ヤフーにおけるHadoop Operations
安達寛之氏(安達):ご紹介ありがとうございます。ヤフーの安達です。タイトルのとおり「ヤフーにおけるHadoop Operations」について話をさせていただきます。先ほどの2件はデータ基盤全体に関する話だったのに対して、Hadoopの話になってしまうんですが、「業務でHadoopを使ってるよ」という方、どのくらいいらっしゃいますか?
(会場挙手)
その中で、「運用もしています」っていう方はどのくらい?
(会場挙手)
わかりました。「Hadoopについて」になってしまいますが、よろしくお願いします。
ということで、まず自己紹介です。安達寛之といいます。2016年の4月にヤフー株式会社に入社し、そこから1年半ほど、Hadoopのバージョンアップ自動化や、チューニング、運用の自動化といったことに携ってきました。今年の4月からは、Hadoop運用チームのリーダーという立場になっています。

今日のアジェンダです。

まずはヤフーについて、また扱っているデータ基盤について少しご紹介させていただきます。その後、Hadoop環境についてと、私が所属しているHadoopチームについて紹介いたします。
その後、実際の運用の事例として、Hadoopの運用の自動化にいくつか取り組んでいるのでそれについて紹介させていただきます。最後にこれからの成長に向けて少し考えていることを話そうと思っています。
では、さっそく。まずはYahoo! JAPANについてです。だいたい100以上のサービスを提供させていただいています。Yahoo!のトップページや、ショッピング、GYAO!などの動画サービスであったり。あとはYahoo!地図とか、Yahoo!天気や乗換案内といったような、いろんなサービスを提供しています。

これらのサービスのログデータが収集され、主にHadoop上で処理されています。だいたい月あたり713億PV、DUBが9,000万、MAUは4,300万といったような規模感になってます。
成長するヤフーの取り組み
先日の決算発表の資料から持ってきたんですけど、ビジネスはどんどん成長しています。
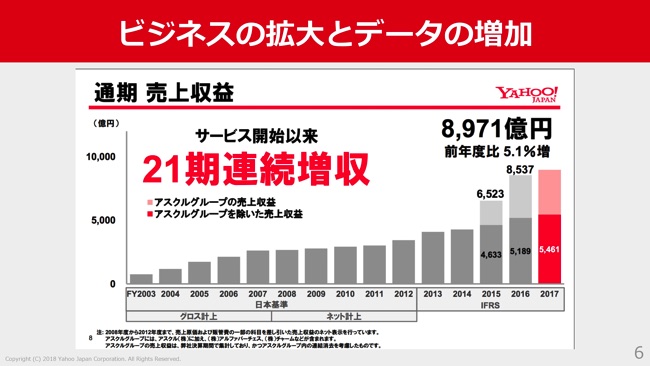
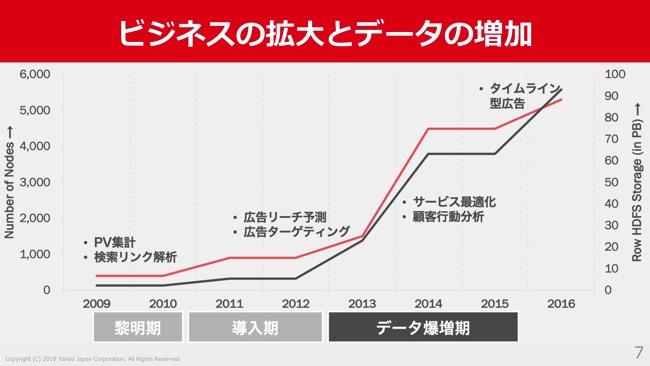
Hadoopのノード数の増加もあわせて見てみると、2009年などは非常に少なかったですが、2013年あたりからデータ量の増加に伴って、Hadoopの規模もどんどん大きくなってきています。
その他のデータ基盤についてもあわせて見ていきたいと思います。まずHadoopは現在だいたい4,100ノードぐらいあって、120ペタバイトぐらいの容量があります。
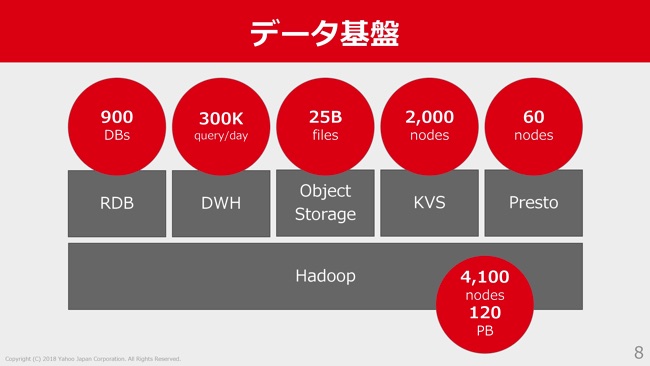
その他にMySQLなどのリレーショナルデータベースが900データベースぐらい。データウェアハウスや内製のオブジェクトストレージ。Dragonと呼んでいるS3互換のオブジェクトストレージが25ビリオンファイルぐらいあったり、あとはKVSとか、Prestoといったものを使っています。
その他に、最近弊社は「マルチビッグデータドリブンカンパニーを目指す」と謳っていまして、いろんなところに投資をしています。
左にあるのがスーパーコンピュータのkukaiというもので、ディープラーニングを活用したデータの解析やサービスのパーソナライズの信頼性向上といったものにこのスーパーコンピュータを活用しています。電力効率を考慮した演算性能の世界ランキングGreen500というものでトップ2になる、といった成果を収めています。

右側に書いているのが、データフォレスト構想というもので、こちらも最近アナウンスをしたんですが、先ほど言ったようにヤフーが持っている100以上のサービスのデータを、社外のみなさまと一緒に活用していって、全体でより良くしていこうというものです。
また、これも最近なんですが、弊社にCDO、Chief Data Officerという役職を設けまして、社内で扱うデータをどういうふうに今後活用していこうかといったことを、統括して考えるポジションができました。
こういったかたちで、データドリブンカンパニーの取り組みをしています。
Hadoop環境の紹介
そんななか、ヤフーのHadoop環境とそれを運用しているチームがどういうふうになっているのか紹介させていただきます。
こちらがHadoopクラスタ、4,100台あるノードのうちの一部で、一番メインで使われているクラスタになります。

HDPという、Hortonworksが提供しているHadoopのディストリビューションを使用し、それをAmbariという管理ツールを使って運用しています。
約1,500ノードぐらいで構築されていて、特徴的なのは3種類のタイプのスペックの違うサーバーが混ざっているというところかと思います。
1つ目は、サーバーの上にDataNodeというデータを蓄積するノードと、NodeManagerという処理を行うノードがそれぞれいるという、標準的なかたち。
2つ目は、そのType1のディスクの容量が大きくなったもの。
そして3つ目のタイプは、処理用のデーモンしか動いてない。こういったようなサーバーになってます。
従来Hadoopでは、データのローカリティを意識して、データを持っているサーバーと処理するサーバーをできるだけ近くするという考えで構成されてたんです。
しかし弊社のHadoopはCLOSネットワークという、ネットワークの距離をあまり意識しなくてもいいネットワーク構成になっていたり、強いネットワーク環境においては、あまりデータのローカリティは処理には影響しないということで、今のHadoopクラスタはこのような構成になっています。
そのHadoopの上で動いているコンポーネントについて、少しご紹介します。まず一番下のファイルシステムのレイヤーにHDFSという分散ファイルシステムがいて、その上のリソースマネジメントとしてYARNがいます。
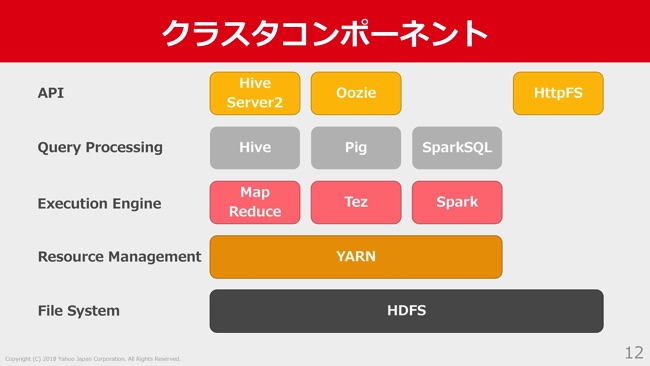
そして、このYARNの中で、いろんなHadoop上のジョブが実行されることになります。その実行エンジンとして、Map Reduceや、Tez、Sparkがいて、それをSQLライクにかけるHive、Pig、SparkSQLみたいなものを使ってジョブを実行しています。
また、それらに対するAPIとして、HiveServer2であったり、ワークフローのOozieであったり。あとはHDFSへのアクセスAPIとしてHttpFSといったようなものを、このクラスタでは提供しています。他に、我々の運用チームでは、このHadoopクラスタだけでなく、認証用のKerberosの環境や、LDAPいったものも、管理しています。
このHadoopで扱ってるデータ量とワークロードについて少しお話します。左側がHDFSの使用量で、現在だいたい約37ペタバイトぐらいのデータが保存されています。
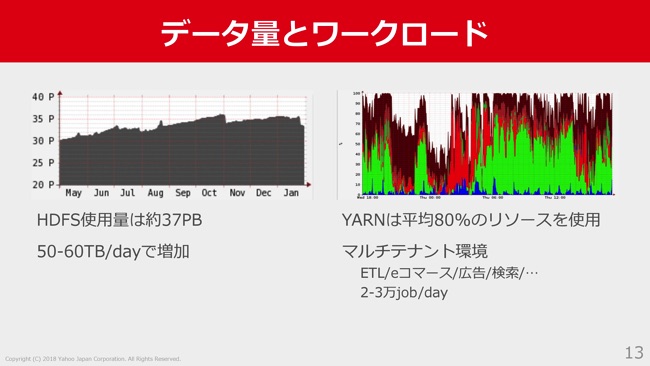
これが5、60テラバイト・パー・デイぐらいで増加していってる、といったような規模です。
YARNのほうは平均でだいたい80パーセントぐらいリソースを使っています。弊社のHadoopクラスタはマルチテナント環境になっていて、いろんなサービスやチームの方が、この1つのHadoopクラスタを共有して使うといった状況です。
このなかでETLのジョブや、そのETL処理されたデータを使い、eコマース、広告や、検索などのいろんなサービスの人たちがこのデータを利用する、といったようなかたちになっています。この図で色分けされてるのが、そのそれぞれのサービスに応じたキューです。
こちらは1日あたりだいたい2万から3万ジョブぐらい実行されています。
チーム再編成で自動化を運用に取り入れる
ここまでがHadoop環境の説明で、ここからは少しHadoopチームの変遷について、ご紹介したいと思います。ここ2年ほど……というか、私がHadoopチームに入ってからの変遷になるんですけども。
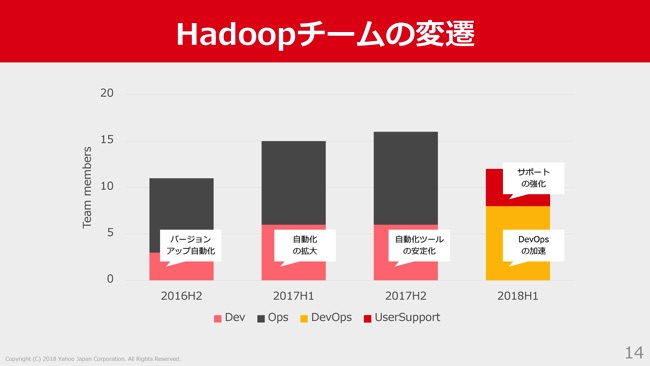
まず2016年の後半、H2に、Hadoopのバージョンアップ自動化のためのタスクフォース的なチームとして、3人でこれに取り組みました。詳細は後ほど話をさせていただくんですけれども、これまでなかなか自動化できていなかったので、このタイミングでスモールなチームをつくって、目線をそろえてこのタスクに取り組もうということで、このようなチーム編成になりました。
申し遅れたんですけど、ここで「Dev」と言ってるのは、あくまで運用ツールの開発です。Hadoop本体に関するコントリビュートとかではないです。
2017年のH1は、自動化ツールの拡大ということをメインで取り組みました。2016年にいい感じで自動化をすることができたので、今度はそれを定常運用作業に広げていこうという流れで、この自動化の規模というのを少し拡大しました。
そして、2017年H2も、少しメンバーの入れ替わりはあったんですけども、だいたいこの自動化の拡大の継続と自動化ツールの安定化に取り組んできました。
そしてこの4月からは少しチーム編成が変わり、これまで運用ツールを主に自動化して開発していたチームと、主にクラスタの運用や問い合わせの対応をしていたチームが1つになって、DevOpsのチームになって動き出しています。そして、冒頭で申し上げたとおり、私がこのDevOpsチームのリーダーとして今期は取り組んでいます。
本来運用ツールを開発してる人たちとそのツールを使って実際に運用作業をする人たちは、同じチームであるべきだろうという考えのもとでこういうふうになりました。
こうやって1つにすることで、さらに自動化を運用に取り入れていこうと。そして、それをリリースで修正してまたリリースするっていう、DevOpsのサイクルをどんどん加速させていこうという、よくある意図で、こんなふうに今期はなっています。
そして上のほうで「サポートの強化」と書いているのは、ユーザーサポートを専門に行うチームを切り出して、今期はそちらにも注力するということです。このようなかたちで、少しずつHadoopの運用に自動化の要素を取り入れているといったのが、近年のヤフーのHadoopチームの動きです。
少し文字でまとめますと、こういう感じですね。まず自動化の第1歩として、バージョンアップというか、限られたタスクの自動化に取り組みました。それを定常運用作業にも拡大していって、いったんその開発したツールを安定化させます。
今度はそこで培ったノウハウをもって新しいチームに編成し、さらに加速させていこうという動き。一方で十分にできていなかったユーザーサポート部分に注力するチームとして切り出してやっている、といったようなところです。
クラスタバージョンアップの事例紹介
ではここから、運用の自動化の事例として、3つほどご紹介させていただきます。

まず1つ目が、クラスタのバージョンアップの自動化です。こちらは先ほど言ったように、2016年の後半に取り組んだものです。先ほどの発表でもありましたが、Hadoopのバージョンアップというのはけっこう影響の大きい作業で、運用者にとっての負担も大きいですし、利用者もクラスタが利用できなくなるといった影響が出てきます。それを自動化することで、いい感じにしていこうという取り組みでした。
2つ目がセキュリティ対応の自動化。どうしても時間がかかってしまうけどやらないといけないセキュリティ対応を、どういうふうにやっていくかという話です。
最後は、どうしてもサーバーが壊れたりしますので、その対応をどういうふうに自動化しているか。この3つの事例を紹介させていただきます。
では、まずこのバージョンアップの自動化の背景についてですが、以前のバージョンアップ作業の実績として、12時間×10人でこの作業をやったというのがあります。これだけの時間、運用者が張りついて対応し、似たような作業を行っていたという問題がありました。

一方で、このメンテナンスの間、利用者はHadoopを使うことができなくて、ビジネスに与える影響が非常に大きかったという問題もありました。運用者にとっても、長時間Hadoop上の処理が止まってしまうとなると、いつ実施するかというスケジュールの調整や、メンテナンスが終わった後も、利用者全員が一気にクラスタを使いだすとリソースが足りなくなってしまうのでそのあたりの運用の調整といったようなものが必要な状況でした。
これらに対して、まずはユーザー影響を出さない、ということを目的に取り組みました。具体的には、ユーザーが実行するジョブとか、HDFSのデータの読み書きを失敗させない、その他、提供しているコンポーネントがきちんと動作をする状態にしましょう、ということです。
2つ目は、運用コストの削減ですね。Hadoopの、HA構成しているサーバーであったりとか、約1,000台、今だと約1,500台の大量のノードで同じような作業があるので、そこを削減したい。そのために、自動化できるものは自動化しましょう、といったような目的がありました。
具体的な方法として、1つ目のほうについては、データの読み書きに影響を与えないために、HDFSが持っているファイルのブロックの情報を監視して、あるHDFSのサーバー群をリスタートするタイミングを制御しました。あとは、冗長構成になっているコンポーネントを安全な方法でそれぞれバージョンアップしていく、というふうに取り組みました。
クラスタバージョンアップの詳細と結果
2つ目のほうですが、これまでは人がやっていたUI操作などを、APIを使ってコマンドで実行できるようにします。そのうえで、Ansibleを使ってバージョンアップフローを自動化しました。
ここで、AmbariとHadoopクラスタがどういうふうになっているかというのを、少しご紹介したいと思います。
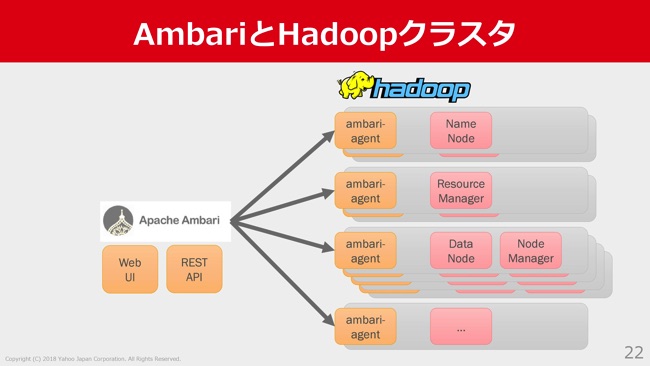
我々はHadoopクラスタの管理にApache AmbariというOSSのHadoopの管理ツールを使っていて、普段はこのWeb UIを操作して運用をしています。各サーバーにはこのAmbariのエージェントがいていろんな命令を実行することができます。このAmbariはREST APIも備えているので、これを通してコマンド化してオペレーションする、という感じになります。
また、ご存じの方も多いかと思いますが、Ansibleは構成管理ツールの一種です。これを使って、バージョンアップ全体のフローをコントロールしました。ChefとかPuppetといったツールもあるんですけど、Ansibleを使った理由としては、Chefと比較した時に学習コストが低いということと、順序制御がやりやすいということがあり採用しました。

本当に単純なコードを書いていますが、yaml形式で書けて、タスクを書いた順番に順次実行していってくれるので、まずはこの処理を実行して、その処理がちゃんと全部終わってから次の処理を実行する、という順序制御が非常にやりやすいかたちになってます。
こういう感じになって、バージョンアップフローについてはこのようになってます。
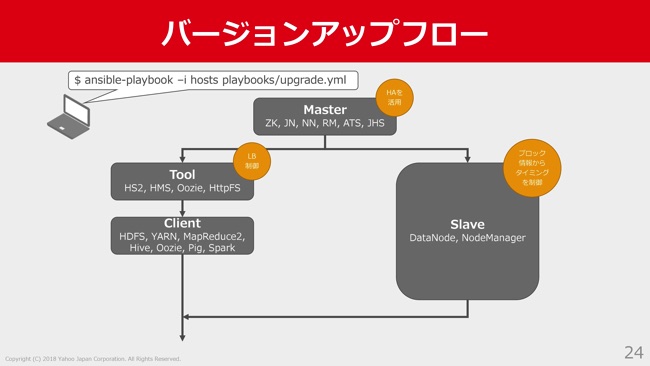
運用者はansible-playbookのコマンドでアップグレード用のplaybookを1つ実行し、それが実行されると、まずHadoopのマスター系のサーバーが処理され、いろんなツール群やクライアント群を処理しつつ、並行してDataNodeとNodeManagerが処理されていく、といったような流れになってます。
マスター系についてはだいたいのノードがHA構成を機能として持っているので、まずスタンバイをアップグレードし、その後フェイルオーバーさせ、元アクティブ系をバージョンアップさせるといったように、このHA構成を活用して安全に作業をしました。
また、ツールのほうは、標準では冗長構成を持てていないんですが、我々はロードバランサを使ってこれを冗長構成にしているので、Ansibleの中からロードバランサに対する操作をし、いったんアップグレード対象をロードバランシングから外してアクセスされないようにして、それをアップグレードした後また戻すという、部分的なブルーグリーンデプロイメントのようなことをやって、安全に作業しています。
そしてDataNodeやNodeManagerみたいなものの処理について。DataNodeからいくと、これはHadoopが管理するファイルのブロック情報を持っているので、なにも考えずにこれらを大量にバージョンアップ作業してデーモンをリスタートしてしまうと、データの欠損というか一時的なアクセス不可という状態が発生してしまいます。
どうしてもこの状態にしたくはなかったので、一定の台数のDataNode群をリスタートしてそのブロック情報がきちんとレプリケーションされるのを待ってから、次のDataNode群をリスタートするというタイミングの制御もすべて自動化して、ツールの中でやっています。
これらDataNodeとかNodeManagerといったものは、約1,500台というすごい台数があるので、これを人の手でやろうと思うとすごいオペレーションを何回もやらないといけない。その間、待ち時間もあったり、対象によって必要となる時間もまちまちなので、自動化してツールに制御を任せるのが非常に向いているものだと感じています。
このようにして、処理を自動化した結果、以前と比較するとこんなふうになりました。

クラスタの停止時間、以前のバージョンアップでは12時間完全に停止していたのに対して、今回は7分だけになりました。
メンテナンス時間は、先ほどのDataNodeとNodeManagerを適切なタイミングでリスタートし、その待ち時間の影響で長くなっているんですけれども。実際のオペレーションとしては、1個playbookを実行して放置しておくだけになるんで、工数としてはぜんぜんかかっていない。人も減って、必要な時間も減って、もともと108時間に対して21時間と、大きく減らすことができました。
この自動化用のplaybookをつくったのは2016年の後半だったんですが、その後も何回かバージョンアップをして、非常に役立っています。