SQLの処理傾向が違う
柴田長氏(以下、柴田):整理すると、無名PL/SQLから多くのSELECT文が実行されていて、5秒前後で終わっているSELECT文のグループもあるし、60秒近くかかっているグループもある。処理時間の観点では2つに分かれています。関口裕士氏(以下、関口):そうですね、本番環境ではそのような状況ですね。次は問題がなかったテスト環境と比較してみたいですね。
柴田:試験環境、すなわち問題がなかった環境のAWRレポートを見てみましょう。(デモ画面を指して)SQL ordered by Readsのところですね。
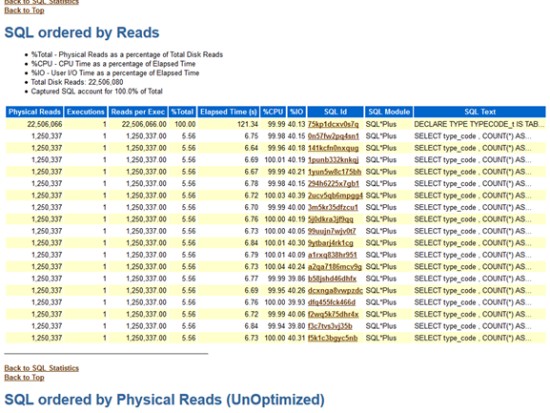
関口:通常であれば、本番環境のAWRレポートと試験環境のAWRレポートを横に並べて比較するのですが、比較するまでもないですね。試験環境のAWRレポートには処理時間が60秒あるSELECT文は1つもないですね。みんな1桁台で終わっている。
柴田:6秒台で終わっています。
関口:まずはそういう60秒かかっているSQLに問題がありそうだというところが見えるかなとは思います。
柴田:近づいてこられちゃいましたね。関口さん的にはこの60秒近くが……。
関口:怪しいとは思います。
柴田:そうですね。
関口:はい。ここは明らかに違う。
柴田:このあとどこらへんを見ていきます? これはわかりました。こういう傾向というか、そういう状況になっていると。
関口:見るとすると、この60秒かかっているSQLです。本番ですけれども、やはり違いを見たいので比較したいんですね。疑っているところは、実行計画が変わっている可能性です。
どれか1つのSQL IDに着目して、SQLの実行計画を見てみたい。
柴田:実行計画を見てみたいと。
関口:はい、実行計画を見て、比較したいです。
SQLの実行計画を出力する方法
柴田:SQLの実行計画をどう見ますか? どうやったら見れますかね? 津島さん、解説お願いします。最近いろいろな見方があります。
津島浩樹氏(以下、津島):そうですね。実行計画を出力するパターンとして、昔から使われている「EXPLAIN PLAN」と「SQLトレース」があると思います。EXPLAIN PLANは、実行せずに出力するので、正確性が少し欠ける場合があります。トレースは、あらかじめ出力しなさいと指定しておかないと出力しないものですので、どちらも再度実行しないと出力できないパターンが多いと思うんです。
再度実行してくださいといっても、なかなか実行できない場合もありますので、最近は共有メモリから直接的に出力できるものもあります。通常、SQLを実行しますと、しばらくの間共有プール上に実行計画が保管されますので、それを直接出せるようになっています。それを出すものが、リアルタイムSQL監視、もしくはDBMS_XPLANです。

ただし、共有プール上ですので、そこからなくなると出力できません。そのために、StatspackもしくはAWRのスナップショットにその情報を出力するようになっています。ですからAWRやStatspackのスナップショットを持っていれば、それから直接実行計画を出力できるようになっていますので、今回はAWRのほうでそれから出力していただければいいのかなと思います。
柴田:そうですね。いまどきの流行りは「共有プールから持って来い」という話ですね。

なんでこんな説明したかというと、テスト環境でのテストはすでに終わっているんですよ。で、テストが問題なかったのでデータベースもたぶんシャットダウンされている。シャットダウンだけでなくて、再構成されているかもしれない。だから共有プール上に問題なかったときの実行計画がないケースが多いと思うんですね。こういうときにこのAWRのSQLレポートを使ったらどうかということですね。
本番環境は、今まさに問題が起きているので、リアルタイムSQL監視からも見れますけどねというように、いろいろな状況に合わせて実行計画を確認すればいいかなと思います。
AWR SQLレポートから実行計画を確認
柴田:ということで、関口さん、(デモ画面を指して)SQL ID 45nd05pwnjcybのSQLについて、テスト環境と本番環境のAWR SQLレポートを用意しました。
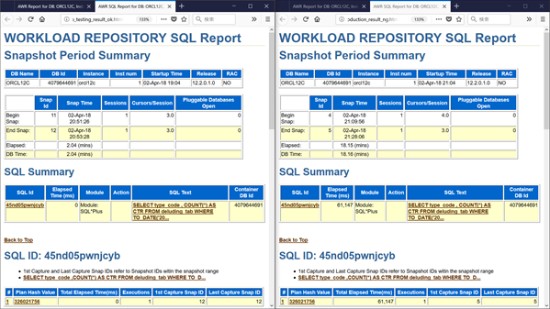
関口:Plan Hash Valueが見えているんですけど、(テスト環境と本番環境で)同じですよね?
柴田:Plan Hash、そうですね。もうバレちゃいました? ということは?
関口:(実行計画を見るまでもなく)実行計画は変わっていないなというところが、わかります。といっても、実行計画を見たいので、実行計画を出してもらえますか?
柴田:はい、出しますね。(デモ画面を指して)INDEX SKIP SCAN、本番環境のレポートです。
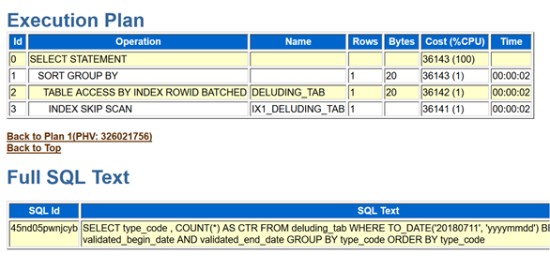
関口:本番のほうの待機イベントを思い出していただきたいんですけれども、インデックスアクセスを示すdb file sequential readが多発していました。実行計画でもインデックス使っていることが分かったので、対応はとれています。ただ……。
柴田:ただ?
関口:ただ、実行計画は変わっていない。
柴田:はい。実行計画は変わってないんですよ。
「Plan Statistics」からSQL実行時の統計値を確認する
柴田:これは難しいですね。実行計画が変わって性能が悪くなったことではなかったということですね。
関口:実行計画は変わってないんですけど、全部全体を見てみたいです。「Plan Statistics」という実行統計があるんですけれども。
柴田:さすが関口さん、鋭い!
関口:これ比較してみると、テストのほうが(全体的に統計値が)すごく少ないですね。
柴田:インデックスですからね。
関口:そうですね(笑)。
柴田:そもそもインデックスアクセスのときはこんな感じですよね。
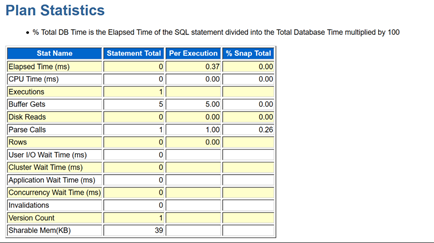
関口:本番のほうは?
柴田:こんな感じで。はい。
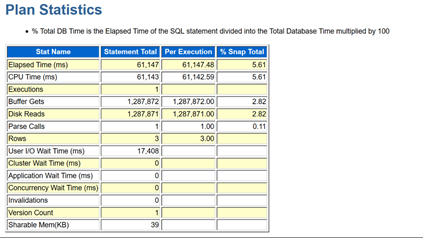
関口:「Buffer Gets」がなんかものすごく違うので。
柴田:やはりこのあたりですね。なので、実行計画だけ見てちゃダメですね。
関口:そうですよね。
柴田:これちなみに「Rows」が、ここに「1」とありますけど、なんですかね?
関口:AWRのRowsは、コストベース・オプティマイザが、オプティマイザ統計をもとにしてどれぐらいのレコードにヒットするかを見積もった時の値です。
柴田:コストベース・オプティマイザが1レコードしかないと見積もったんですね。
関口:でも実はものすごいことになっていたと。
柴田:これまずいですよね。
オプティマイザ統計情報の精度が低い?
関口:おそらくテスト環境は同じように「Rows」が「1」ですけれども、その狙いどおりいっているということでしょう。柴田:すなわち、本番環境では行数が1だと思ってSQLを実行してみたら、実際は行数が違っていたということ?
関口:おそらくそうですね。
渡部亮太氏(以下、渡部):いや、たぶん1行がすごく長いんです(笑)。
(一同笑)
柴田:現実的にはそれはないでしょう(笑)。あらためて整理すると、今回の事象は、実際に見積もった行数と、実際に実行したときの行数で差がありそうだといったところです。これの裏をとるには……。
関口:はい。EstimatedとActualの差を見たいですね。
柴田:見積はEstimatedで、実際はActual。行数だとEstimated RowsとActual Rows、そういう表現があるんですけれども。
関口:そうです。その差を見てみたいですよね。
柴田:その差を見てみたい。また整理してみますね。

テスト環境も本番環境もINDEX SKIP SCANですよ。Disk Readsの回数は0。実行時間は0ミリですね。だけど、本番環境は同じ実行計画なのに、Disk Reads回数が多くて、実行時間が長い。だからDisk Readsを「たくさん読んでるよね」という話だと思います。
津島:はい。今出たように、RowsはEstimated RowsとActual Rowsがあります。Estimated Rowsは、実行前にオプティマイザがオプティマイザ統計から見積もった行数です。Actual Rowsは、実行時に実際に処理した行数です。ですから、これが異なっているということはオプティマイザ統計の精度が低いということを意味します。

このActual Rowsなんですけど、リアルタイムSQL監視と「dbms_xplan.display_cursor」を使って実行計画を出力した場合でしか出せません。ですからAWRやStatspackから実行計画は出せますけれども、これ(Actual Rows)は出ないので注意してください。
柴田:つまりは、今、AWR SQLレポートには、ここ出ているのはEstimatedです。Actualじゃないということです。
リアルタイムSQL監視レポートを用意しました。といっても、みなさまお馴染みのHTMLじゃなくてテキストです。用意しています。関口さんどうですか? これでちょっと。
関口:やはり(テスト環境と同様に)INDEX SKIP SCANになっていますね。で、「Rows(Estim)」が見積もり行数ですね。1行、先ほどと同じです。

「Rows(Actual)」がありますが、そこを見ると「10M(メガ)」ですね。
柴田:はい。7桁違います。
関口:そうです。それぐらい違う。
柴田:ということは、先ほど津島さんの話で、「オプティマイザ統計情報の精度が低いんじゃない?」。
津島:ですので、それ(オプティマイザ統計情報)をどうやって取得したかは確認したほうがよいかもしれませんね。
オプティマイザ統計情報は問題ないかと思えるが…
柴田:オプティマイザ統計情報の収集方法。そろそろそんな感じで答えに近づいてきますけれども、私、ヒアリングしてきました。この感じで本番環境の(オプティマイザ)統計情報を取得していました。
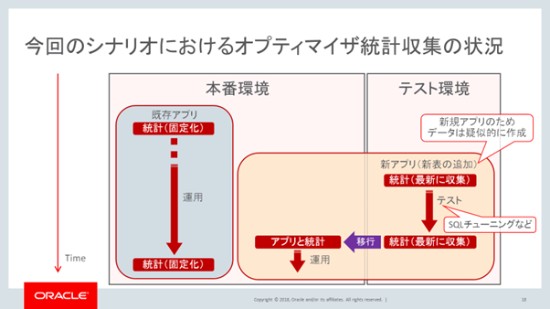
あまり実行計画変わってほしくないといった要望があるので、統計情報は固定化しています。本番環境、これは縦に時系列ですけれども、既存のアプリは統計情報を固定化して運用していますよ。
今回、新しいアプリケーション・機能を作るためにテスト環境を用意しました。新しい機能とアプリだったので、データは擬似的に作成しています。そのテストデータに対して統計情報を収集して、SQLのテスト、チューニングのテストをしました。
なので、実行計画も最適にしたつもりです。その実行計画を本番でも使いたかったので、SQLのアプリを本番に持っていくのと、オプティマイザ統計情報をコピーして本番で運用を開始したといったような運用をされているヒアリング結果となっています。
津島:ぜんぜん問題なさそうですよね。
柴田:Oracle ACEのみなさんどうですか?
渡部:いや、問題あります。
津島:そうですか(笑)。
柴田:問題あります?
渡部:問題あります。説明させていただきます。
整理すると、テスト環境では、まずデータからオプティマイザ統計を収集して、それをもとに実行計画を作って、もちろんこの実行計画をもとにデータに対してアクセスした、要するに実行したところで、なんか普通だなと思います。
確かにこれに問題ないのはわかるんですけど、ただ「本番環境は?」というところが、やはり気になるところはあります。

それぞれ見ていきたいんですけれども、まずデータ。これテスト環境と本番環境で違うのか・同じなのかというと、本来なら違うんですよね。あくまでもテスト環境で使っていたのは擬似的に作っているものです。もちろん本番環境では正しい本物のデータが使われているので、データが違う。
オプティマイザ統計をどうしていたかというと、テスト環境から移行したわけですよね。
柴田:はい。
渡部:そういう流れです。
本番環境でオプティマイザ統計情報を取らなかったことが原因か

渡部:その結果、実行計画が作られました。確かにテスト環境と本番環境、同じ実行計画が選ばれていたのですが……。
柴田:これは狙ったんですよね。
渡部:狙ったんでしょうね。ただ、これを実行するとなにが起きるのかというと、ぜんぜん予想とは違う行数にヒットしてしまう。そういうかたちになっている。それでやはり問題が、ここが問題のところで問題の現れかなと思いました。
さらに一歩踏み込むと、本番環境のデータとオプティマイザ統計の関係なんですけど、これがリンクしてなかったんですよね。
柴田:そうですよね。
渡部:なので、アプローチとしては、やはり本番データをもとにオプティマイザ統計を取りたい。
柴田:取ればいいんじゃないですかね。
渡部:うん、そうですよね。
柴田:ダメですか?
渡部:たぶんこれは推測になりますけど、あえて取らなかったんじゃないかなと思うんですよね。
柴田:もともと、統計情報を固定化して運用していたところがあると思うので、下手に統計情報を取得して実行計画が変わるというのを恐れていた。
渡部:そうですね。たいていの場合実行されるSQLはたくさんありますから、このSQLはいいにしても、ほかのSQLがダメになって性能が出なくなっちゃう可能性などを考えたんじゃないかなと思います。
コストベース・オプティマイザの動作を信じる
柴田:突然、実行計画が変わって性能が落ちるのがいやだから固定化しておきたいという運用のシステムは、みなさんがご経験あると思います。Oracle ACEの方々は、こんなケースをどんな方法で乗り切っていますか?
諸橋渉氏(以下、諸橋):私はそもそもこういうことを乗り切らなきゃいけない状況にしないのが、一番幸せかなと思います。
柴田:乗り切らなきゃいけない状況にしない。
諸橋:今のような、固定化してしまったことによっていろいろ問題が起こったときの、駆け込み寺のようなところにいたことがあります。でも、そんな痛い目にまったく遭っていない人がたくさんいると思ってます。
統計情報は取られる機会も増えているので、例えばデータを挿入したときや更新したときなど、デフォルトの状態で統計情報は好きなだけ自動で勝手に取られて、そこからコストベース・オプティマイザが動く動作を信じる。「信じる者は救われる」という。
(一同笑)
津島:信じる者。なにを信じる?
(一同笑)
諸橋:だから、統計情報が正しく取られている状態が常に続いていると信じる、という意味。
柴田:Oracleを信じる?
津島:すばらしいですね(笑)。
(一同笑)
諸橋:それは言いたくない。
(一同笑)
オプティマイザ統計情報を段階的に導入する
津島:1日に1回は自動的に統計情報を取られていますので、基本はそれで問題ないと思います。ですので、できればそういうふうに……。諸橋:もちろん大量に変動があることが、自動的にこれを取られるタイミング以外であるというのでしたら、それは手動で統計情報を取ってくださいというのが1つの答えになります。
そういうことがないというのであれば、取っておくことのほうが少ないかなと、今の私は判断しています。過去に痛い目にはたくさん遭っていますけど。
柴田:はい。ありがとうございます。じゃあ続きまして、渡部さんにいってみようかな。そろそろクロージングです。
渡部:そうですね。確かに統計情報はいわばグローバル変数みたいな扱いなので、いきなりがさっと変えるのというのは怖い。そちらもわかるところなんですね。そういったところは理解して、いろいろと機能があります。今回提案したいのは、統計情報の保留ですね。

これは統計情報を取るんですけど、それを使わないアプローチができるんですよね。使わない。
では、どういうときに使うのかというと、一番下の箇条書きに書いてありますけど、初期化パラメータの「OPTIMIZER_USE_PENDING_STATISTICS」というのを「TRUE」にすると。
これによって、テスト用のアプリケーションのセッションだけとか、ある特定のアプリケーションだけTRUEにすることで、こちらに関しては新しい統計を使える。残りのものに関しては古いものを使う段階的な導入ができるので、これがまずご提案したいところです。
柴田:新しい統計情報で作成された新しい実行計画が問題ないことがテストで終わったら、本番で使いはじめる。
渡部:そうですね。それが1つです。
柴田:1クッション置く。
渡部:はい。
SQL Plan Managementを使用するのも方策
柴田:関口さんはどうですか?
関口:そうですね。私はSQLヒント大好きなので、本当はがっちりヒントでチューニングしたい。
(一同笑)
もう少し楽なやり方でいくと、オプティマイザ統計が変更されたときの影響を少なくするという意味だと、例えばSPMを使っていくのも1つの手だとは思います。

柴田:SQL Plan Managementですね。
関口:そうです。
柴田:なにがいいんでしたっけ?
関口:これはオプティマイザ統計が変わったとしても直接影響を受けなくて、SPMで登録した実行計画を選んでくれる。
柴田:そうですね。承認した実行計画だけ使う機能ですね。
関口:そうですね。
柴田:こちらも1つあるのかなと思います。津島さん、ちょっとまとめていただけますか?
津島:はい。いろいろなアイデアを出していただいて、どれも正しいと思います。なにを重視するかで使い分けていただければいいのかなと思います。
ここに表としてまとめてみましたけど、観点としてこの3つだと思います。要は、SQLの性能はどれが一番速くなるのか、運用の負荷はどれぐらいあるのか、性能劣化のリスクはどれぐらいあるのかというところで、どれを重視したいかだと思います。

固定化運用は、今回問題になった運用で、当然ながら精度の低いオプティマイザ統計を使いますので、性能的にはそんなに出ない場合もあります。ただし、性能劣化のリスクは少ないと言えるので、これをやはり重視したいというのであれば固定化もありでしょう。
それから保留統計は、先ほど言いましたように、1回テストするので、性能劣化のリスクを避けられるでしょう。ただし、1回テストするのでそれなりに運用負荷は発生します。 SPMもまた最適な実行計画しか使いませんので、いいです。ただし、これがいいのは、自動的に行えるということで、運用の負荷がすごく少ないんですよね。
自動化を「Oracleに任せる」
津島:最後に「Oracleに任せる」というのは、やはり最適なオプティマイザ統計を常に収集しますので、最適なSQLの性能になると思います。
ただし、性能劣化する可能性はゼロじゃないですが、12.2や18など、だんだんバージョンアップすることによって補正機能がだんだん増えてきていますので、そこのリスクはだいぶ少なくなってきていると思います。
今後は運用的にも大変じゃない、自動化を「Oracleに任せる」というのも使っていただければいいのかなとは思っています。
柴田:いろいろOracle ACEの方々からアイデアいただきましたし、津島博士にもまとめていただいたと思うんですけれども、この最後の「Oracleに任せる」。
これが本日、全体を通じて、イベントを通じてお話ししてきた、Autonomouns Database Cloud。「Oracleに任せます」という、ユーザーのみなさまの期待にお応え続けるコンセプトだと思っていますので、ぜひご期待してご利用いただければと思っています。といった無理なクロージングで(笑)。
(一同笑)
最後のセッションを締めさせていただきたいと思います。
今回の問題のキモは、テストデータが本番データと大きく乖離していたといったところですね。なので、本番で統計情報を取り直せば速くなる可能性がある。というオチでした。津島さん、なにかありますか?
津島:よくあるパターンだと思いますよね。新規アプリは、やはりデータがないのでテストをするときはけっこう難しいですよね。当然、疑似データを作らないといけないので、本番データと一緒になることはあまりないので、絶対起きると思います。それに対してどう対処すればいいかという今回のこのセッションをヒントとして使っていただければいいかなと思いますので、どうもありがとうございました。
柴田:ぜひよろしくお願いいたします。以上となります。はい、お返しします。ありがとうございました。
(会場拍手)