パフォーマンス・チューニングで5名が登壇
柴田長氏(以下、柴田):最後のセッションとなります。ぜひお付き合いください。
昨年も一番好評だったので、もう1回やってみたいと思います。「エキスパートはどう考えるのか? 体感! パフォーマンスチューニングⅡ」ということで、Oracle ACEの3名の方に代表してご登場いただきました。

まず自己紹介です。Japan Oracle User Groupから「Mac De Oracle」の中の人、関口さん。よろしくお願いいたします。お隣が、日本ヒューレット・パッカード株式会社の諸橋さん。
諸橋渉氏(以下、諸橋):よろしくお願いします。

柴田:よろしくお願いします。
(会場拍手)
柴田:最後は、株式会社コーソルの渡部さんですね。

渡部亮太氏(以下、渡部):よろしくお願いします。
(会場拍手)
柴田:私のお隣にいるのが、津島さん。はい、よろしくお願いします。

津島浩樹氏(以下、津島):よろしくお願いします。
(会場拍手)
柴田:私のほうで、最後のセッションの司会を務めさせていただきます。日本オラクルの柴田です。よろしくお願いします。
(会場拍手)
柴田:今日は時間がないので、サクッといきましょうか。いいですか? 準備できていますか? では、津島博士、本日の課題をよろしくお願いします。本日の課題は1個です。
今回の課題は? 最初の着目点はなにか

津島:今回もよくある問題を用意させていただきました。ですので、ぜひみなさんも一緒に考えてほしいなと思っています。どんな内容かと申しますと、A社では基幹業務としてBシステムを運用しています。これまでは問題なく動作していました。ところが最近になって、ある業務だけが非常に遅くなってしまい、他にも影響している状態であるため、早急に改善してほしいということです。
もう少し状況を調べてみましたら、変化点としては、今週から新規の機能を導入したということです。ちなみに、その機能はテスト環境では問題なく動いていたそうです。このあたりが大事ですね。
これくらいしか情報が聞けてないので、この情報から何が問題かをみなさんに考えてほしいということで、お願いします。
柴田:小学校の国語の問題じゃないですが、この文章だけでOracle ACEのエキスパートのみなさんから、過去の経験からの「原因はこんなことが起きてんじゃないの」「こういった観点で分析が必要じゃないの」のような意見を、コメントいただこうと思います。
まず渡部さん、お願いできますでしょうか。
渡部:正直言って、これで原因の特定は無理ですね(笑)。原因の特定は難しいんですけれども、気になるキーワードはあります。「新機能のリリース」と、「テスト環境で問題なかった」というポイントがあるので、調査の糸口としてはやはり本番環境とテスト環境の比較を、まずはすべきなのかなと。
ハードウェア性能やデータの量、初期化パラメータが本当に同じになっているのかは、スタート地点として押さえておきたいところかなと思います。
柴田:そうですね。本番環境とテスト環境の比較といったところが主なところで、繰り返しますけれども、ハードウェアの環境、データの量と初期化パラメータなどを本番とテスト環境で違いがないのか、といった観点から調べていくんですね。環境の違いによって、問題が起きているのかもしれない。
渡部:といっても、今の段階ではぜんぜん、わかんないですけどね。
柴田:ありがとうございました。続いては関口さん。
どの観点で比較できるか洗い出す
関口裕士氏(以下、関口):私はよくお医者さんの診断になぞらえてパフォーマンス・チューニングを考えるんですが、この問題では、問診結果に相当する情報がかなり少ないので正直に困ります。
ただ、想像というか、可能性の話として渡部さんの予想である、環境の違いに起因する可能性は言えるだろうと思っています。
ただ、渡部さんもおっしゃったように本番環境とテスト環境の比較するのは大切だと思うんです。例えば、お医者さんも、去年と今年のレントゲン写真を比較して差分がないかを見えるように、よく使うアプローチですよね。

ほかには、例えば、新規のアプリケーションリリースなので、その影響で例えばキャッシュ・ヒット率が低下したことや、既存の処理と競合してI/O性能が落ちることなどの可能性もあると思います。
柴田:関口さんの観点だと、新規のアプリ、新規の機能をリリースした前と後で、どう変わってしまったのかから切り込んでいく。なるほど、ありがとうございます。諸橋さん、最後お願いします。最後が一番難しいですよ。
諸橋:難しいですよね。
柴田:出つくしているんで(笑)。
諸橋:そもそもデータベースが本当に遅かったのか?と考える必要もあるかなと。
(会場笑)
柴田:そうですね。Oracle Database Connectですけど、そういうオチもあるかもしれないですね(笑)。
(会場笑)
諸橋:そこから切り込みたいかなと思います。

柴田:切り込みたい。とはいえ、何があってもけっこうデータベースが疑われますよね。どうすればいいんですかね? 「データベースじゃないよ」と突き返したいんですけど、渡部さんどうします? 「データベースじゃないよ」と結局証明しないといけないですよね。どんな情報やエビデンスがあれば突き返せるのでしょうか?
渡部:そこがOracle Databaseのいいところですよね。診断情報などがぜんぜんない状況で突き返すと、水掛け論みたいな感じになりますが、Oracle Databaseは診断情報がすごく充実しているので、本当に根拠を持って突き返せます。
まずは本番環境とテスト環境のAWRレポートを比較
渡部:データベースを全体で包括的に見ていく診断機能というと、みなさんご存知だと思いますが、AWRレポート、Statspackレポートを使うことになると思います。今回の場合は、本番環境とテスト環境のAWRレポートを見たいです。
柴田:この文章だけじゃ無理ですよね。
渡部:そうですね。
柴田:想像して、結局、実際に数字を見る、比較する。今ご紹介いただいたAWRレポート、Statspackレポートなどを見なきゃいけないので、私が仕入れてきました。何と何を比較したいですか?
渡部:そうですね。本番環境とテスト環境ですね。
柴田:本番環境とテスト環境。問題なく動いていたテスト環境の時のAWRと、問題が今起きてしまっている本番環境のAWRレポート。この2枚ですね。(デモ画面を指して)いかがですか?
「そもそもデータベースは問題ないんじゃないか?」と疑っている諸橋さん、見てもらっていいですか?
諸橋:これはどちらがテスト環境ですか?
柴田:これは、みなさんから見て、左側がテスト環境、問題なかった環境です。右側が本番環境、問題が起きている環境ということですね。
見やすいようにAWRレポートを大きく表示しますかね? (デモ画面を指して)まずは左側、テスト環境です。諸橋さん、お願いします。

諸橋: テスト環境のレポートだけだと(分析するのが)かなり厳しいのでテスト環境と本番環境のレポートを並べて表示してほしいです(笑)。
柴田:失礼しました。並べて表示しました。
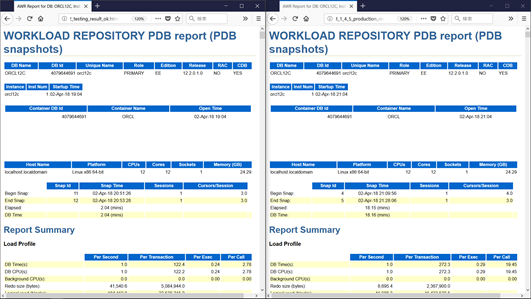
諸橋:パッと見で違うところは、目につきませんね。どちらの環境もEnterprise Editionで。12.2.0.1で。RACじゃなくて。CDBです。
柴田: そうなんです。12cなんです。本当は18cで検証して問題をつくりたかったんですけど、準備が間に合いませんでした……(笑)。
諸橋:プラットフォームもLinux x86 64bitです。CPUがコア12個、1ソケットで、メモリが24.29ギガバイト、小さいなぁ……。
(会場笑)
柴田:そうですね、小さいですね。
諸橋: これらはすべてテスト環境と本番環境と同じで、とくに差異はありませんね。
柴田:はい、ということで、渡部さん、ハードウェアは同じでした。
諸橋: テスト環境のAWRレポートの期間が2分…。あれ? ここ、読んじゃいけないのかな?
(会場笑)
柴田:読まないでください。バレましたか(笑)。このAWRレポートは、2分間の負荷状況を表しているAWRレポートです。
諸橋:本番環境のAWRレポートの期間は18分。期間が違うAWRレポートは、読むのがつらくないですか?(笑)。
(会場笑)
柴田:つらいですよね(笑)。
期間が異なるAWRレポートをどうやって見たらいいのか
柴田: Oracle ACEの3名なので、難易度高めのAWRレポートを用意したんですけど(笑)。津島さん、レポートの期間が違うAWRをどうやって見たらいいのか教えてください。
津島: AWRを比較するときは、同じ期間のものを比較するのが簡単です。特に理由がない限り、同じ期間のAWRレポートを比較するようにしてください。
このように期間が違うAWRレポートを比較する場合、回数や所要時間などの絶対値は単純に比較してはいけません。処理する量が違うので、それらを比較しても意味がないです。
比較していいものは比率、それから例えば1秒間あたりの回数とか、1回あたりの時間です。それから平均値やランキングなど、そういう傾向を示すものは比較してよいです。期間が違うAWRレポートを比較する場合はこれらにフォーカスして比較するようにしてください。

柴田:みなさんぜひ参考にしてみてください。時間が違うときには、絶対値は絶対に比較しない。平均や単位時間の回数などを使っていくしかないです。ということで、諸橋さん、レポートの比較に戻りましょうか。
I/O処理量をテスト環境と本番環境で比較
諸橋:次のセクションにいきましょう。Load Profile。

柴田:Load Profile。大きく表示しますね。(デモ画面を指して)左側はテスト。問題ないほう。本番が問題あるほう。異常が本番で起きている。
諸橋:まず、テストのほうに着目したいです。
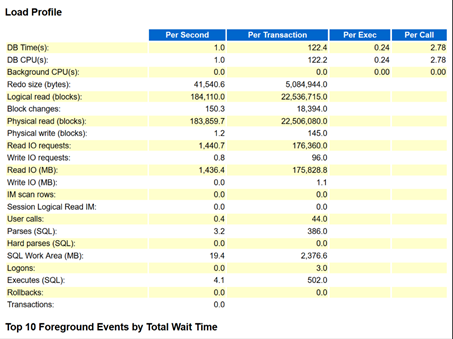
柴田:はい、テストのほうですね。とくに数字が大きいのは……。
諸橋:Logical readですね。
柴田:そうですね。
諸橋:テストの環境はLogical readが本番環境よりも大きい。
柴田:そうですね。18万回ぐらいですね。
諸橋:Physical readも同じぐらいですね。
柴田:Logical readが18万ブロック。Physical readも18万ブロックですね。これがテストだと非常に少ない。
諸橋:なのに、Read IOだと……。
柴田:Read IO requestが本番環境のほうが多くなっているが、Logical readの数が少なくなっている。Physical readも少なくなっている。1秒間あたりなので、さきほどの津島さんの話だと、比較していい話ですよね。だけど……。
諸橋:Read IO Requestは、テスト環境が1,400。Read IOも1秒間あたり約1,400。本番環境はrequestsが多くて、MBは小さい。
柴田:悩みますねぇ。ヒントになりそうなところですね。今みなさん気づいているかな。少し難しいですね。ということで、難しいから次のセクションに行きましょうか。
諸橋:そうですね。
Top 10 Foreground Eventsを比較
諸橋:Top 10 Foreground Eventsを見てみましょう。Total Wait Timeの大きい順に並べて表示されているので、先ほどの説明の通り、AWRレポートの取得期間が違っても、順番を見ることには意味があるんですね。ですから、順番はざっと見ておきましょう。
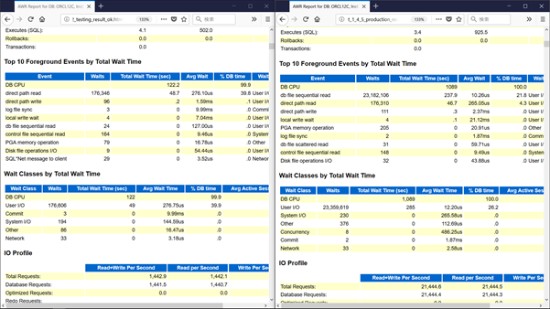
柴田:この順番を見ていきますね。
諸橋:DB CPU、direct path read、direct path writeまでで、%DB timeの0.1パーセント以上は? 0.1パーセント以上はその上しかない。本番のここになりますね。
本番は、DB CPU、db file sequential read、direct path readの順番です。そこまでの3つで0.1パーセントよりも値の大きいパーセンテージを占めていることになっています。明確に傾向が違うと思います。
もう1つ、同じWait Eventが出ているので、例えばdb file sequential read。
柴田:db file sequential read。
諸橋:こちらのAvg Waitは127μs(マイクロ秒)ですよね。
柴田:すごいですよね。そうですね。μ(マイクロ)ですね。
諸橋:本番のほうは、db file sequential readのAvg Waitが10μs。だいぶ違いますよね。
柴田:違いますが、左が問題ないほうです。右は問題が発生するケース。問題が発生しているほうが速い。
諸橋:不思議な感じですね(笑)。
(一同笑)
渡部:そもそも小さいですもんね。
柴田:小さいですね。μ(マイクロ)の単位ですから、相当速いですね。
諸橋:相当速いのであまり比較対象にならない。誤差の範囲と考えてもいいのかなと。
柴田:127μも10μも。
諸橋:DBもdirect path readのほうのAvg Waitもだいたい同じですよね。276μsと265μsで、だいたい一緒です。
平均I/Oのレスポンスタイムを確認
柴田:なにか大きな特徴の違いはありますか。
諸橋:そうですね。db file sequential read待機イベントが上位に上がってきているところが怪しいかな。たいてい、ハードウェアに問題があるとすればストレージなんですが、今回はdirect path readのところで270μ秒ぐらいなので、とくに問題はなさそう。
柴田:平均I/Oの時間もレイテンシーというかレスポンスタイムが、direct path readだとAvg Waitが275μsとか265μsなどで、大きくしてないですけれども、応答差がないからハードウェアに、ストレージ側に問題はないのかなという話ですよね。
次に特徴的なのは、db file sequential read、この待機イベントの回数が、2番目に多いということですね。
これどうですか? DB側に問題がありそうですか? そもそもデータベースに問題がないんじゃないかと言われてましたが、もう少し深掘りが必要ですよね。
諸橋:はい。ほかに問題がなく、データベースが問題という可能性が高い感じがします。
柴田:そうですね。まだ分析を続けなきゃいけない雰囲気がありそうですよね。みなさん、db file sequential readがたぶん肝っぽいですよね。db file sequential read待機イベントはなんだったのか、お時間ないのでサクッとおさらいしますよ。

これは前回のこのパフォーマンス・チューニングのセッションの中でご紹介させていただいたんですけれども、「db fileをsequentialに読むよ」みたいな待機イベントなので、一気にデータをフルスキャンで読むみたいなイメージを持たれがちですけれども、そうじゃないと覚えてくださいね。
なぜsequentialなのかというと、索引アクセスだからです。「SELECT * FROM emp WHERE ename = ‘Stanly’」というSELECT文を投げた場合は、enameに貼られている索引を辿っていって、最終的に表のデータ、1ブロックにアクセスする、テーブルにアクセスするというかたちです。
その場合に、索引のルートブロックを辿って、次のブランチブロックを辿って、次のリーフブロックを辿って、ようやく表のブロックに、レコードが格納されているブロックに辿り着く。
つまり、ブロックを順番に読むんですね。順番に読む際にディスクからも順番に1ブロックずつ読んでいくわけですね。なので、「db fileを順番に1ブロックずつ読むよ」という待機イベントになりますね。もちろんキャッシュに乗っていればこの待機イベントは発生しないわけですね。
SQL Statisticsから問題を特定できる?
柴田:ということで、今回は本番環境で問題が起きています。そして、db file sequential read待機イベントが非常に多くなっていた。この待機イベントが索引アクセスのときに発生すると覚えていれば、索引アクセスしている処理がいると自然と理解できる。
では、db file sequential read、もう少し深掘りが必要なので、関口さん、次どこを見ていきましょうか? SQLチューニングの鬼の関口さん。
関口:なにかしらのSQLがこのdb file sequential readを引き起こしているんだろうと思われるので、まずは本番環境のAWRレポートのSQL Statisticsというセクションを見ていきたいですね。
柴田:本番で、問題が起きているほうで「SQL Statistics」ですね。
関口:そうですね。SQL Statisticsにいろいろなサブセクションがあるんですけれども、今回とくに目立っているのがdb file sequential read。物理読み込みなんですよね!
なので、SQL ordered by Readsを見てみたい。
その下にすごく似たようなもの(注:SQL ordered by Physical Reads (UnOptimized))があるんですけれども、これは物理読み込みの中に占めるフラッシュ・キャッシュの割合なので、今回それを見る必要はないです。

柴田:SQL ordered by Readsを見てみましょう。どうでしょうか?
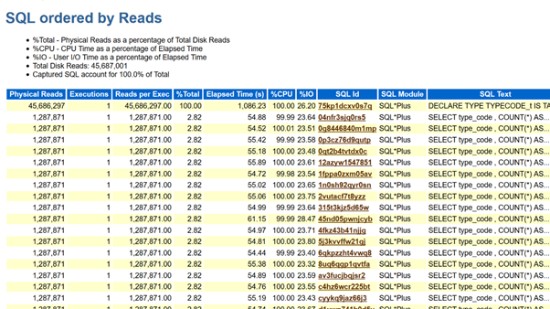
関口:このセクションは、物理読み込みの多い順にSQLが並んでいるので、先頭のところをまず見ます。先頭のSQLはDECLAREから始まっているのでたぶん無名PL/SQLですね。
柴田:さすが、読むのが速いですね。聞いている方のために解説いれていいですか?
関口:はい。
PL/SQLを読んでみると…?
柴田:一番目のSQLが物理読み込みが一番大きいSQLなので、まずはこいつが怪しいですよね。原因になっているんじゃないか。「そのSELECT文なんなの?」を見ようとして、関口さんはここ(SQL ordered by Reads)を見たわけですね。関口:SELECT文かと思いきや、いきなりDECLAREとあった。ですから無名PL/SQLブロックですね。ただ、ここの表示だけだと無名PL/SQLブロックの全体がわからないので……SQL IDのリンクをクリックしてもらっていいですか。
(柴田氏、デモ画面でSQL IDのリンクをクリック)

無名PL/SQLブロックの全体を見るとなんだかSELECT文を発行しているようですね。たしかに先ほどのordered by ReadsにSELECT文がいくつかあったんですが、この無名PL/SQLブロックとの関連性はまだよくわからない。
柴田:関連性はありそうですよ。FORループのなかでEXECUTE IMMEDIATEがあって、ここでSELECT文を実行しているように見えます。
関口:ですよね。SELECT文の一部をなにかで置き換えているだけですね。
諸橋:なにかというか、日付ですか?
関口:日付ですね。
柴田:さすが諸橋さん、見極めましたか。まいりました。
関口:そうですね。日付だけが違うんですが。
柴田:日付を少し変えて、ループしてました。
少しわかりづらいと思うので、スライドを使って説明しますね。無名PL/SQLで今回はFORループで多くのSELECT文を実行しています。
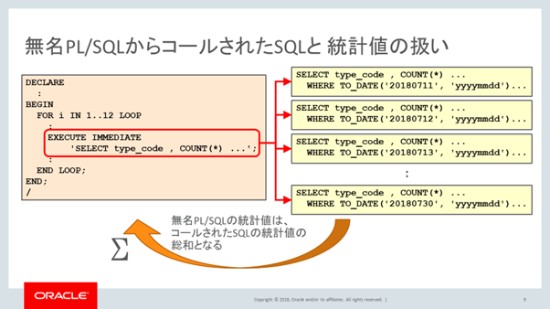
諸橋さんに指摘していただいたように、日付を変えて実行しています。こんな感じですね。なので、津島さん、こんな感じですよね。
良かったときと悪かったときを比較
津島:PL/SQLの中でSQLを実行すると、PL/SQLから実行されたSQLがSQL統計に表示されるのはもちろん、実行元のPL/SQLもSQL統計に表示される点に注意してください。
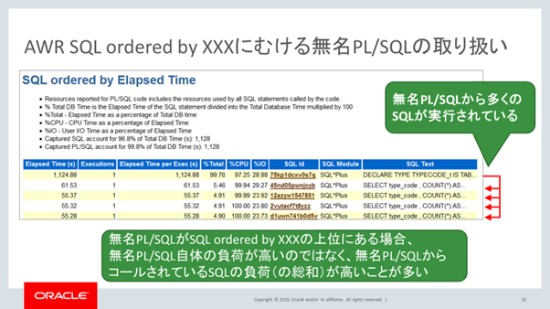
柴田:とすると、実行元のPL/SQLと、PL/SQLから実行されたSQLで表示が重複するということですか?
津島:はい。その通りです。
柴田:なるほど、これは知っておくといいと思います。
柴田:ということで、SQL ordered by Readsサブセクションに戻りますね。
関口:これ(SQL ordered by Readsサブセクション)の全体が見れないんですかね。下のほうとか。
柴田:待ってくださいね。
関口:ああ、けっこうSQLがリストアップされてますね。
柴田: SQL ordered by Readsの全体をざっと見た時の違いは……?
関口:本番環境では、SQLで60秒ぐらいかかっているのがちょい出ていますね。
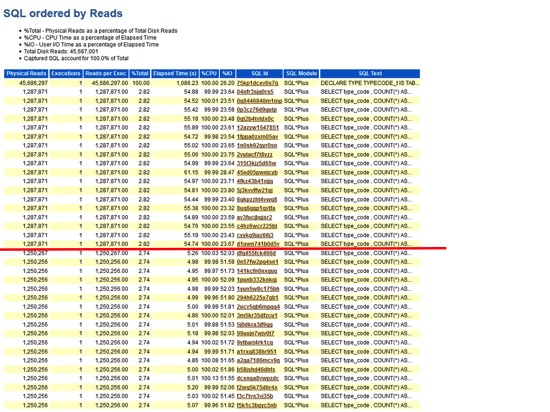
柴田:そうですね。SELECT type codeから始まるSELECT文が並んでいますね。全部無名PL/SQLから発行されているSQLですね。
関口:上位SQL文は、終わるのに60秒ぐらいかかっています。
柴田:さすがですね。60秒はどこ見るんですか?
関口:Elapsed Timeで見えます。厳密には、Elapsed Timeは、同じSQLを複数実行したときの平均所要時間なのですが、今回はExecutions(SQLの実行回数)が1回なので、平均=実際の所要時間になります。
柴田:そうですね。まとめると、所要時間を確認するには、Elapsed Timeを見るということですね。
関口:このような、無名PL/SQLから発行されているSQLに遅いものと早いものがあるという傾向をふまえながら、冒頭でも言いましたけれども、良かったときと悪かったときの違いに着目していきます。