違っていたので、なかなか効率的な開発が行えていない。
また2つ目は、GPUインスタンスを人力で管理しているので、これはコスト増にもつながります。
そして3点目、グローバルコラボレーションの難しさ。お客様の非常に重要な学習データを扱う必要があるんですが、そういったデータを国外に持ち出すことができない。そのようなさまざまな問題がありました。
それを解決したのが「Amazon SageMaker」でした。
平野:まず、AIリサーチャーに統一化された環境を用意し、好みのディープラーニングフレームワークを選択できるような環境を実現いたしました。これにより社内オペレーションが効率化いたしました。
そして、GPUインスタンス。マネージドサービスで学習時のみGPUインスタンスが起動いたします。これはコスト削減にもつながります。
そして3点目、日本のデリバリ環境との統一により、モデル開発のサイクルが高速化いたしました。サイクルが高速化されたことで、精度をより高められる環境が実現されたこととなります。

これまでシナモンは本当にさまざまなチャレンジを行ってきたんですが、現在、新たなチャレンジを行っています。機械学習を、より身近に、より効率的に。
まず、お客様のサーバにAWSのVPC(Virtual Private Cloud)をつないだセキュアな環境をご用意いただきます。そして、シナモンのサーバにもAWSのVPCをつないだセキュアな環境がありますので、その2つをまたいでAmazon SageMakerを活用する仕組みを作ります。
この仕組みが画期的なのは、1つは、データをお客様の環境に留めることで、セキュアな推論環境を実現できることです。これまで問題だった学習データの受け渡しについても、そもそもデータを渡す必要がなくなります。
2点目は、リサーチャーが開発したモデルを即座にご提供できることです。これまで、セキュアな環境で機械学習を実現するためには、お客様のもとにモデルを持っていく必要がありました。そんな必要もなくなります。

どんな大企業のお客様でもAWSをお使いであれば、シナモンが開発したAIをセキュアに、しかも最先端のモデルをご利用いただくことができます。最先端のエンタープライズAIフレームワークをご提供することで、日本のエンタープライズにイノベーションを起こします。

最後になりますが、私たちは、人工知能によってホワイトカラーをクリエイティブにする、そういった世界を実現してまいります。本日はありがとうございました。
(会場拍手)

名村卓氏(以下、名村):こんにちは。私の方から、メリカリのAWSの事例について紹介させていただきます。まず、メルカリの紹介をさせてください。

メルカリは、個人の中古品の売買を可能にする、CtoCのマーケットプレイスです。メルカリがエスクロー決済を行って、多様な配送オプションを提供することで、個人間の取引を円滑に行えるプラットフォームになっております。

四半期ごとの利用実績なんですが、おかげさまで多くのお客様に利用されており、四半期ごとの実績は去年で3,000億円を超えてきております。

メルカリの特徴は、1つは滞在時間です。他のECサービスに比べて、非常に長い滞在時間を誇っております。ソーシャルネットワークサービスに匹敵する滞在時間です。

メルカリの他の特徴としては、個人間の取引ですので、安心した取引を実現するために、例えば捜査機関や公的機関との連携をしています。最近ですと、他にもAIによって大量のデータから違反検知、利用規約に反する出品を自動で検知して、安心・安全なサービスの提供に努めております。

今後の事業展開なんですが、メルカリは最近「メルペイ」をリリースしまして、メルカリでの売上金を実際の店舗でも使えるようになりました。こうしたエコシステムの拡大をもとに、メルカリでは総合的な金融サービスの提供を視野に入れて、拡大しています。

また、海外のアメリカでもメルカリは展開をしており、アメリカの事業も引き続き成長を続けております。
ここから、メルカリのAWSの実際の活用事例の紹介をさせていただきます。まず、AI・マシンラーニングの分野です。メルカリでは、最近AIの分野に非常に注力してまして、この分野においてAWSの技術を活用しております。

まず最近リリースした「Image Search」という、画像検索という機能なんですが、こちらは写真を撮ったものに近いものを、メルカリの商品の中から検索できる機能になります。

名村:メルカリはペタバイト規模のデータを持っており、こちら、画像のトレーニングにAWSの環境を活用しています。簡単なアーキテクチャのオーバービューなんですが、トレーニングにはEKSのクラスターを使っております。
こちらでコンテナベースのトレーニングクラスターが動いており、GPUを使って実際にトレーニングを行っております。メルカリはS3にすべての画像を保存しておりますので、こちらの画像と、EKSのクラスターをシームレスに繋ぐことで、トレーニングを実現しています。

AWSと相性がいいポイントなんですが、まずAmazon S3の存在は非常に大きいです。高い可用性と安定したストレージが「日々トレーニングをし続ける」といった環境に非常に適切であること。
また、充実したイベントフックを持っていますので、複雑なロジックを記述することなく、トレーニング環境にデータを渡すことができる。それから、S3の充実したツール群によって、開発が非常に簡単に行えます。
また、EKSのほうですが、Kubernetesを管理するコストがまったくないことは非常に大きい特徴で、KubernetesのCRD(Custom Resource Definition)を使って、全体のトレーニングを構築してるんですが、こちらの実現が可能である。それによって、フルコンテナのワークロードでトレーニングを実現しているところがポイントになります。

他にも、AI出品という機能もありまして、これから出品するものを撮影したタイミングで、商品のタイトルやカテゴリーブランドを推測して、自動で入力してくれます。こちらのトレーニングにもAWSの環境を活用しています。
それから、安心・安全なメルカリの提供に向けて、AWSの活用をした事例もあります。例えば、メルペイなどの金融サービスは、AML/CFTというアンチマネーロンダリングやテロへの資金供給を防止する機能が必要になるんですが、こちらの機能にAWSの技術を多く活用しています。

splunkというプラットフォームを利用しているんですが、こちらをAWS上で稼働させて、KinesisやFirehoseといったログ収集基盤をはじめ、LamdaやFargateなどの技術も活用して、この技術基盤を実現しています。

このAWSと相性が非常にいいポイントなんですが、まずKinesisの存在が大きいです。splunkがKinesisに標準対応していますので、こういった取引の情報やイベントを収集するパイプラインとして、Kinesisが非常に強力に機能しているところです。
あとはECSをはじめ、FargateやLamdaのサーバーレス環境も活用してまして、こちらによって管理コストを下げながら、データのリアルタイム処理や、外部データの投入、もしくはバッチ処理を実現しています。

メルカリがAWSを使う主な理由を考えたんですが、とくに3つあります。まずは、日々信頼が積み上がっている……いろいろな実績が日々起きていることで、AWSそのものに実績がどんどん積み上がって、それによって信頼のあるサービスの実現ができるところ。
あとは、毎年・毎月、無数の新機能が常にリリースされるので、新しい開発、もしくは最新のトレンドに乗って、常に最新のソリューションを利用することができるところ。
それから、「Customer Obsession」というAmazonのプリンシパルにもありますが、こちらが非常に徹底されているので、メルカリのアカウンティングチームの方々が、まるで社員のようにメルカリの課題を一緒に考えて、何とか実現しようというソリューションを一緒に考えてくれるところ。こういったところがAWSの強みだと思っていて、活用をしています。
これからもメルカリはAWSを活用して、安心・安全なサービスを、より多くのお客様に提供されるように、常に努力してまいります。以上です。
島田幸輝氏(以下、島田):みなさま、はじめまして。シンセティックゲシュタルトの島田です。本日は、このような場でお話しさせていただき、大変光栄に思います。

さっそくなんですが、私は信じていることが1つあります。それは、人間の社会活動において最も偉大なことは、科学的な発明をするということです。

例えば18世紀、ジョゼフ・プリーストリーは、酵素タンパク質を見つけたことにより、さまざまな化学反応を、人間の手でコントロールすることを可能にしました。
そして19世紀、北里柴三郎は、血清療法を発明し、多くの人々の命を救いました。このように、科学的な発明は社会にとって大変重要なことです。しかしながら、こうした偉大な発明は、彼ら天才たちによる不断の努力と、その研究の賜物であり、いつもいつもこうした天才たちの発明を、我々が享受できるとは限りません。

そこで我々は、人間の代わりに、こうした科学的な研究を行い、そしてすばらしい発明を社会に届ける。そうした人工知能を開発しています。
つまり、人工知能による科学研究。これを実現することで、天才たちに依存せずに、すばらしい発明を、社会に安定的に届けようとしているのです。我々シンセティックゲシュタルトは、そうしたミッションを胸に、今このライフサイエンス領域に特化をして、人工知能を開発しているスタートアップです。

去年できた会社ではございますが、日本政府や、イギリスのアカデミアをはじめ、多くのパートナーやサポーターの方にお世話になっております。この場をお借りして、お礼を申し上げたいと思います。
さて、我々は、ライフサイエンス領域の中でも、とくにこの創薬の分野に力を入れています。みなさん、ご存じでしょうか?

1つの医薬品を開発するのに、平均して2,000億円以上の費用と、10年以上の歳月がかかっていることを。そして、さらにこれは、年々増加傾向にありまして、薬の価格が高くなりすぎて、各国の社会保障費を圧迫するということが、近年社会問題化しています。

島田:そこで我々は、機械学習モデルによって創薬を支援し、さらにロボットによって、実験を自動化し、人工知能に新しい薬を発明させることによって、この上がり続ける薬の価格の問題を、なんとかしたいと考えております。具体的には、Amazon SageMakerを使って、分子の情報から、その分子が持ちうる機能を予測する、機械学習モデルの開発に成功しました。

この開発プロセスでは、機械学習が出力をした仮説を、実際に実験を通じて確かめています。実験の結果によっては、我々はこのモデルを改良しています。こうした仮説検証を、何度も何度も繰り返すことによって、非常に難しかった分子機能の予測を実現しました。そして、SageMakerによって、簡単に分散処理ができましたので、大規模な実験データを素早く訓練して、推論することなどが可能になりました。

そのおかげで、我々はSageMakerを使う前に比べて、この仮説検証プロセスを回すスピードを10倍に改善することができました。こうした機械学習モデルができたおかげで、分子機能予測は革命的に進化しました。従来であれば、人間の研究者が、1個1個丁寧に実験していましたが、それには1回の実験につき数十万円のコストと、数ヶ月の期間がかかっていました。
これをSageMakerのモデルを使って、期間にして約1秒もかからずに、分子の機能を予測し、それにかかるコストも1円もかからないようになりました。非常に圧倒的な成果が出たと言えます。
こうした革新的な成果があればこそ、数億のタンパク質の中から、価値があるものを総当たりで見つけるという、今までとてもできなかったアプローチが可能になったのです。
その結果、我々はイミンリタクターゼという、製薬業界ではとても重宝されている、酵素タンパク質の新種を見つけることができました。しかも、この新種は通常見つけるのが難しいと言われていたものであり、我々人工知能アプローチならではの結果が得られたと思います。

さらに我々は、強化学習を使って医薬品のもとになる分子を設計するという、困難な問題にもチャレンジしています。
この医薬品の開発の問題では、病気を引き起こしうるタンパク質を阻害するための分子を設計する必要があるんですけど、これを強化学習モデルにデザインさせようというのが、このプロジェクトです。

柔軟なSageMaker SDKのおかげで、SageMakerで学習した機械学習モデルを、SageMaker RLのほうで簡単に使うことができました。例えば、今こちらで表示されているのは、実際にAmazon SageMaker RLで設計された分子です。
これは、与えられた病気のもとになるタンパク質を抑制しながらも、人間にとっては副作用をもたらさないように、徐々に分子が設計されていくことが、ここで確認できます。
結果として、SageMakerをはじめとするAWSのサービス群のおかげで、生物学者や数学者といった、本来機械学習とはちょっと程遠いエンジニアの方たちが、機械学習エンジニアとして、人工知能モデルの開発に、直接携わることができました。
こうした人工知能の登場のおかげで、科学者たちは、従来であれば、自分で実験をして確かめていかなければならなかったところを、科学者は「どうやって人工知能に自分が解きたい問題を解かせられるだろうか」と、マインドをチェンジするようになったのです。まさに今、人工知能によって、このライフサイエンス領域でイノベーションが起きつつあると私は感じています。
人工知能による科学研究を実現することで、すばらしい発明を人々に届ける。そんな未来を、我々は実現したいと考えています。午後の一般セッションでは、我々のより具体的な試みを紹介しておりますので、ご興味がある方は、ぜひそちらもご覧いただければと思います。ご清聴いただき、ありがとうございました。
続きを読むには会員登録
(無料)が必要です。
会員登録していただくと、すべての記事が制限なく閲覧でき、
スピーカーフォローや記事のブックマークなど、便利な機能がご利用いただけます。
すでに会員の方はこちらからログイン
名刺アプリ「Eight」をご利用中の方は
こちらを読み込むだけで、すぐに記事が読めます!
スマホで読み込んで
ログインまたは登録作業をスキップ
アマゾン ウェブ サービス ジャパン株式会社
関連タグ:
この記事をブックマークすると、同じログの新着記事をマイページでお知らせします
PR2025.11.27
数理最適化のエキスパートが断言「AIブームで見落とされがちな重要技術」 1,300社が導入した「演繹的AI」が意思決定を変える
 PR
PR2025.11.28
「あの人がいなくなったら仕事が回らない」を解決 属人的な業務から脱却する「最適化」の実践方法
 PR
PR2025.11.28
「計画と運用」をごちゃ混ぜにすると崩壊する ビジネスに使える最適化システムの“境界線”の引き方
 PR
PR2025.11.27
9割がリピーターでも“飽きられない”仕掛け 馬渕磨理子氏×オリエンタルランドが語る、体験価値と「成長の3本柱」
 PR
PR2025.11.28
“テーマパークの外”への挑戦で売上1兆円を目指す 馬渕磨理子氏が迫る、オリエンタルランドの新領域戦略
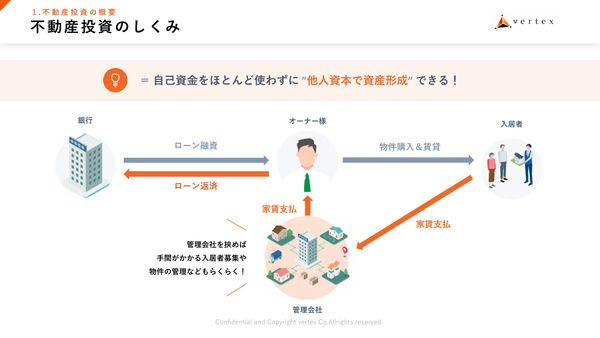 PR
PR2025.11.28
物価上昇時代の“もう1つの収入源” 自己資本約10万円から始められる、不動産投資の仕組みとリスク解説
 PR
PR2025.11.27
AIで激変する顧客体験──「金融機関」と「消費者」の関係を再設計 Brazeが描く“真の顧客エンゲージメント”とは
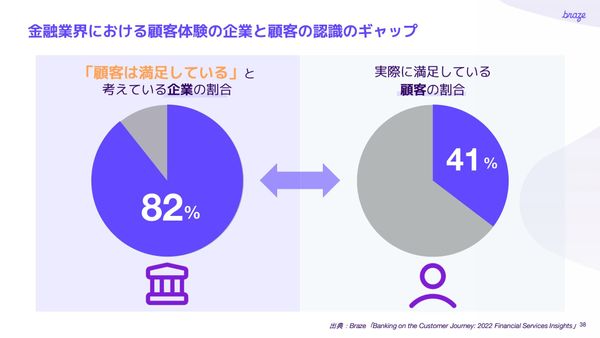 PR
PR2025.11.28
金融機関の休眠顧客をアクティブユーザーへと転換 Brazeが提供する、収益改善を実現する「パーソナライゼーション」事例
 PR
PR2025.11.28
管理職に求めすぎる組織の限界 役割分割で生まれる新しいチーム運営
 PR
PR2025.11.27
「考えろ」と言うだけの上司が組織を壊す 自律型人材が育たない本当の理由
PR2025.11.27
数理最適化のエキスパートが断言「AIブームで見落とされがちな重要技術」 1,300社が導入した「演繹的AI」が意思決定を変える
PR2025.11.28
「あの人がいなくなったら仕事が回らない」を解決 属人的な業務から脱却する「最適化」の実践方法
PR2025.11.28
「計画と運用」をごちゃ混ぜにすると崩壊する ビジネスに使える最適化システムの“境界線”の引き方
PR2025.11.27
9割がリピーターでも“飽きられない”仕掛け 馬渕磨理子氏×オリエンタルランドが語る、体験価値と「成長の3本柱」
PR2025.11.28
“テーマパークの外”への挑戦で売上1兆円を目指す 馬渕磨理子氏が迫る、オリエンタルランドの新領域戦略
PR2025.11.28
物価上昇時代の“もう1つの収入源” 自己資本約10万円から始められる、不動産投資の仕組みとリスク解説
PR2025.11.27
AIで激変する顧客体験──「金融機関」と「消費者」の関係を再設計 Brazeが描く“真の顧客エンゲージメント”とは
PR2025.11.28
金融機関の休眠顧客をアクティブユーザーへと転換 Brazeが提供する、収益改善を実現する「パーソナライゼーション」事例
PR2025.11.28
管理職に求めすぎる組織の限界 役割分割で生まれる新しいチーム運営
PR2025.11.27
「考えろ」と言うだけの上司が組織を壊す 自律型人材が育たない本当の理由

