原ノ味フォントの作成者
細田真道氏(以下、細田):細田です。ふだんはNTTグループのどこかでDXな仕事をしていますが、今日はぜんぜん仕事とは関係なく、個人的にやっているオープンソースなどの話をしたいと思います。よろしくお願いします。
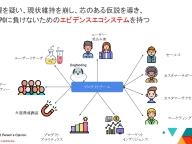
簡単に自己紹介をします。楽譜を作成するプログラム「LilyPond」のコミッターと、GNUの公式文書フォーマット「Texinfo」のコミッターをしています。あとで話しますが、「原ノ味フォント」を作っていて、すごく似たような名前で「原ノ町」という駅がありますが、原ノ味フォントとは関係ありません。
あとはLilyPond、楽譜のソフトを作っているときに、OSS関係の賞を受賞したことがあります。こんな感じのことをしています。

PDFをコピペすると文字化けしてしまうのをどうにかしよう
では本題に入ります。はじめにということで、PDFはいろいろあると思いますが、データ分析したいなと思ったとき、お客さんからもらったデータがPDFしかない場合。テキストを抽出して分析すると思いますが、文字化けしちゃいました、みたいなことがあると思います。
あとはPDFを普通に作って配るとか。あるいは、クラウドやサーバーサイドでPDFの帳票を生成してお客さんに提供するシステムがけっこうあると思いますが、コピペで文字化けしちゃうとか、あとはコピペできないとかがあると思います。こういうのをなんとかしようというのが、今日の話の内容になります。

化けるPDF、化けないPDF
こんな感じの目次でお話ししたいと思います。どんな文字化けが起きるのかいろいろあると思いますが、今回対象にしている化ける文字は「見」「高」「長」「玉」など、比較的簡単な漢字です。では実際になにが起きるのかというと、PDFからテキストをコピペすると、すごく似たような別の字に化けてしまうことが起きます。

例えば、住所を集計しようとすると長野の「長」が化けちゃうとか、埼玉の「玉」という字が化けちゃって、ぜんぜん集計がうまくいきませんとか。文字が化けているからではありますが、テキスト検索をしようと思って「長野」と入れて検索するとぜんぜんヒットしないけど、でも長野はいっぱい入っているみたいな。そんなことがあるかと思います。
これは、化けるPDFと化けないPDFがあります。化けるPDFはけっこうたくさん出回っているので、困った経験のある方はなかなかいるんじゃないかと思います。この資料はPDFですが、これは化けないです。対策済みです。

化けるPDFを作ってみる
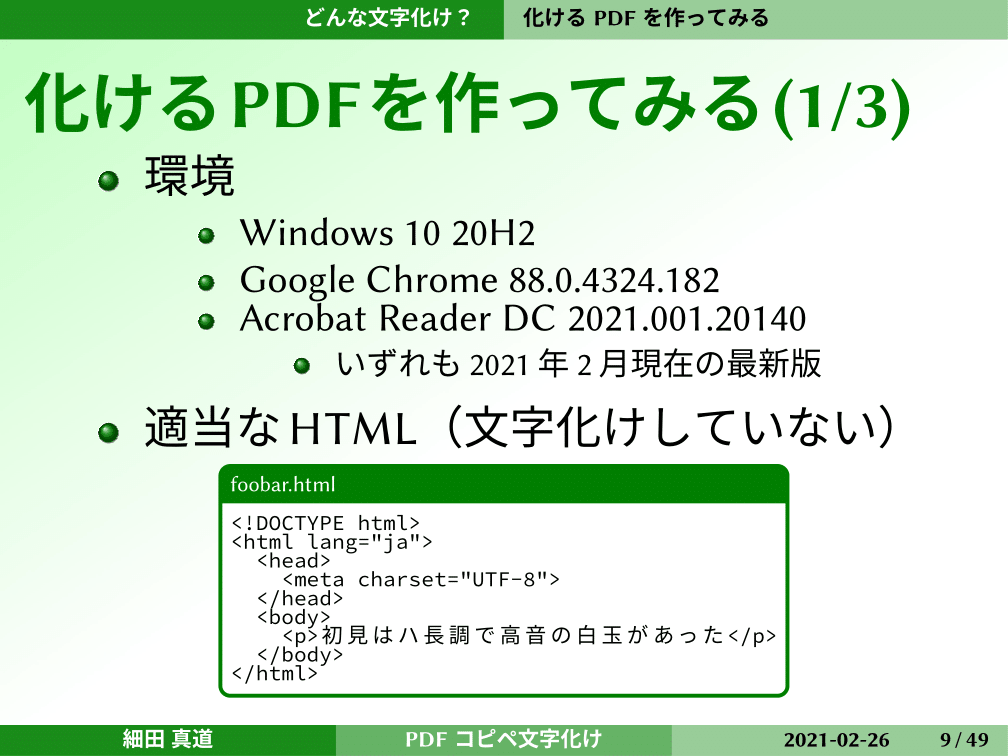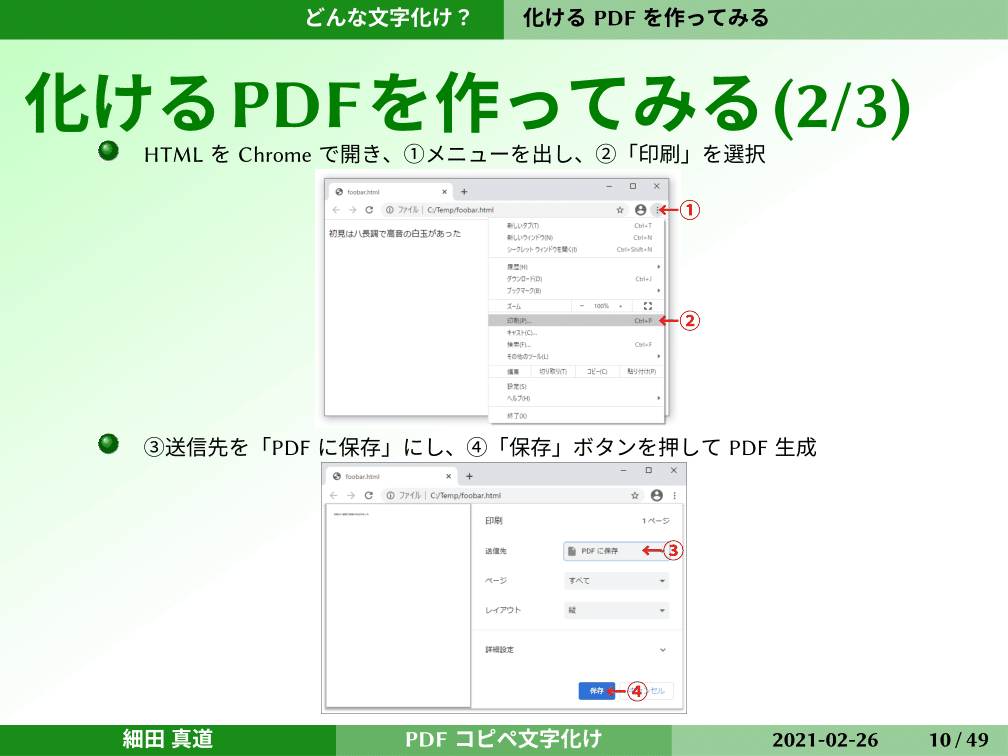
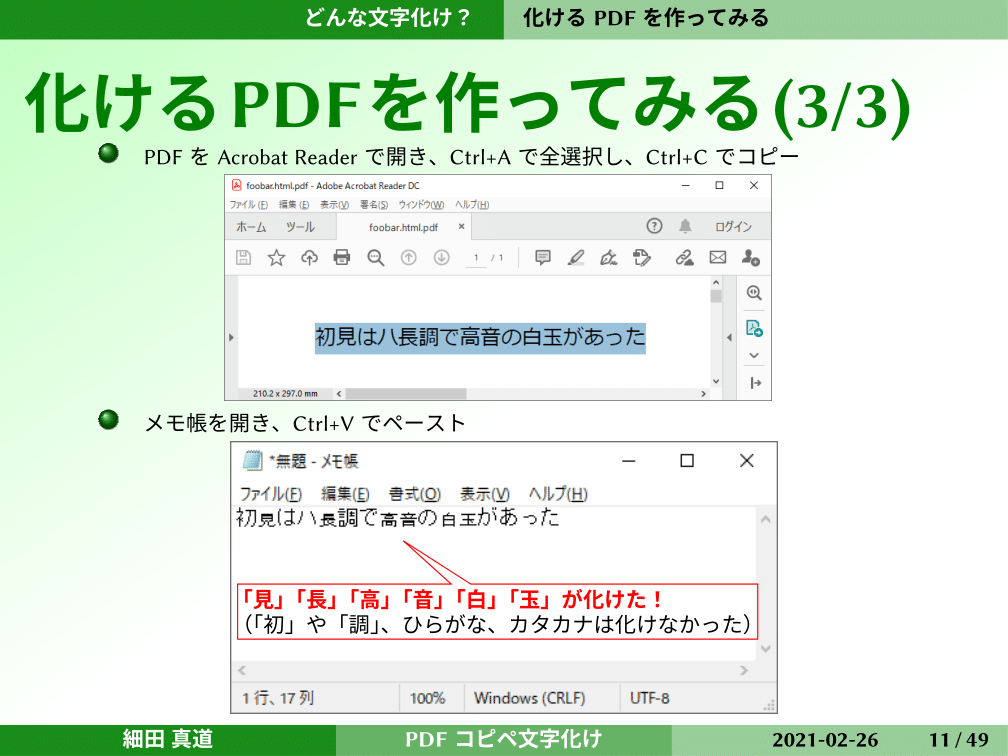
では化けるPDFはどんなものかを、ちょっと作ってみました。普通のWindowsで、Google ChromeとAcrobat Reader。いずれも今月の最新版(2021年2月当時)です。こんな感じのすごく適当なHTMLですが、文字化けしていないものを用意しました。普通にChromeで開いて、印刷でPDFに保存とやって、Acrobat Readerで開いて、全選択してメモ帳にペーストします。
そうすると「見」「長」「高」「音」「白」「玉」などが、他のフォントとぜんぜん違うかたちになっていて、「あ、これ化けちゃったな」と。化けるPDFはけっこう簡単に作れちゃうということです。
では、どうしてこんな文字化けをするかをちょっと説明したいと思います。PDFはすごく昔からあるものなので常にこうではありませんが、実は、大部分のPDFは普通のテキストが中に入っていません。字のかたちのことをグリフと言いますが、どういったフォントのグリフを、どこに配置するかという情報だけが存在しているのが普通のPDFです。そうでないPDFも、もちろんあります。
このグリフを指定する場合、フォント固有の番号で指定する仕組みになっています。この番号のことをCIDやGIDと言いますが、Character IDやGlyph IDという名前の略です。実は同じかたちのグリフでも、フォントによって番号が違うこともあったりするので、“フォント固有の番号”という言い方をしています。
普通の文字コードはUnicodeとか、いろいろあると思いますが、そういったものはPDFの中では使われていない。これが普通のPDFです。

PDFの中身を覗いてみよう
では、PDFの中をちょっと覗いてみましょう、ということですが、普通に中を見てもわかりません。見た方はいると思いますが、一部圧縮されているので、見てもわからないようになっています。これをテキストエディタで見れるように変換できる、オープンソースのQPDFというツールがあります。UbuntuやFedoraなどには、パッケージが普通に入っているので、インストールは簡単にできると思います。
圧縮の解除と、あと中身の改行とかインデントをしてくれて、すごく見やすくなったQDF。PDFではなくてQDFと言いますが、こちらの形式に変換できます。さっきの化けていたPDFを変換します。テキストエディタで中身を見て、このBTとETで囲まれた部分を探してみます。

BTとETで囲まれている部分を抜粋したところです。こんな感じで書かれているんですね。テキストエディタでこれが見れると。PDFの中身はパラメータが先で、オペレータが後という後置記法というか、逆ポーランドの記法になっています。最後のTfやTmがオペレータで、その前に付いているやつがパラメータです。
このTfがフォントを指定するパラメータで、F4というフォント。別のところで定義されていますが、このF4をサイズ16で指定しますよ、ということが書かれている。このTmは座標を指定するもので、6つの数字で座標を指定しています。本丸がこのTjで、文字を出力するオペレータ。
山カッコ(<>)で囲まれている16進数が、どんな文字を出すかを指定しているところになります。これではよくわからないので、一応そこの山カッコを引っ張り出してみました。パラメータは16進数ですが、4桁ずつ取り出すと、先ほどお話ししたフォントの中の固有番号GIDになっています。

このGIDを使って、F4と言われるフォント。実はWindowsのメイリオですが、メイリオからグリフを取り出すことをしています。この16進数4桁の0a42を10進数に変えると2626番になって、2626番のグリフは何かと思ってメイリオの中を見ると、「初」というグリフが出てくる。
その次が09c4です。この09c4の4桁を10進数に直すと2500番なので、この2500番のグリフをメイリオの中から取り出すと「見」という。先ほどの字が、そのままちゃんとわかるということで、文字出力ができました。これがPDFの中身です。

文字出力はできましたが、PDFの内部はCIDやGIDなどの固有の番号で文字を指定している状態なので、フォントのグリフを指定する番号で表示するには非常に都合がいいものの、Unicodeのような普通の文字コードとはぜんぜん関係ない番号になってしまっています。CID/GIDでは絶対にコピペができないので、コピペするには文字コードが必要です。
ではどうしましょうかといったところで、実はPDFの中にはToUnicode CMapが入っています。これは何かというと、CIDやGIDからUnicodeの符号位置、どんな文字なのかという、文字コードへの変換テーブルがちゃんと入っている。これはフォントごとに用意されています。なぜかというと、フォントによって対応関係が違うことがあるからです。コピペできるPDFには、これが入っています。逆にいうと、コピペできないPDFには入っていないということになります。

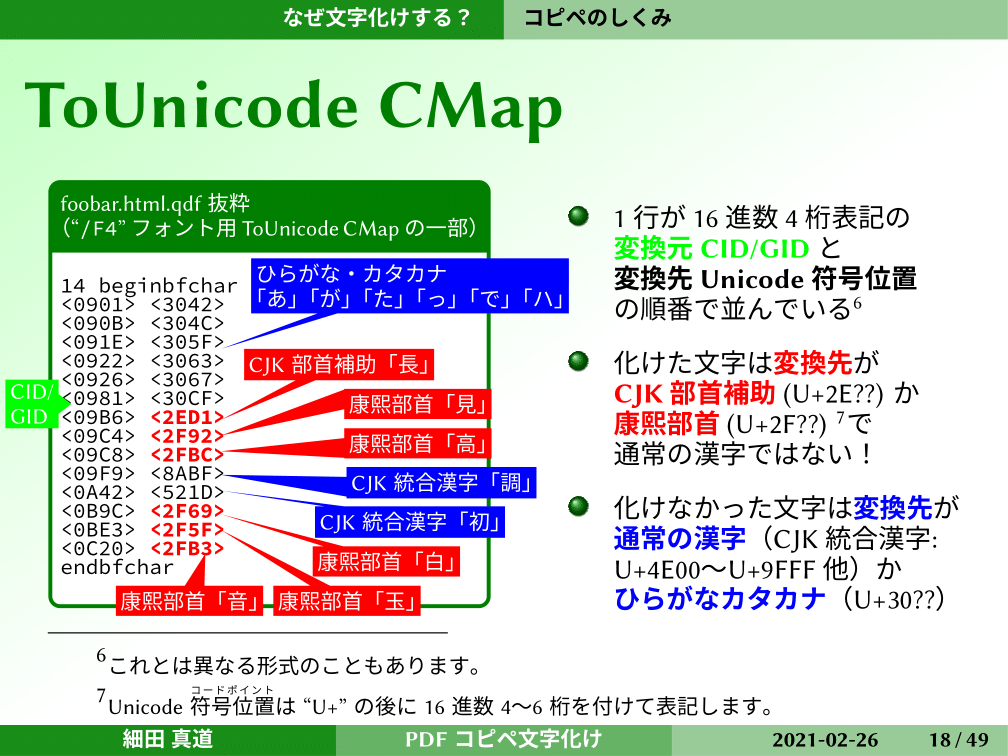
このToUnicode CMapがどうなっているかを見てみましょうということで、先ほどのQDFの中身を抜粋したものがこちらです。よくわからない16進数が2つずつ1行書かれていますが、左側がCIDやGIDです。16進数4桁表記になっています。右側がその変換先のUnicodeの符号位置というかたちで並んでいます。
規格表などを見るとわかりますが、右側はUnicodeなので、この化けた文字の「長」「見」「高」は赤で書いています。この化けた文字は、頭が2Eや2Fなどで始まっているものです。化けていない字、例えばひらがなやカタカナは頭が30で始まっているし、漢字でも化けなかった「調」と「初」は頭が8や5で始まっている。
Unicodeのブロックがぜんぜん違うことがわかります。化けた文字は、変換先がCJK部首補助という名前の2Eで始まるところ。あるいは康熙部首と呼ばれる、2Fで始まる場所になっています。これは普通の漢字ではありません。普通の漢字はCJK統合漢字という、4E00から9FFF。この8や5で始まっているのはこの中のものなので、普通の漢字です。
ひらがなとカタカナは30で始まっている。これも普通のひらがなとカタカナで、化けているのは「ToUnicode CMapがおかしいから化けたんだな」というのが、これでわかります。
康煕部首、CJK部首補助とは何なのか。康煕部首は18世紀ぐらいの康煕字典という字典の部首だとか、CJK部首補助はそれに載っていなかった比較的新しい部首だとか、そういう話はありますが、問題なのは、通常の漢字であるCJK統合漢字と言われるブロックと、同じかたちのものが部首の中に入っていることです。
同じかたちが違うUnicodeの符号位置にある。これを取り違えると文字化けが出ることになります。なぜ取り違えるのか。さっきの問題があるToUnicode CMapを作るのは、PDFを作成したツールです。そのため、PDF作成ツールに問題がある。広く使われていても、問題があるツールはあります。つまり、さっきも例に出た「Chrome」は問題があるツール(2021年2月当時)ということになります。

文字化けはフォントにも依存する
もう1つ、実はフォントにも依存します。問題のあるPDF作成ツールを使うと、トリガーを引いてしまうフォントと、そうでないフォントがあります。古いフォントであればそうでもありませんが、最近のフォントの多くはトリガーになってしまいます。ただ、フォントには問題がないです。

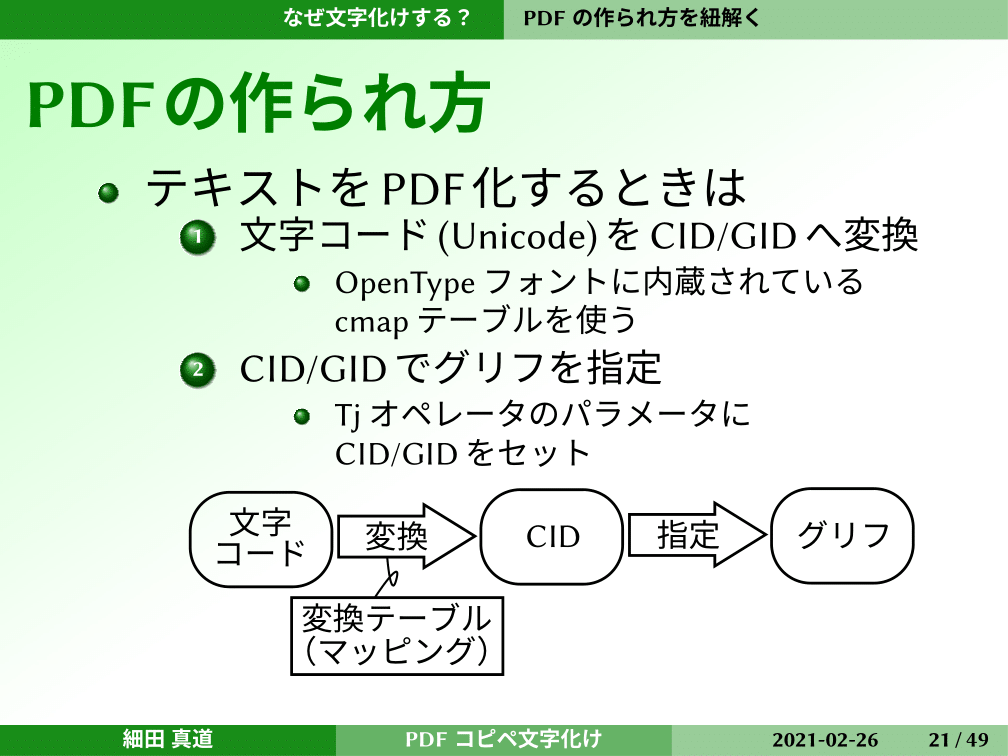
では、どうしてトリガーを引くとこうなってしまうのか。PDFの制作過程をひもといてみます。テキストをPDF化するときに、最初に文字コードがあると思いますが、これをCIDやGIDに変換する手順を踏みます。このとき、OpenTypeフォントに内蔵されているcmapテーブルを使って変換して、CIDやGIDでグリフを指定する。先ほどのPDFの内部のTjオペレータで指定するかたちになっています。
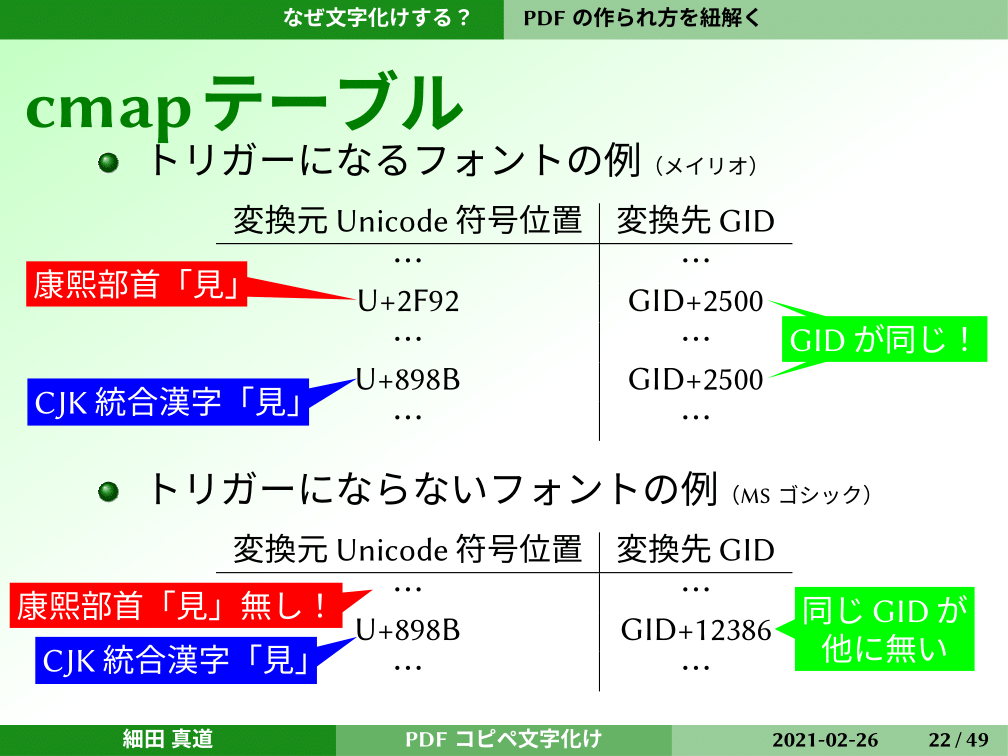
cmapテーブルはどうなっているのかをちょっと見てみます。トリガーになるフォントの例、先ほどの例だとメイリオですが、変換元のUnicodeの符号位置は康煕部首の「見」は2F92ですが、これとCJK統合漢字の「見」は、Unicodeの符号位置は違うものの、変換先のGIDが同じになってしまっています。
メイリオの場合は、このように「見」が部首の「見」でも普通の漢字の「見」でも、GIDの2500番になっています。トリガーにならないフォントの例として、MSゴシックを例に出しました。普通の漢字の「見」は存在しますが、部首の「見」がありません。同じ「見」ですが、GIDとしては12386ということで、このGIDは他に同じものがありませんでした。ということは、1個しかない。この状態がトリガーにならないフォントということになります。
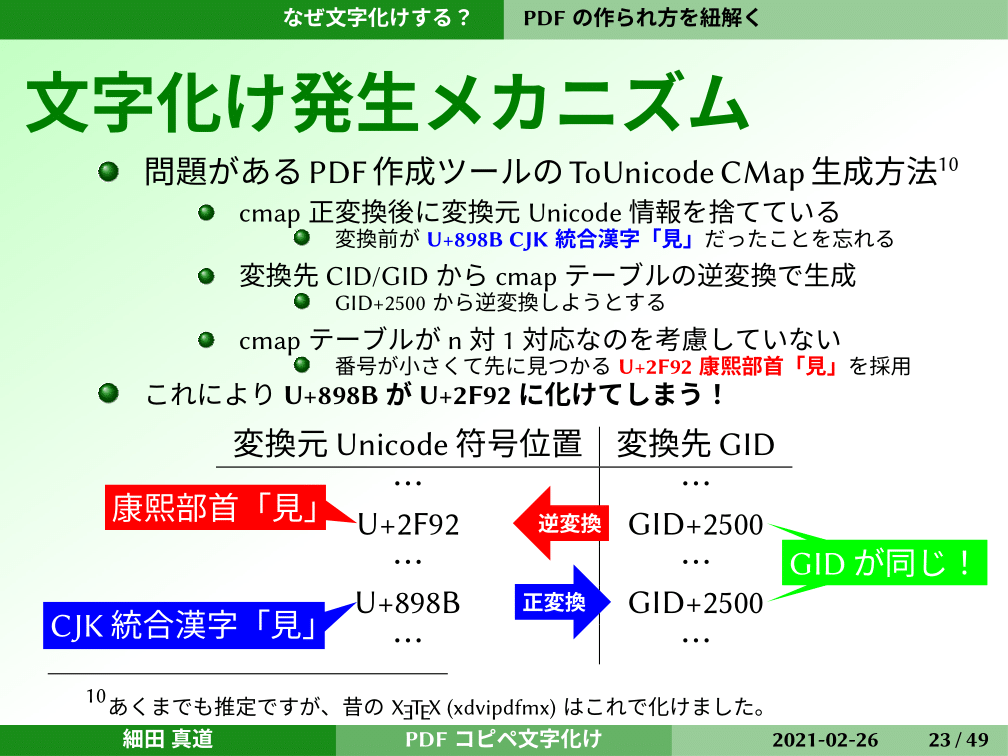
だいたいわかる方はわかってきたのではないかと思います。文字化けの発生メカニズムとしては、cmapのテーブルで文字コードの「見」が入ってきたとき、正変換してGIDに変換します。2500番ということがわかった。このときに、変換前が898Bだったことを忘れてしまいます。2500番という数字だけを残して、これでPDFを作ってしまう。
あとから「2500番からToUnicode CMapをcmapテーブルの逆変換で作ろう」というかたちになっている。このテーブルを上から順番に見ていくと、GIDの2500番はここにあった。Unicodeの符号位置は2F92だ。ここから逆変換で求めて、本当は符号位置が2種類あって、変換先が1種類なのでN対1なのですが、番号が小さくて先に見つかる康煕部首の「見」を採用してしまう。2F92ということで、ToUnicode CMapを作ってしまう。これで化けてしまいます。
(次回につづく)