大津金光氏の研究分野
大津金光氏:ご紹介ありがとうございます。宇都宮大学の大津と申します。今日は春の情報処理祭ということで、ARC研究会から「(情報処理学会全国大会に参加するために)京都に行くついでにちょっと喋ってこい」と言われて登場しました。

私の研究分野ですけれども、コンピュータアーキテクチャということで、特にマルチコアプロセッサとその周辺。周辺技術について研究しています。一言で言うと縦軸が性能のグラフを描く世界の人をやっています。
「ある方式でこのプログラムを実行すると、このぐらい性能が上がりました」みたいなそういう縦軸パフォーマンス(=性能)の世界です。そういうところで生きています。
もうちょっと言うと、キーワード的には投機的マルチスレッド処理というやつでして、世の中プログラムにはいろいろな種類のプログラムがあるんですが、並列処理という分野で、数値計算系とか、そこら辺りでよく対象になっとるような何とか方程式を解くとかそういった分野に関しては、結構並列処理ですごく性能が上がるんですけれども。それとは異なる非数値処理分野のプログラムというのは、割と並列処理に向かないようなものが結構あります。
そういうところを何とかして速くしよう、それのために並列プロセッサを活用してキャリアの高速化をしましょうといったところをやっていたりします。
あと最近の話ですけれども、この投機的マルチスレッド処理と関連する分野として、HTM。あとのほうで説明しますけれども、hardware transactional memoryというものが、最近のインテルさんのCPUには載っかっていたりするんです。
出してみたはいいけれども、何か少々バグってたという話で、実は今機能がディセーブル(無効化)されてしまって、ちょっと悲しいという状況にあります。それ自体はどうしようもない話なんですけれども、そういった形のものも含めて投機的マルチスレッド処理というのを、主な研究分野としてやっています。
あとはそれら(の先進的な並列処理ハードウェア)をサポートするような形で、プログラムの自動並列化とか、あるいは最適化ですね。皆さんが書いているプログラムっていうのは、そのままで並列実行されなくて、例えば今並列プロセッサがあったとしても、その中の1個のCPUしか使わないわけです。
そんなプログラムをちゃんとマルチプロセッサ上で高速で動かそうとすると、何らかの形でプログラムの並列化というものが必要になってくるわけですけれども、そういったものを人間の手ではなくて、自動的にコンピュータにやらせちゃおうということが自動並列化ですね。
普通の自動並列化っていうのは、そのプログラムのソースコードをベースにやるんですけれども。そうじゃなくてプログラムのバイナリーコード、Windowsで言うところの何とか.EXEというファイル、そういった機械語のプログラムレベルでの並列化をしようとかいった研究をやったりしています。
それと近いような分野として、エミュレータとかバイナリ変換とか、あと仮想マシンという言葉もありますけれども、そういった分野にも非常に興味を持っています。
情報処理分野におけるマルチコアプロセッサの位置づけ

お題としてリクルートさんからいただいた流れとしては、こういったところがあるんですけれども、今日の話は大まかに言えばマルチプロセッサです。

もっと言うとマルチコアプロセッサに関して、どういう流れで今に至っているかみたいなところを辿りながら、それぞれどういったものかっていうのを解説していくような形で、話を進めていきたいと思います。
その前にこの分野の位置付けなんですが、言うまでもないことですけれども、コンピュータシステムっていうのはICTの基盤ですよね。つまりこの情報処理学会に関して言うと、全ての分野と関わりを持つことができるという、非常に多くの人とコラボレーションができるような分野かなと思っています。
その応用分野は、どこに使う、何のために使うコンピュータかによって求められるものが違うというところに特徴がありまして、例えばある分野だったら、スループット、つまり単位時間あたりにどれだけの仕事をこなせるか、といったところが重視されるようなこともあれば、応答時間、つまり何か指令を出してレスポンスが返ってくるまでの、その時間ができるだけ短くある必要があるなど、そういったところが重要視されるような分野もある。
あと組み込み分野みたいなところで、消費電力が非常に小さくないと困るというようなところもあれば、絶対に壊れてもらっちゃ困るとかそういったところもある。また価格が高いとお客さんが誰も買ってくれないみたいな感じで、その分野ごとによって何が重要視されるか? そういったところが変わってくるというのがあるわけです。
だからコンピュータのアーキテクチャとしては、何に使えるか? どこで使われるか? によって、それに向けて最適なソリューションっていうのは変わってくるよ、というのを肝に銘じていろいろ開発していく必要があるということです。
あと「各応用に応じて最適な処理システムの構成が何であるかっていうのを明らかにしていく研究分野」と書いていますけれども、当然解は1つではないという話なんですが、それは上のほうの話とも絡みます。
その下にちょっと書いていますけれども、今日の最初の発表で中島先生も言っていたことなんですが、1個の半導体チップの上に集積回路トランジスタっていうのは、どんどん増えていったわけです。そういった形でその時代と共に実装技術、コンピュータを実装するための技術っていうのが変わってきている。
そういった作るための技術がどんどん変わっていく。具体的に言うと、1個のチップ上に入れるトランジスタの数が増えていく状況を念頭に置きながら、進めて行かなくちゃいけないというところが、ちょっと難しいところかなとは思います。そういう意味で、解が1つではないということです。
例えば、ちょっと前に「このシステムにはこの構成が1番いい」といったものがあったとしても、それは次の時代において最適ではなくなっている可能性が高いということを意味するわけです。
その逆もまた真で、昔は最適解じゃなかったものが今は最適解になっているかもしれないということがあるわけなので、今出ているアーキテクチャの研究を、後生大事に守るんじゃなくて、少し視野を広げてちょっと昔のやつも調べてみて「今の技術だったら上手く活かせるものがあるんじゃないか」という形で考えることも必要ということです。
コンピュータシステムの変遷

過去の研究の流れというか、どっちかというとコンピュータシステム自体の歴史みたいな話です。この辺は今日最初にお話された中島先生と被り気味なんですけれども。
まずコンピュータシステムの歴史っていうのはどういうふうに言えるかというと、高性能化と小型化の歴史です。1番最初に真空管で作られていたコンピュータっていうのが、トランジスタが発明されてトランジスタで作られるようになり、さらにICで1個のシリコン半導体が作れるようになって、その上に非常に単純な回路が組み込めるようになった。
そのICの時代を経て、それがさっき言ったように年々1枚のチップ上に集積できるトランジスタの数がどんどん増えていくと、前はちょっとした簡単な回路しか入らなかったものが、どんどん高いシステムレベルのものを入れることができるようになってきました。
結果としてコンピュータは、同じサイズのコンピュータだったらより高性能に。逆に同じ性能だったら、よりコンパクトに小さく作ることができるようになったという時代に発展してきたわけです。それが結局のところコンピュータシステムの歴史そのものであるというのが、ここまでの話ということです。
「ムーアの法則」が終焉を迎える!?
これも今日1人目の中島先生の話と被りますけれども、ムーアの法則と呼ばれる法則がありまして、だいたい1.5年で倍の回路集積度になっていく。つまり1.5年経つと、1枚の半導体チップ上に入れることができるトランジスタの数っていうのが2倍になるということです。
これがずっと続いてきたというのが、この業界のすごいところというか驚くべきところということです。このムーアの法則によって、1個のチップ上にたくさんのトランジスタが入るという状況だったわけなんですけれども、それがその高性能化の源泉にあったわけです。
同じ面積の中にたくさん回路部品が入れられるということは、逆に言うと1個1個の部品が小さくなる。あるいは配線が細くなっていくということを意味するわけなんですが、それによって高クロック化と高集積化というのが達成されてきたわけです。それがコンピュータシステムの高性能化の源泉そのものであったというわけです。
ただこのムーアの法則、これまでは順調でもないですが、結構頑張って続いてきたわけなんですけれど、そろそろ打ち止めかな? というような状況になってきたというのもまた、1つの問題としてあるということです。
これはどっちかというと、物理的に半導体の膜が「原子何個分」になっちゃうとか、そういう話はありますけれども、最終的には世の中の基本であるところの金銭的な話が絡みますので、実現にかかるコスト面から非常に困難になってきたという状況もあって、そろそろこのムーアの法則っていうのが終わりそうじゃないかと、みんな言っています。
私もそう思っていますけれども、これが何を意味するかっていうのが非常に重要でして、さっきも言いましたけれども、ムーアの法則によって支えられたようなところで、高性能化と小型化っていうのを続けてきたわけです。
でもそれが成立しなくなってきたということは、「コンピュータシステムのアーキテクチャに関してもちょっと考え方を変えていかなきゃいけないんじゃないかな?」という、1つの時代の転換点になっているので、これからアーキテクチャをやりたいという人にとっては、なかなかおもしろいタイミングじゃないかなと思います。
制約条件と戦うコンピュータアーキテクチャ

ここから先が話の本編なんですけれども、考えてみましょう。ここに1個箱があります。あまり箱に見えませんけれども、箱です。箱があるとします。この箱の中には、たくさん電子部品を入れることができます。また当然その中に配線することもできますという時に、「じゃあ皆さんは、この中に一体何を入れますか?」ということです。

まさにその箱の中に、どの部品をどういうふうに入れるかっていうのが、このコンピュータのアーキテクチャ、特にそのプロセッサアーキテクチャという分野の基本的な考え方かな? と、私はそう思っています。
その時の制約条件としては、部品とその間の配線っていうのはそれぞれ大きさがあるので、無限に詰められるわけじゃない。だからある程度、詰められる数には限界がありますよというのが、制約条件としてあるということです。
そういった制約条件の中で、じゃあ一体その箱の中に、どういう部品をどう詰め込んだら、コンピュータの処理性能が最大限に効率的に高められるか?っていうのを考えていく。それがコンピュータアーキテクチャ分野での日々やられていることかなと思います。
「ムーアの法則」が通用しない今後のアーキテクチャ
ただムーアの法則がそろそろヤバいよという話で、ルールが変わりそうという話もしましたけれども、もう1つのルールとして近年は何をどう詰め込むか以外に、消費電力についても条件が付くようになってきて、「この箱の中に流せる電流は何アンペアまで」とか、「消費電力は何ワットまで」というふうな形で制約が付くようになってきました。
そこも加味しながらベストな構成を考えていく。要するに箱の中にどういう部品を詰め込んでいったら、コンピュータの性能が高くなるかなというのを考えていくというところが難しい。これから先のアーキテクチャの世界ということが言えるわけです。
ちょっと余談的に書いていますけれども、「あとからプレイを始める人が先行プレーヤーより不利なのはどこの世界でもあることですね」っていうのはまさに、これまでムーアの法則で「(今は無理でも)たぶん来年ぐらいにはこれぐらいの回路部品が入るよね」と、それを見越して(期待して)構成を考えることもできたわけなんです。
しかしここから先はそういうのが通用しなくなって、本当に難しくなってくるよという話です。
キャッシュメモリを増やせば性能は上がるのか?
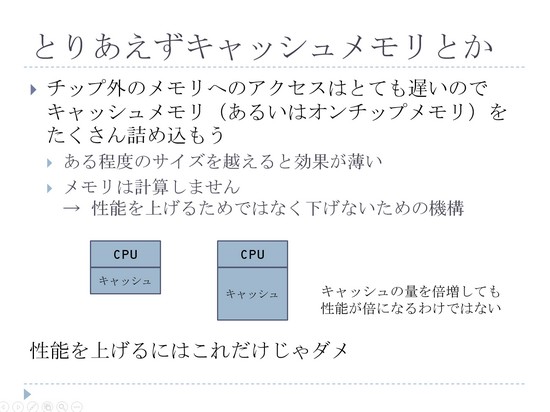
その中の詰め込むものについての話なんですが、とりあえず考えられるのはキャッシュメモリってやつです。キャッシュメモリっていうのはたぶん皆さん聞いたことはあると思いますけれども、チップ上に載っかっているCPUのすぐ近くにある小容量だけど超高速なメモリというようなやつです。
それをたくさん箱の中に入れられるんだったら、ちょっとキャッシュの量を増やしましょうという話が1番最初に考えられるわけなんです。1番下に書いていますけれども、そのキャッシュメモリっていうのは、性能を上げるための方策ではないんです。
どこを基準にするかにもよるんですが、実はこのキャッシュの正体っていうのはメモリですので、メモリは計算しません。メモリは計算しないので、いくらキャッシュを増やしたところでピークの性能っていうのは変わりません。
ピークの性能を上げるためにはこの次に言うとおり、演算器を増やすしかないんですけれども、キャッシュの量が倍になったからといって性能が倍になるわけではないので、単にその箱の中にたくさんキャッシュを詰め込んだだけじゃ、性能は上がってきません。
ILPの増強にはコストがかかりすぎる

じゃあそこで演算器のパートを増やしていきましょうということなんですけれども、一度に1命令ずつの実行から複数命令同時実行という形で、コンピュータのアーキテクチャも進歩してきたわけなんですが、大昔は1命令を何サイクルかかけて処理して、次の命令という形で進んでいたんです。
それが命令パイプラインが導入されてから、1サイクルに1命令実行できるようになってきた。その性能をさらに上げようと思ったならば、1サイクルに複数命令、2、3個同時に実行できるようにすると、それだけ速くなるよねって形で進化してきたという歴史を辿ってるわけなんです。
それをILP、命令レベル並列性と言ったりするんですけれども、その同時に実行できる命令数を増やしていけば、「プロセッサの性能というのは上がっていくよね、しばらくこれで頑張りましょう」みたいな感じで、並列処理が導入されてきたわけです。
しかしよく考えてみると、その命令レベルの並列性っていうのはそんなに高くないということがわかってきて、頑張っても10は超えない。つまり、どんなに頑張っても10倍以上速くならないということを意味するわけです。
なので、「じゃあILPだけじゃ駄目だよね」という話になる。ただ、ILPは10は超えないにしても、4とか5とか6とかぐらいだったら、頑張ればいけないこともないかなという状況です。
そのILPを増強するためのいろいろな補助的機構、具体的に言うと例えば分岐予測器とかいろいろありますけれども、そういったものを導入するっていうのは、(最初はうまくいっていたいけれどもそのうち)コストが高すぎて見返りが少ないということで、キャッシュと同じような話で分岐予測器っていうのは計算しないので、それだけでは性能が上がらないというオチになるわけです。
SIMDの並列処理で演算性能を上げる

演算器を増やすもう1つの方向性として、最近の流行ですけれどもSIMD命令です。1個の命令で複数のデータの演算を行ってしまうという形が導入されてきたわけなんですけれども、そのSIMDによって並列処理というのが導入されて、そこで結構性能が稼げるようになってきたという時代が来たんです。
ただSIMDによる制約っていうのは条件分岐に弱いという弱点がありますので、SIMDだけに頼るわけにはいかない。だからコンピュータの性能を上げるためにはSIMDだけには頼れない。SIMDっていうのは、ちょっと説明端折りましたけれども、1個の命令で複数のデータを処理するってやつです。
例えば4つのデータを同時に加算するとかそういうやつです。それだけではちょっとまだ弱いということで。ちょっとごめんなさい、時間がないみたいなのでこの辺はいろいろとちょっと資料を読んでおいてください。
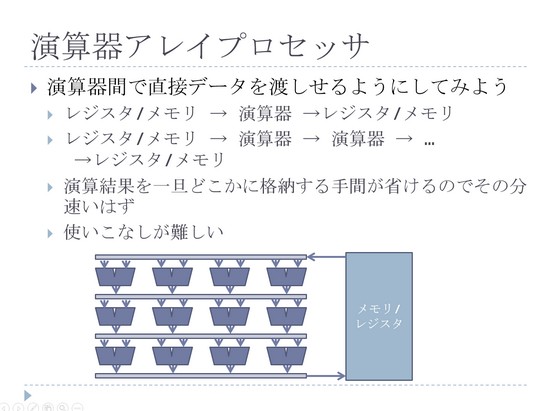
とにかく演算器を並べていくという形で、演算性能は上げていくことができます。今のSIMDは例えば1命令で4つとか8つのデータを、同時に並列計算するような形で行うのが普通なんですけれども、さらにその演算器同士を繋いで、もっと大規模かつ同時にたくさんの演算をこなすような形で構成を考えていこうという、演算器アレイみたいな話っていうのもありますよ、ということです。ちょっとごめんなさい、少し駆け足になっちゃいますけれども。
マルチコアプロセッサの登場で注目を集める「プログラムの自動並列化」

SIMD命令の次に出てきたのがマルチコアプロセッサと呼ばれるやつでして、これは名前のとおり1個のプロセッサ上に複数のコアが載っかったプロセッサです。近年のCPUっていうのは、ほぼ全てこれです。
2つの使い道としてスループット重視、レイテンシン重視という話がありますけれども、ちょっとそれの説明をしていると時間が足りなさそうなので、紹介だけしておいてあとは資料を読んでおいてもらいたいと思います。
このマルチコアプロセッサ、出てきたはいいですけれども、このプロセッサ上でプログラムを動かしたら自動的にその性能が上がるかというとそういうわけではなくて、やっぱり最初の私の自己紹介のところで出てきたような話で、プログラムを並列化してあげるという作業が必要なわけです。
プログラムを並列化してあげないと、結局複数のCPUコアがあったとしてもその中のたった1個しか使われなくて、せっかくの高性能が全然活かされないというオチになってしまうわけです。なのでプログラムの並列化、特に自動並列化に対しての注目というか、これが脚光を浴びたということになるわけです。




この辺はちょっと余談的に飛ばしまして、これもやっていると時間ないかな。
マルチコアプロセッサの構成
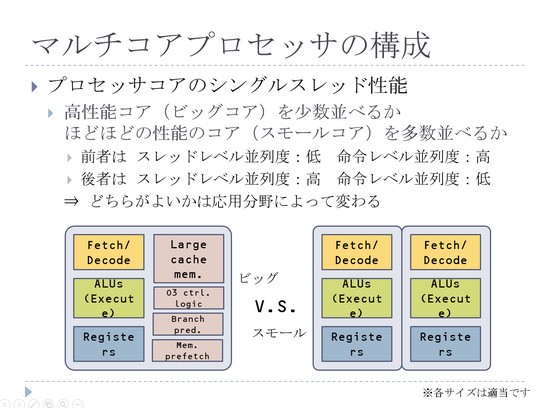
マルチコアプロセッサの構成に関して少しお話させていただきます。最初のほうで1個の箱の中に、どういう部品をどれだけ詰めますかという話をしましたけれども、実はそれと関係しまして、マルチコアプロセッサのコアについて、どういったコアを並べるか?というところで選択肢があるよという話です。例えば高性能のコアを少数並べるか、あるいはほどほどの性能のコアを多数並べるかというところで、大きく2つの選択肢があるわけです。
ここで、高性能なコアのほうはビッグコアで、ほどほどの性能のコアのことをスモールコアと言うんですけれども、ビッグコアっていうのは、最初のほうで言った命令レベル並列処理です。
命令レベル並列処理を活用して、シングルプログラムの1つのプログラムを非常に高性能に処理できるんですけれども、これを入れちゃうと当然チップ上での面積が増えますので、たくさんは載せられないです。
逆にスモールコアを使う場合には、1個のプログラムの処理はそんなに速くはないんですけれども、それを多数組み合わせて行うことで、トータルでの性能を上げようという形で活きます。このどちらがいいかというのは、実は応用分野によって変わります。
例えばシングルプログラムの性能が非常に重視されている時にはビッグコアのほうがいいですし、そうでなくて多数の、例えばサーバーの処理みたいなやつで、たくさんのトランザクションをできるだけ短時間でさばくような、1個1個はたいして命令レベル並列処理がなさそうな処理に関しては、こっちのほうが有利です。
分野によってもちょっとその辺が変わるという話もあるということです。マルチコアプロセッサの構成に関しては、こういうような大きく2つの考え方があります。
コアの非均一化による性能向上への取り組み
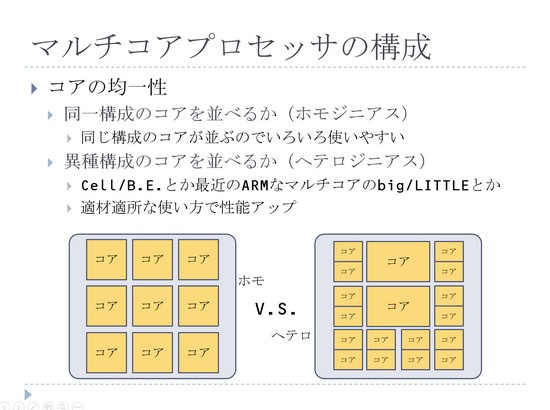
もう1つ別の考え方として、コアの均一性という話題があります。1個の箱の中にどれだけのコアを並べるかということで、同一のコアをずらっと並べるやつがホモジニアスマルチコアプロセッサです。逆にいろいろな種類のコアを取り混ぜて並べるような形、ヘテロジニアスマルチコアという、2つの考え方がありますよということです。
ホモジニアスのほうは非常に単純な話だと思いますけれども、ヘテロジニアスというのはなぜこういうことが必要になってくるかということなんですけれども、要は得意なところが違うものを時と場合に応じて使い分けられるようにしましょう、ということです。
命令レベル並列処理が重要なところっていうのは、こっち(ビッグコア)を使ったほうが性能は上がるわけなんですけれども、それだとコアの数があまり入らないので、全部をビッグコアで埋めるんじゃなくて、一部をビッグコアで残りはスモールコアにしちゃおうという選択肢もあるよということです。
その考え方に基づいて、例えばプレステ3に入っていたCell Broadband Engine、あの有名なCPUがありますけれども。それと最近のスマホとかに入っているARMプロセッサっていうのは、実は8つのコアを持っていたりするんですが、そのうちの4つずつでビッグコアとスモールコアが入っているわけです。
そんな形で、最近はヘテロジニアスなマルチコアっていうのを、ちゃんと考えられるようになってきたという時代になっています。

さらにコアの数を増やしていくメニコアの話っていうのもあるんですけれども、ちょっとこれやっていると時間ないので少し飛ばしまして。
処理性能アップの最新動向
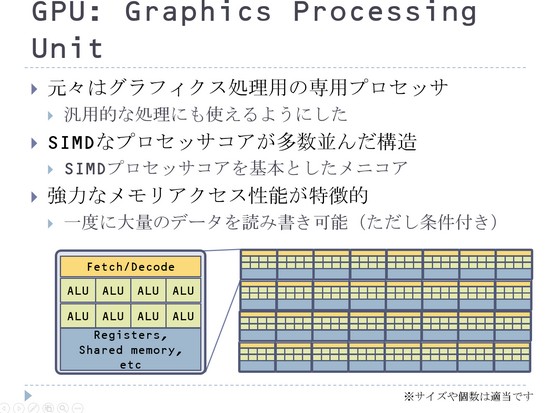
あと最近欠かすことができないのはGPUです。GPUは基本的にこんな風なSIMD処理をできるようなCPUコアがずらっとたくさん並んでいるようなものをイメージすればいいかなと思います。基本的にSIMDな処理です。
これの特徴というのは、強力なメモリアクセス性能というところがあるんですけれども、非常にバス幅が広いわけです。メモリバス幅が広くて、一度に数百ビットぐらい読み書きができるので、そこで性能を稼いでいるようなところもある。

そんなのも出てきまして、さらにそれを統合する形、CPUとGPUを統合するようなSystem-on-Chipプロセッサみたいな話も最近では出てきているという状況です。

ちょっと別の流れとしてリコフィギャラブルロジックといって、汎用の演算回路じゃなくて専用の回路を自由にコンフィギュレート(再構成)できるようなデバイスを載っけようという話もあります。

あと、特定処理専用のアクセラレータというのがちょっとおもしろいんですけれども、本当に特定の用途にしか使えない回路をとりあえず入れておいて、使わない時はスイッチを切っておく。
どうせトランジスタの中にはたくさん回路が入れられるので、入れられるだけ入れておいて、使う時だけ電源入れてそれ以外の時には切っておきましょうというような流儀で、その特定の処理の時には加速するような考え方というのも出てきたということです。
(補足:近年はダークシリコン問題といって、チップ上にたくさんの回路が集積できるようになった結果、回路が多すぎてすべての回路を同時に動かすと電力が不足して回路が動作させられないという状況が問題となってきました。そのため、どうせ同時には使えないのだったら、ごくたまにしか使えない回路でも入れておいて、使えるときだけ使う(そのときは他の部分の回路の電源を切る)。使えないとき(通常時)は電源を切っておけばいいという考えも出てきました。)

最新動向の紹介というか、ちょっとここら辺はあとで読んでおいてください。あとで直接捕まえてくれれば、お教えしますけれど、トップカンファレスあたりの論文を読んでそこら辺から、研究ネタそのものではなくてその研究の流れを掴んでネタを掴むというようなことを考えたほうがいいんじゃないかなと私は思います。
新しい考えで広がる可能性

キーワードとしてずらっと並んでいますけれども、おもしろいのは1番最後のエラー忘却型コンピューティングというやつです。コンピュータっていうと基本的に信頼性があるものというのが前提で考えられているわけなんですけれども、あえて信頼性を捨てることで開ける道もあるということです。
例えばこれまでの話の中でも、最適じゃないけども準最適なものを求められれば十分というような話もありましたけれども、そういったところに着目してメモリのビットが多少化けたり、演算器の計算が多少間違っても、結果としては何か最適な答えが見つかるようなものがあれば、それはそれでいいという考え方です。
 ちょっと駆け足になっちゃってごめんなさい。あと全国大会の告知ということで、この明日からの全国大会で、いくつか関連する分野の発表、結構こんなありますので、ぜひ聞いて、楽しんでいただければいいかなと思います。すみません。駆け足になりましたけれども、今日はこれで終わりたいと思います。どうもありがとうございました。
ちょっと駆け足になっちゃってごめんなさい。あと全国大会の告知ということで、この明日からの全国大会で、いくつか関連する分野の発表、結構こんなありますので、ぜひ聞いて、楽しんでいただければいいかなと思います。すみません。駆け足になりましたけれども、今日はこれで終わりたいと思います。どうもありがとうございました。