DACにおけるTresureData活用法
河原亮介氏:よろしくお願いします。河原です。弊社ではAudienceOneというデータマネジメントプラットフォームを提供しておりまして、そこで今日はどのようにTreasureDataを使っているのかをお話ししたいと思います。
あらためまして、簡単に自己紹介です。河原亮介と申します。

今はプロダクト開発本部という、主に自社サービスの開発や運用を行なう本部におりまして、いろいろやってはいるんですが、主な業務としてはAudienceOneの開発責任者をやっています。
TreasureData歴ですが、弊社は2012年ぐらいから使い始めているので、5年半くらい使っているかたちです。私はDAC(デジタル・アドバタイジング・コンソーシアム株式会社)に2008年に新卒で入社して、今年11年目になっています。
本日のアジェンダになります。たぶんみなさん、あまりDACってご存じないかなと思うので、簡単に会社紹介させていただきます。

あと、弊社は2012年からTreasureDataを使っていて、かなり……、というかけっこう使っているので、どれぐらい使っているのかのご紹介をさせていただきます。
本題として、AudienceOne、データマネジメントプラットフォームでTreasureDataをどのように使っているのかというところをお話しさせていただきます。
今日はなに話そうか迷ったんですけど、3つ。ワークフローの部分。あとTreasureData以外のデータベースサービスもいくつか使っているので、それをどういうふうに使っているのかというところ。あとデータマネジメントプラットフォームとしてデータのモニタリングってけっこう重要だったりするので、どういうふうにやっているのかというところをお話ししたいなと思っています。
AudienceOneでどのくらいTreasureDateを使っているか
会社の紹介です。会社名が長いのですが、弊社は1996年に設立された会社で、けっこう古いですね。

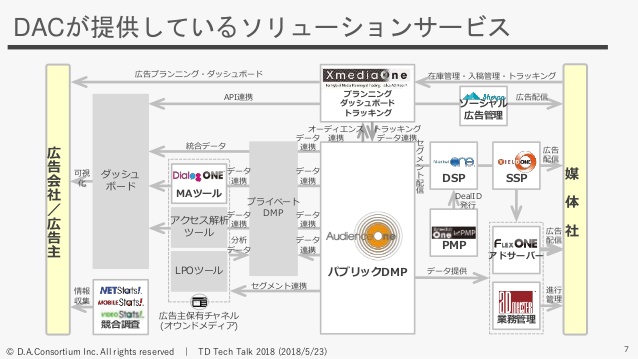
メインのビジネスとしては、インターネット広告の仕入れ・販売をやっています。最近だと、AudienceOneをはじめ、自社サービスをたくさん開発していて、そういったソリューションサービスの提供も行なっています。
会社の規模としては、売上高はここに書いてあるとおりですね。従業員数も2,000人ぐらいの規模になっています。ざっくり言うと、要するにインターネット広告の会社だと思っていただければいいかなと思います。
いまお話ししたように、弊社はDMPをはじめ、さまざまなテクノロジープラットフォームを提供しています。ここにいくつか挙げていて、DSPだったりSSPだったり、アドサーバだったり、けっこういろんなアドテクのソリューションを提供しているような会社になっています。
ざっくりいうと、いろいろとアドテクをやっている会社だと覚えていただければいいかなと。
続いて、弊社はどれぐらいTreasureDataを使っているのかを簡単にご紹介させていただきます。先ほど弊社で自社開発して提供しているサービスを出したんですけど、AudienceOneをはじめ、実は弊社のプラットフォームのほとんどでTreasureDataを使っていて。
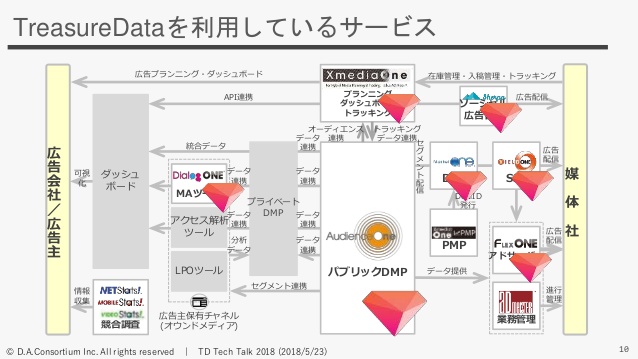
がっつり使っているようなところもあれば軽く使っているところもあるんですけど、弊社の場合ほとんどのサービスでTreasureDataを使っています。
実際どれぐらい使っているのか数字で出してみました。

いまTreasureDataのユーザー数、ログインのアカウント数が200ぐらい。インポートしているレコード数とジョブ数は、TreasureDataのコンソールから引っ張ってきたんですけど、だいたい1日80億レコードぐらいのデータをTreasureDataに入れています。
TreasureData上で走るジョブの数が、HiveとかPresto、Deleteのジョブとかもろもろ合わせてだいたい1万5,000ぐらいになります。だいたい1日で、Hiveで4兆ぐらいの、Prestoで300億ぐらいのレコードを処理していて、大規模にTreasureDataを使っています。
ここからやっと本題で、AudienceOneでどのようにTreasureDataを使っているかをお話しさせていただきたいのですが、簡単にAudienceOneについて紹介させてください。

AudienceOneは、一応自称なんですけど、国内最大規模のデータをもっているデータマネジメントプラットフォームになっています。ここに書いてあるとおり、約4.8億のブラウザのCookieだったり、9,000万ぐらいのモバイルの広告IDを持っています。
ここに書いてあるように、AudienceOneでいろいろできるんですが、特徴・強みとしては、よくパブリックDMPとして分類されることも多いんですけど、サードパーティのデータをたくさん持っていること。あと、弊社はインターネット広告の会社なので、広告配信に強いデータマネジメントプラットフォームになっています。
3つのトピックス
AudienceOneにおけるTreasureData活用方法というところで、最初にも話したんですけど、今日お話しするのは3つです。
ワークフローの管理でLuigiとTreasure Workflowを併用しているんですけど、どういうふうに使い分けているのかって話ですね。それと、TreasureData以外のサービス、RedshiftやElasticsearchなんかも使っているんですけど、どういうふうに使っているのかというところ。あと、データのモニタリング・監視をどうやっているのかをお話しします。
「その前に」……、が多くて大変恐縮なのですが、AudienceOneのシステム全体の構成図じゃないんですけど、データ周りの構成だったりフローを簡単にご紹介します。いっぱい書くと書ききれないので、今日話すところに関係するところと重要なところをざっくり書いてきました。
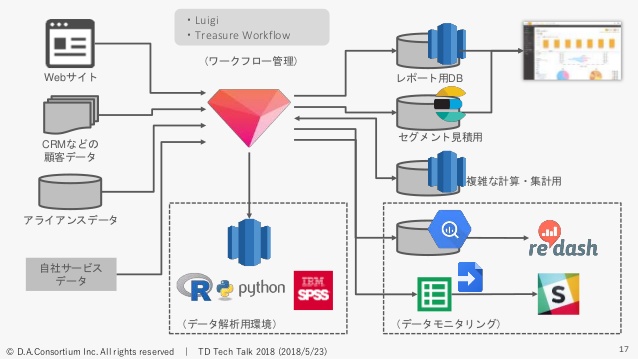
AudienceOneでは、TreasureDataをメインのデータ処理基盤というか集計基盤として利用しています。なので、AudienceOneに入ってくるデータというのは、AudienceOneで提供しているWebサイトのログを集めるようなトラッキングのログですね。こういったところ、これをFluentd経由で入れていたりとか。
あとAudienceOneを利用しているお客さんが会員情報とかCRMのデータを入れたりとか。あとはAudienceOneでデータを保有しているパートナーさんといろいろアライアンスを組んでいるので、そういったデータもTreasureDataに入れています。あとは、弊社でDMP以外のDSPやアドサーバというようなサービスのログもTreasureDataに入れています。
さっきもお話ししましたが、ワークフローとしてはLuigiとTreasure Workflowを使い分けているようなかたちです。
このあともお話しするんですが、TreasureData以外にRedshift。これはAudienceOneの管理画面なんですけど、管理画面から参照する用のレポートだったり。これも後ほどお話ししますけど、見積もり用のElasticsearchだったり。あと、TreasureDataでできなくはないんですけど難しかった複雑な計算・集計だったりというところですね。右下がデータのモニタリングで、BigQueryとかre:dashとか、あとSpreadSheetとか使ってモニタリングしているようなかたちになっています。
今日はあんまりお話ししないんですが、データ分析環境としては別にあって。ここに書いてないんですけど、もともとIBMさんのPureData、昔Netezzaと呼ばれていたデータウェアハウスですね、それを使ってたんですけど、いまはそれをRedshiftに移し替えているようなかたちですね。
いわゆるデータ解析チームというかデータサイエンティストが、ここに対してRだったりPythonだったりSPSSを使ってデータの解析や分析をやっているような感じになっています。
今日お話しする3つというのが、ワークフローの話と、データベースの使い分けの話と、モニタリングの話をしていきます。
ワークフローの使い分け
まず1点目がワークフローの使い分けです。最初に「AudienceOneにおけるデータ開発のフローってざっくりどうなっているの?」というのがここに書いてあります。
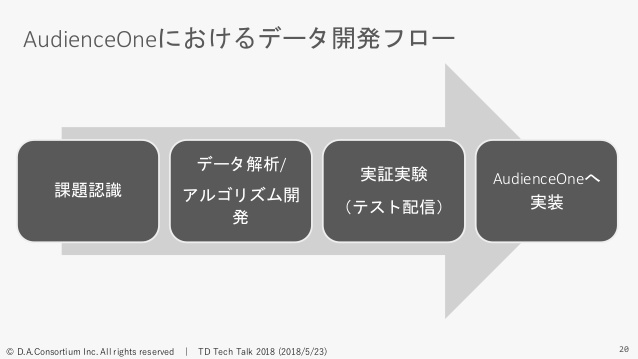
AudienceOneは先ほどお話ししたように、サードパーティデータを多数持っているのが強みなので、データの開発を日々やっています。
どういうフローでやっているかというと、なにかしらの課題があって、それに対してそれを解決するようなデータ解析だったりアルゴリズムの開発をデータ解析チームが行ないます。もちろんこれは弊社のデータだけではなくてアライアンス先のデータも含めて行なっているようなかたちです。
ある程度内容が固まってくるというか「これでいけそうだな」ってなると必ず実証実験みたいなものを行なうんですね。弊社の場合、広告の配信、ターゲティングでの利用が多いので、括弧書きで書いてますけど、テスト配信、テストで広告配信するようにして実際に効果検証を行なって、それが有用で効果があればAudienceOneの機能として実装していく、というようなフローで開発することが多いです。
ワークフローをどう使い分けているかというと、フェーズで使い分けています。実証実験のようなフェーズだとTreasure Workflowを使っていて、AudienceOneの機能として提供する場合は、いまはLuigiを使ってワークフローを管理しているようなかたちになっています。
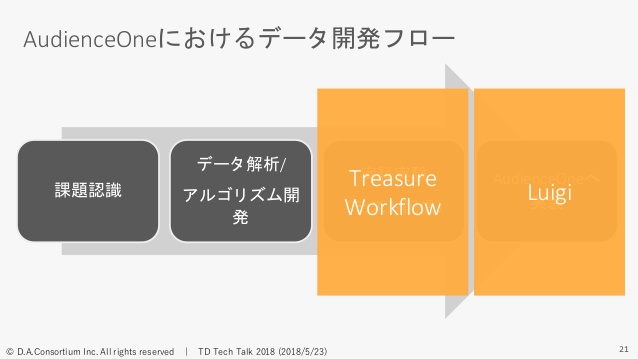
Treasure Workflowをこのフェーズで使っている理由として、yamlで簡単に書けるので、SQLさえ書ければ、極端な話、非エンジニアでもちょっと勉強すればワークフローをかけると。
一番いいと思っているのは低コストで短期で導入が可能というところ。実証実験なのでとりあえずまずやってみるというところが大事かなと思っているので、そういった意味ではTreasure Workflowは手軽にワークフローを組めるので非常にいいかなと思っています。
逆にAudienceOneの機能として実装する場合は、それなりの品質も必要ですし、あと汎用化するので実証実験フェーズよりも多少処理も複雑になるというところで、Luigiを使っています。
AudienceOneでけっこういろんなバッチ処理が動いていて、かなり複雑な……、かなりというかめちゃくちゃ複雑なんですけど。かなり複雑な依存関係でも、簡単にとは言わないですけど、管理しやすいのがLuigiかなと思っています。
どれぐらい複雑かというと、多いものだと7〜8個の集計処理を待ってから起動するバッチ処理があったり、逆に1個の処理が終わるとその後続で70個ぐらいのバッチ処理が動き出すみたいな、それぐらい依存関係が複雑なのでLuigiを使っています。
データベースの使い分け
続いて、TreasureData以外のデータベースの使い分けです。絵でいうとこの部分ですね。
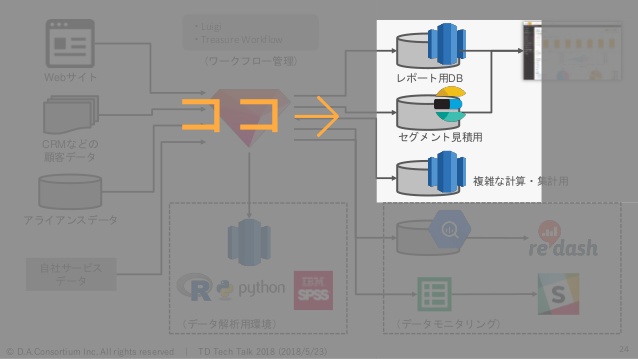
1個ずつ上から簡単に説明していきます。「Redshiftその1」ですね。これはなにに使っているかというと、AudienceOneのレポートデータを入れるために使っていて、実際のレポート画面から直接参照しています。

ログっぽいデータは入ってなくて、集計されたデータだけ入っています。集計されたデータだけなんですけど、レポートの種類とか分析の軸が多かったり、あと保持期間も多くて、けっこうレコード数が多くなっています。
AudienceOneのレポートの内容としてはユニークユーザーのレポートがほとんどになるので、集計軸が増えれば増えるほどレコード数も増えちゃうというような話ですね。なので、ここにも書いていますけど、現状で約110億レコードぐらいあるので、今はRedshiftを採用して使っているというような状況になっています。
次にElasticsearchです。これをなにに使っているかというと、AudienceOneの管理画面上でセグメントサイズの見積もりができるんですけど、それに使っています。

セグメントサイズの見積もりってなにかというと、AudienceOneの管理画面上でいろんなセグメントを定義できます。例えば、なにか特定のURLに直近1ヶ月で2回来たとか。かつ、それに男性をかけ合わせたりとか。かつ、それにサッカーに興味がある人をかけ合わせたりとか。もちろんANDの条件だけじゃなくて、ORだったりとかNOTの条件とか、けっこう複雑な条件も設定できるんですね。
AudienceOneを利用しているユーザーというのは、セグメントを作成するときにざっくりどれぐらいのユーザー数がいるのかを必ず確認します。広告配信の場合は、すごくいいセグメントでも、ユーザー数が少ないと結局広告配信できないので、ユーザー数を事前に確認できるというのが非常に重要です。かつ、細かく条件を変えながらどれぐらいのUU数になるかを管理画面上で確認します。
なので、レイテンシはできるだけ低いほうがよくて。この機能の性質上どういう条件が入ってくるかわからないので、事前の集計は一切できないです。
ただ、いいところとしては、ざっくりのボリュームがわかればよくて、10万なのか50万なのか100万なのかというのがわかればいいので、精度はそこまで求められません。なので、このElasticsearchにはサンプリングされたデータ、ローデータに近いものを入れて、管理画面から参照しているというような使い方をしています。
AudienceOneの拡張機能
続いて「Redshiftその2」です。これはAudienceOneの拡張機能、いわゆるLookalikeと呼ばれるような機能で使っていて。このAudienceOne拡張機能ってなにかというと、すごく簡単にいうと似たユーザーを探すような機能で、具体的な使い方としては、会員登録とか、コンバージョンしたユーザーに似たユーザーを抽出する。まだコンバージョンしていないんだけど、しそうなユーザーを抽出するような機能になっています。
AudienceOneの拡張というのが、個別にモデリングを行なっています。個別というのは、管理画面でAudienceOneを使っているユーザーさんが個別に依頼をかけて、それごとにモデリングをしているというかたちになっています。
なので、いま現状モデルが3,000ぐらい登録されていて、そこから作られるセグメント、いわゆるモデルからスコアリングしてそこから作られるセグメントが4,000ぐらいあるようなかたちになっています。
モデルが個別になっているので、スコアリングするときの処理のSQLも違いますし、そこから作成するセグメントを抽出するSQLも全部違います。
かつ、更新頻度は毎日。元データが日次で更新されるのでセグメントの内容も日次で更新する必要があると。元データがいま約40億レコードあるので、これ何回かTreasureDataで実装しようと試みたんですけど、なかなか処理が回らなくて、いまはRedshiftでやっているというようなかたちになっています。
データのモニタリングと監視
最後、データのモニタリング・監視についてお話しします。モニタリングしている内容をいくつか、いくつかというかもっとあるんですけど、ざっくりいうとこの3つかなと思って3つ書いてきました。

1個目はトレンド、というかユニークユーザー数の推移。OS別だったりブラウザ別だったり。直近だと、Safari 11ってアドテク事業者にとってはけっこうクリティカルなので、リクエスト数がどれぐらいあるかとか。
あとはデータの精度ですね。先ほどのオーディエンス拡張のモデルの精度。単純なところでいうとAUCの数字見てたりとか。あとはAudienceOneでは推定のデータ、性、年齢とか、男性・女性とかという推定データを持っているんですけれども、その推定データの精度の確認というのをやっています。
確認をどうやってやっているかというと、データのアライアンス先からいくつか確定データというか正解データをもらっているので、そこと突き合わせて、合ってる・合っていないという検証というかモニタリングをしています。
あとは、急激になにかが増えたとか減ったとか、異常値に近いようなものもモニタリングしています。
これをそれぞれどうやっているかというと、上2つはre:dash+BigQuery、TreasureDataに直接re:dashからクエリ投げることもあるんですけど、使ってやっています。急激な減少とかはSpreadSheetとAppsScript、プラス、なにかあったらSlackに通知するというかたちでいまやっています。

re:dashなんですが、データソースはBigQueryとTreasureData。これはPrestoを使ってやっています。ローデータに近いものはそれなりにサンプリングしてもデータ量が多いのでBigQueryに入れてやっています。ある程度集計された値のモニタリングはTreasureDataに格納して、Prestoでre:dashからクエリを投げてダッシュボードに表示するというようなことをやっています。

なぜre:dashを使ったかというと、僕は開発チームなんですけど、開発チームだけじゃなくてデータ解析とかデータのプランニングとかオペレーションを行なうようなビジネスサイドに近いほうも見れるので、一応re:dashを採用したというような経緯になっています。
SpreadSheetとAppsScript、Slackですね。これは1時間ごとや日ごとや週ごとに、だいたいUU数の集計なんですけど、UU数を集計してSpreadSheetに出力します。TreasureDataにクエリを投げてSpreadSheetに出力しています。

そこからAppsScriptで、何パーセント減少。先週と比べて10パーセント減ったとか20パーセントとかというのを検知してSlackに通知しています。実際のSlackの通知は、大事なところ隠してますけど、こんなかたちで通知するような仕組みになっています。
ここはけっこう難しいというか、AppsScriptでやるので、簡単に定義できる異常だけをここでやっています。人の目で見ないとなんとも言えないってものはre:dashでモニタリングしています。なので、システム監視とかに近いようなものをSpreadSheetとAppsScriptかSlackを使ってやっています。
重いクエリが投げられていないか監視
最後におまけというかネタ的な要素なんですけど、弊社は先ほどお話ししたとおり、最初に200人ぐらいTreasureDataのアカウントを持っています。その中には、エンジニアもいるんですけど、非エンジニアや新卒で入った人もいて、たまに……たまになのかな。わからないですけど、多くて週1回ぐらいにとんでもないクエリが。
よくあるのは、タイムレンジをうまく書けてなくて全件スキャンしようとするようなクエリを投げられたりとかがけっこうあります。
AudienceOneのサービスでがっつりTreasureDataを使っているので、あんまり重いクエリ投げられるとAudienceOneの集計にめちゃくちゃ影響が出るんですね。なので、こういったクエリが投げられていないかというモニタリングも、実はAudienceOneの開発チームでやっています。
まぁこんな感じですね。GoogleAppsScriptでTreasureDataのAPI叩いて、いまだとだいたい30分以上ぐらい実行されているジョブを拾って、ReducerとMapperをどれぐらい使っているのかと、誰がこのクエリ投げているのかをモニタリングしています。社内ではTreasureData警察って言ってますけど。
すぐに問題のあるクエリであればkillしますし、僕の開発チームはTreasureData長く使っているので、へたくそなクエリを書いてたら「こういうふうに書いたほうがパフォーマンスがより良くなるよ」といって、社内のSQL力とかTreasureData力向上にも一応貢献してるようなかたちになっています。
Treasure Workflowは非常に強力だなと思っています。これが出たのはたぶんここ1〜2年ぐらいですよね。なので、それまではなにか実証実験をやろうとしても、けっこうがっつりプログラミング、がっつりコーディングというか、作り込まないとできてなかったものを、すぐに実証実験みたいなフェーズに持っていけるのはすごくいいかなと思っています。
いくつかデータベースのサービスの使い分けをお話ししましたけど、適材適所なところはあるのですが、運用コストとかを考えると、個人的には可能なかぎり、できるかぎりTreasureDataに寄せたいなと思っています。画面から参照するものは無理でしょうけど、集計の処理みたいなものは可能なかぎりTreasureDataに寄せたいなと思っています。
最後はネタなのでほうっておいてください。はい(笑)。
というところで、弊社はいろんなサービスを作っていて、エンジニアはもちろん、データサイエンティストとかプロダクトマネージャーを募集しているので、ご興味あればお声がけください。
以上となります。ご清聴ありがとうございました。
(会場拍手)