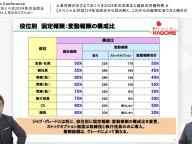
ゲームにおけるAIの進化
近年は人間よりも優秀なゲームやコンピューターが様々に出回っています。チェス、ジェパディ、囲碁などがあるでしょう。人工知能はAIとも呼ばれ、それは通常では人間の脳で解決されるはずの問題を解くために開発されたコンピューターシステムのことを言います。最新機器にはどのようなものがあるでしょうか?
AIはポーカーで人間に勝つのに強くなってきました。私はステファン・チンと申します。私のことをSciShowクイズショーで見たことがあるかもしれませんね。今日はここで、人工知能がどのように世界を牛耳っているのかについてお話しいたしましょう。
1月、「Libratus」という名前の人工知能がポーカーの約12万回の試合を終えて、結果4人の人間のプロプレーヤーに勝利しました。そして昨日発行された「Journal Science」誌の中の論文によると、異なる研究グループが「Deep Stack」という名前の人工知能は約4万5千回の試合の結果、11人のプロプレーヤーのうちの10人に勝利したというのです。
これら両方の人工知能は「Texas Hold’em」というポーカーゲームをしました。このゲームでは、各プレーヤーが、自分だけが見ることを許されている、面を伏せた2枚のカードを受け取ります。そして、皆が見ることのできるカードが5枚表面を向いて置いてあり、賭けは3ラウンド行われます。

今まで人工知能が勝利してきたゲームは、戦略的ゲームである「囲碁」のような、「完全情報型ゲーム」そしてして知られている、つまり、すべてのプレーヤーがそのゲームに関して同じ情報を持っているタイプのものでした。例えば、チェスや碁では、両方のプレーヤーがボード状のすべての駒を見ることができます。ですから両人が同じ情報を元に決定をすることになるのです。

しかし、「Texas Hold’em」は「不完全情報型ゲーム」です。なぜならプレーヤーはお互いの伏せたカードを見ることはできませんので、みんなが同じ情報を持っているわけではないからです。こうなるともっと複雑になってきます。なぜなら他のプレーヤーの手持ちのカードについて予想をしなければならなくなるからです。
例えばあなたの対戦相手が掛けます。つまりはその人がいいカードを持っているからなのでしょうか、それともあなたが騙していると見越して、相手も騙しにかかっているのでしょうか。もしかしたら前のラウンドであなたは相手が騙していると掛けたが故に、今度は相手が、あなたの方が騙しにかかっていると思っているのでしょうか。そのような脳を混乱させるような質問は、不完全情報型ゲームの中では常に生じるものです。
2つの人工知能が別のアプローチ
そこでこの新しい2つの人工知能はそれぞれ異なる技術を用いて、最もそうであろうとされる答えを導き出したのです。両方とも、各試合1人と対戦しました。これは人工知能には有利になります。なぜならプレーヤーが増えるにつれてゲームの発展する方向の可能性が広がってしまうからです。
しかし、両ケースともリミットなし版の「Texas Hold’em」を行いました。これはプレーヤーが好きなだけ掛けられるというゲームです。それによりゲームはより難しくなります。なぜなら自分が好きなだけ掛けられるなら、各ラウンドの結果が後のラウンドでの掛け方に影響を与えるので、起こりうる結果が多様になってしまうのです。細かく言うと、各試合において10の160乗通りの結果が出るのです。つまり、1の後に160個の0がつくと言うことです。
この数は非常に大きいですから、一番強力なコンピューターですら、すべての可能性を計算できるわけがありません。「Libratus」人工知能は1月に4人の相手に勝利しました。研究者たちはまず実際に自分に対戦する形で1兆回ゲームをさせました。それからその試合を元に学習したものをプログラミングし、残りの試合がどうなるかに応じて、異なる状況において最善の戦略を組むことができるようにしたのです。
その後、20日間にも及ぶ大きな試合において、4人のプレーヤーと「Libratus」を対戦させました。初めは、人間のプレーヤーが「Libratus」の試合方法の弱点を見つけることができたため、初めの6日間ほどはひどく負けることはありませんでした。
しかし、研究者たちは人工知能が人間の対戦相手との試合から学習するように設計していたのです。それで人工知能は毎晩、次の日の試合に備えて戦略を精錬しました。それで7日目くらいで、人工知能がさらに大きな差で人間に勝利していくようになったのです。トーナメントの終わる頃には、120万ドルほど勝利しました。

それとは対照的に「DeepStack」人工知能の研究をしていた科学者たちはそれが神経回路網を使うよう設計しました。「神経回路網」には1つの問題を処理するのに何層にもなったプロセッサが共同で働くことが必要になります。その各層が、他の層が計算した結果を利用するのです。これは人間の脳が働く様を模して設計されたもので、世界でも最先端の人工知能の中で用いられています。
「Libratus」と同様に「Deep Stack」もランダムに試合をすることにより学習しましたが、「Deep Stack」は約1,100万回のゲームを見たにすぎませんでした。しかしこの人工知能は戦略を決める前に1つの動きが残りのゲームにどう作用するのかを考慮するようにはデザインされていませんでした。
その代わり、異なる決定が次の数回の動きにどのように影響を与えるのかを見て、学習したことを元に次の数回の動きで勝利にいかに近づけるのかを計算したのです。ですから「Deep Stack」は、試合のすべてを予想する代わりに、次の試合の一部分がどうなるかを予想したのです。研究者がこの人工知能と11人のプロに「Texas Hold’em」のゲームで対戦させると、何千もの試合において10人に完全勝利しました。
ですから「Libratus」と「Deep Stack」は全く異なる設計をされていたのです。しかし、どちらの人工知能も複雑な不完全情報型ゲームをマスターできたのです。そしてここにきて、コンピューターが人間より勝る分野がもう1つあります。しかもこれは広範囲に及ぶ大きな進歩につながる大きなステップです。
私たちは現実世界において、「Texas Hold’em」のように、情報が欠如している場合においても決定をしなければならない状況によく直面します。この2つの人工知能の成功はつまり、そのような状況下において人間よりも上手に物事を分析することのできるシステムを作り上げることにつながると言うわけです。例えば一つの病の治療法に関して決定を下す時、それがあれば大きな助けとなります。それにこれらの人工知能は株取引や外交手段においても有効に活用できるでしょう。

しかし2つ確実に言えることは、将来私たちは素晴らしい人工知能ポーカープレイヤーを生み出すことができると言うことです。私はたくさんのロボットを歓迎します。