ゼロからリアルタイムサーバーを作るまで
清水佑吾氏(以下、清水):本日はお招きいただきありがとうございます。株式会社gumiの清水と申します。よろしくお願いします。今日は「ゼロからリアルタイムサーバーを作るまで」ということで発表します。
まずは会社の説明をさせてください。私は株式会社gumiというところで働いております。

2007年にできた会社で、主にモバイルゲームを作ったり、VR・AR・MRと呼ばれるXR事業をやっていたり、最近はブロックチェーンまわりをやっていたりする会社です。

私は2011年にgumiに入社して、何本かゲームを作ったあとに共通基盤の部署に異動し、現在は共通基盤を作ったり運用したり、あとはR&Dのマネージャーをしております。
今日話すことは「リアルタイムサーバーをプロトコルから設計,実装,試験,運用した話」です。

作ったサーバーはARKという名前で社内で運用しているのですが、モバイル向けの2対2の対戦アクションゲームだったり、お手伝いでVRのライブ事業の裏側で使われております。

リアルタイムサーバーとは何か?
リアルタイムサーバーの話をするんですが、そもそも「リアルタイムサーバーとは何ぞや?」ということで、簡単に説明したいと思います。

いわゆる1対1の対戦ゲームをモバイルで作りたいと思ったときに、実際はコンピュータは2台あるんですよね。ですがキャラクターが2体なのかというと実はそうではなくて、それぞれの端末でそれぞれ自分の自キャラを操作しているわけですが、このままだと自分のスマホの中には自分のキャラしかいません。
なのでどうするかと言うと、自分の操作した結果を相手のコンピュータに通信してコピーを作ります。そうするとそれぞれの端末に2キャラ出てきて1対1の対戦ができるようになります。
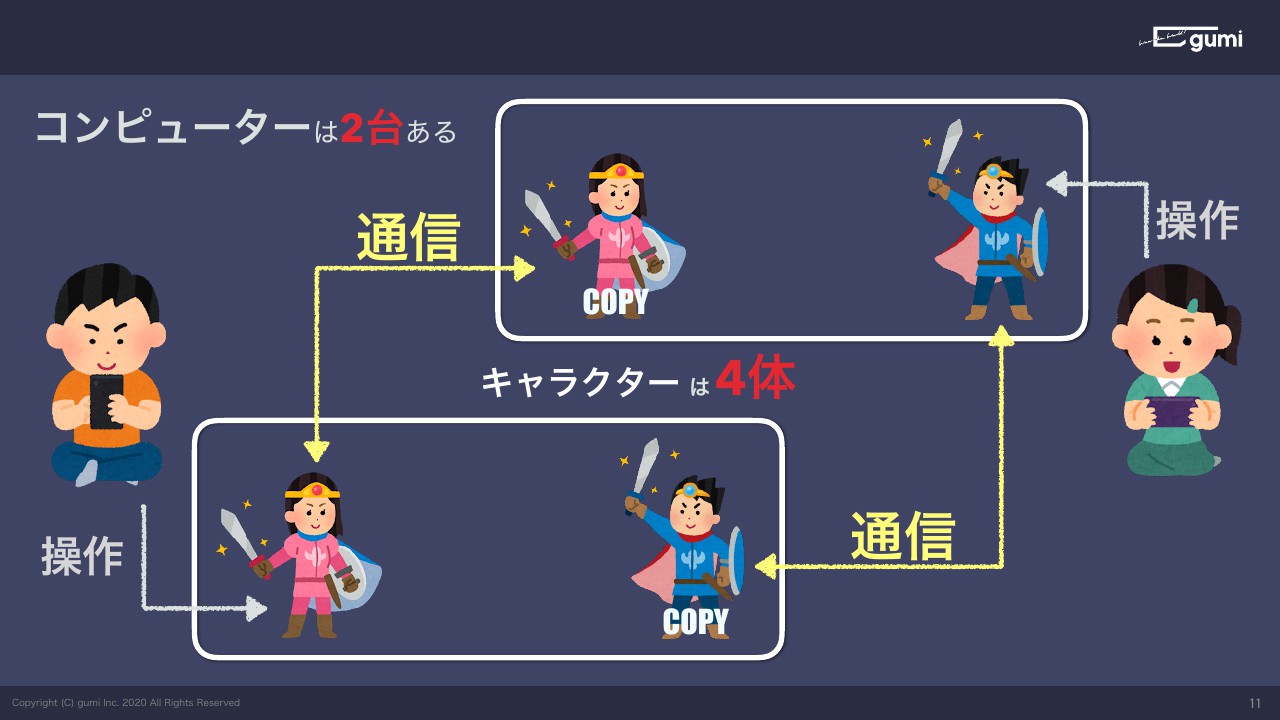
では、これを扱うシステムはいったいキャラクターを何体操作しているかというと、システム全体でキャラクターが4体存在しており、これらをコントロールするコードを書かなければいけない状態になります。
こんな状況なので、相手に情報がすぐに伝わってほしいわけですよね。対戦相手からダメージを受けたらすぐに自分のオリジナルに影響がないと無敵みたいになってしまうので、すぐにオリジナルに伝わってほしい。「すぐに」というところがポイントです。
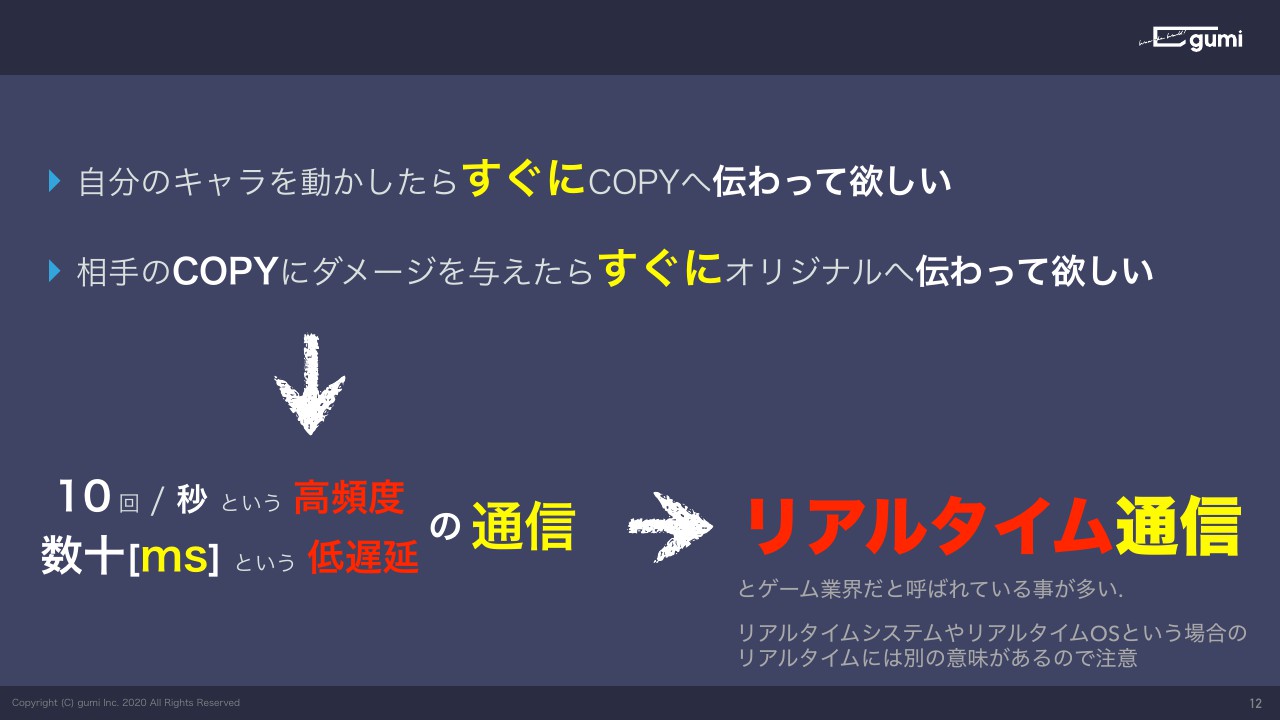
だいたい1秒間に10回ぐらい。レイテンシーで言えば数十ミリ秒ぐらいの低遅延を求められる通信を、リアルタイム通信と呼んでいます。
完全に余談なんですがリアルタイムシステムとかリアルタイムOSというのがあって、そこではリアルタイムという言葉が今回とはちょっと違う別の意味で使われているので、そういうものを見かけたときは注意をしたほうがいいです。
この2台のマシンの間で通信を介在するリアルタイムサーバーというのが今日のお題になります。
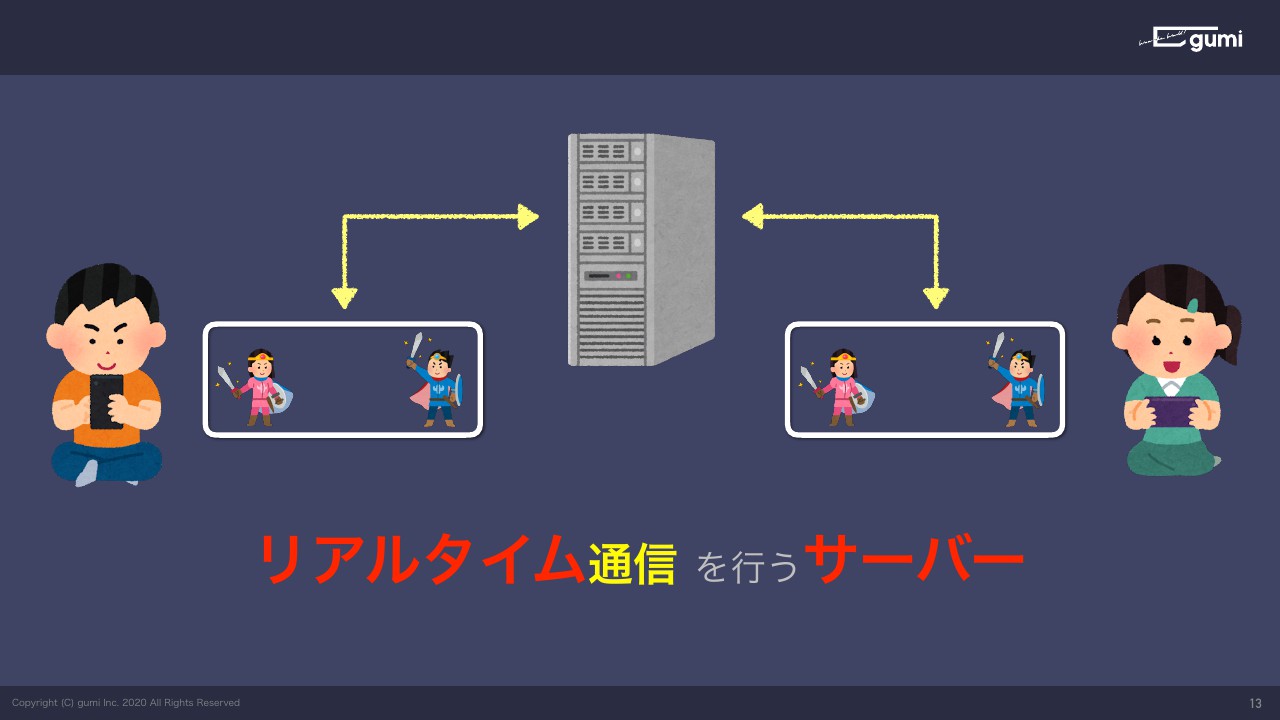
求められるネットワーク
アジェンダなんですが、ざっくりネットワークの話とPub/Sub、あとはプロトコルと運用に向けていろいろやった話の4つに分かれてます。
さっそくネットワークの話からしていこうと思います。

こちらは先ほどもあった要件ですよね。1秒間に10回、あとは数10msという低遅延の通信。これを既存のモバイルゲームでよく使っているWebのHTTP APIで実現するのはなかなかツライです。
1端末が1秒間に10回通信をしてくると、なかなかなサーバーの負荷にもなりますし、そもそもHTTPヘッダーをパースしているだけでまぁまぁな時間が掛かってしまうので、既存のHTTP APIではちょっと難しいです。

そこで「リアルタイムサーバーだ!」と思うんですが、とりあえず落ち着きましょう。本当にサーバーが必要なのかどうかを考える必要があります。先ほども言った通り、単に通信するだけなら端末同士が直接通信をすれば解決する話なので、わざわざサーバーを用意しなくてもいいのではないかと思うはずです。もちろん直接通信をするとメリットがあります。

レイテンシー的に一番有利です。まぁ、当たり前ですよね。端末間を最短経路でつなぐのは直接つなぐことです。サーバーを通すと、例えばサーバーが大手町に置いてあったら札幌の人が青森の人と通信をする際に一度大手町を経由しているので、その分だけデメリットが生じます。あとはシステムを構成する要素が少ないです。サーバーの出番がないので単純にクライアント間のコードだけで完結するとシステムやコードがシンプルになります。
また、当たり前ですがサーバー代が無料です。実質無料ではなくて、本当に無料です。先ほどもありましたが、そもそも高頻度通信なので高負荷です。高負荷なのでサーバーに任せるとまぁまぁなお金が掛かります。この辺があるので、直接通信にはもちろんメリットが非常に多くあります。

逆に直接通信、P2Pでやった場合のデメリットは何かというと、まずつながりません。あとは参加台数が増えると急激に複雑になります。あと、つながりません。そしてクライアントで完結してしまうので通信をコントロールすることができない。いわゆるチート対策が難しいということ。そして最後にやっぱりつながらない。では、どういうことか1個ずつ説明していきます。
P2Pとサーバーを比較する
参加台数が増えると急激に複雑になるというのはどういうことかというと、3台のマシンがあったときは、それぞれがそれぞれの端末につながっているので通信経路は3本ですよね。ここで4台の対戦をしたいと思ったとき、通信経路は3本増えて全部で6本という状態です。
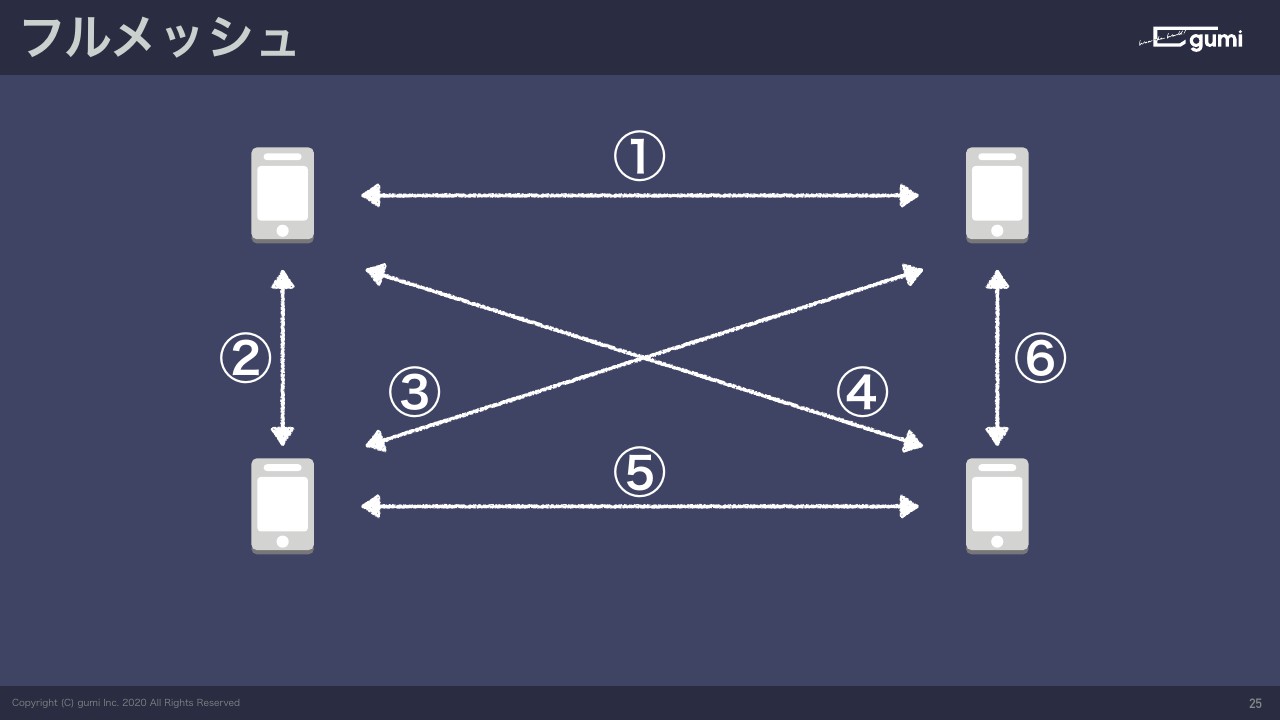
じゃあ5台で通信しようと思うとどうなのかというと、それぞれとまたそれぞれの端末が通信しないといけないので全部で10本の通信経路が必要になってきます。
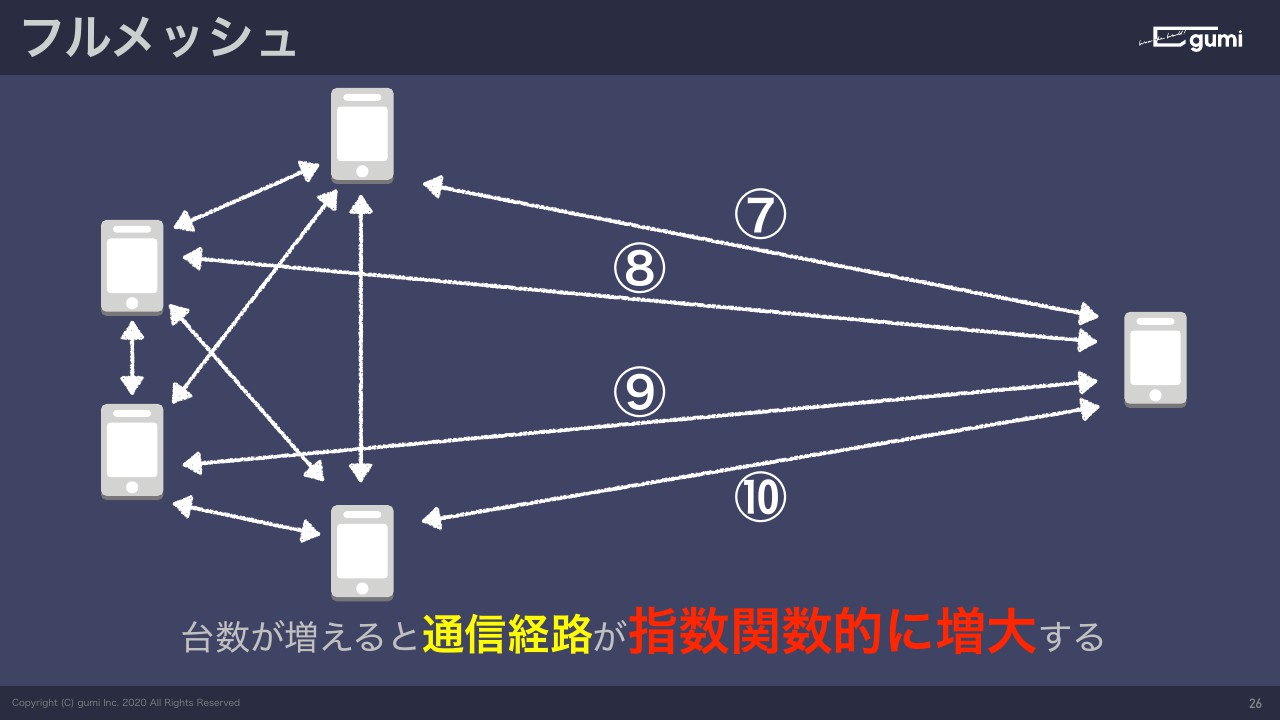
台数が増えると通信経路が指数関数的に増大していきます。なので、3台ぐらいまでだったら別にいいんですよね。ただ、それ以上になると通信経路の増大は無視できない状態になってきます。
それに対してサーバーがいた場合。3台のときはサーバーとで3本。もう1台増えたときも1本増えるだけ。もちろん5台になったときも1本増えるだけ。
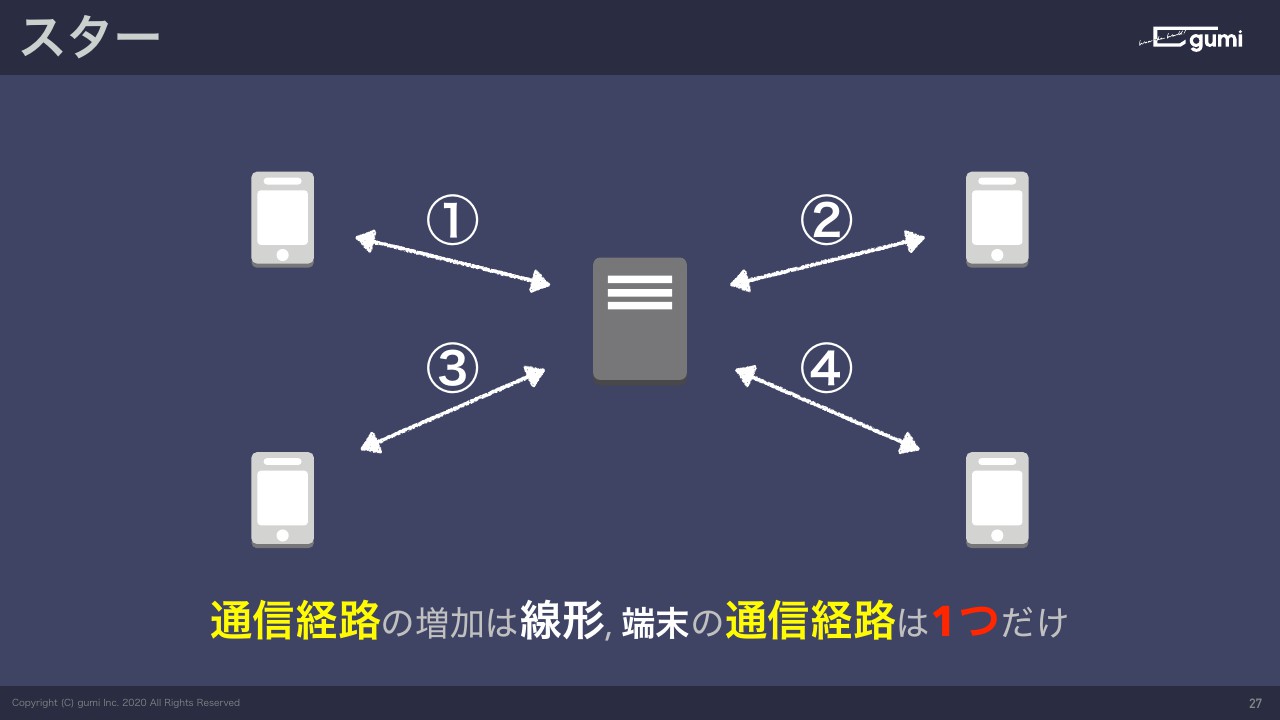
なので先ほどのように台数が増えたとき、指数関数的にではなくて、台数分の通信経路があるだけなので、台数が増えると優位になってきます。
あとはチート対策についてですが、言うまでもなく相手のクライアントに悪意があったら操作命令を無視して相手のユニットを動かないようにしてしまったりとか、逆にあり得ないようなダメージを送信したり、対戦相手にしてみたらたまったもんじゃないですよね。

これらを対策するにはクライアント側のチート対策ツールが一般的にいろいろ出回っているのですが、いろいろと限界があります。
なぜ繋がりにくくなるのか
最後につながらないの話。先ほどあった1:1の通信を図にするとこういうのをイメージするとは思います。
ですが実際にインターネットを経由して通信するというのはどういうことかというと、こんな感じなんですね。

一番左がキャリアのネットワークで、端末から無線でつながってキャリアのネットワークに入って、プロバイダを経由してインターネットに出て、相手のプロバイダまで一旦つながって、そのプロバイダから家庭のルータにつながってという、とても複雑な経路を通ってインターネットはつながっています。
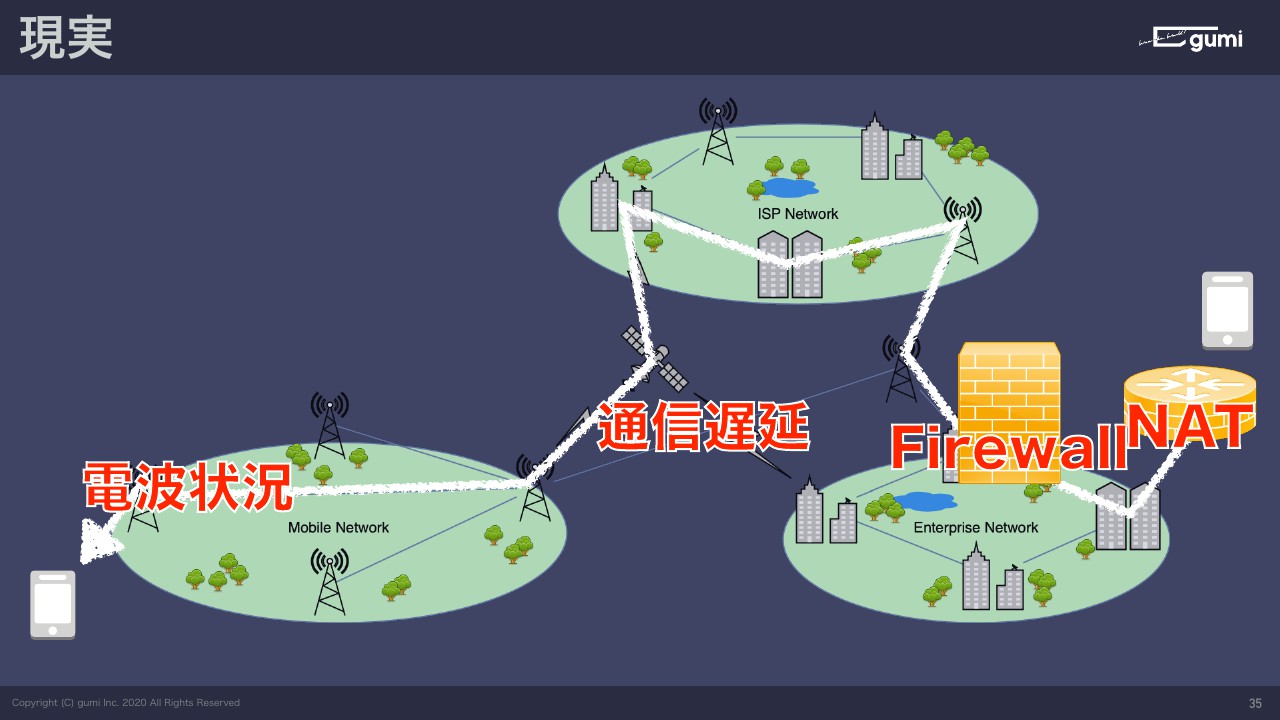
なので、例えば電波状況が悪かったり途中の経路で通信遅延があったり、途中に潜むファイアウォールがあったり、ルータがいてNATをしていてそもそもグローバルIPを持っていなかったりします。NATでつながりにくいというのは何かと言うと、ネットワークの設定をした方はわかると思いますが、そもそも自分の端末に直接割り振られるIPアドレスはグローバルIPではないんですね。

このルータの中にいる範囲内でしか有効でない、内線番号みたいなものですね。内線番号しかない人が海外とかぜんぜん知らない電話番号に電話を掛けるのは無理ですよね。じゃあグローバルのIPアドレスを持っているのは誰かというと、たいていはそのネットワークにいるルータが持っています。
ルータのグローバルIPはあるんですが、この状態だと、端末は自分のグローバルIPを持っていないので、「自分につながってくれ!」と言って自分のIPアドレスを教えたいとしても、我々の作ったゲームが動いているのはそれぞれのスマホの中なので、自分のグローバルIPを取得するだけでも骨が折れます。
ルーターのグローバルIPを取得できたとしても、何もしなければ自分のローカルIPにパケットが飛んでくることは基本的にはありません。というわけで、そもそもNAT間のP2P通信はそう簡単には実現・成立しないです。いろいろやり方はあるんですけどね。
あとは、さまざまな理由で通信の切断とか遅延が起こります。しかもそれらの状態を接続数分、通信している間は常に管理する必要があります。先ほど5台端末がいたらP2Pで場合は10本の通信が必要になりましたが、これらの事象が10本分それぞれ別々に生じて別々のものとして管理し、それらを統合してゲームの進行を管理する必要があります。
なので「P2Pでやっている人はとてもすごい人だな!」と思っています。
サーバーで解決できること
こういった問題はあるのですが、サーバーがあればそもそもサーバーがグローバルIPを持つでしょうし、そうであればそもそもつながるように作ると思うので、つながらない原因のほとんどがクライアント側の環境になってきます。

あとは、常にサーバーがグローバルIPを持っているのでTCPは高確率でつながります。UDPが禁止なネットワークもけっこうあると思うんですが、そういったものはほとんど、そもそもTCPがつながれば大丈夫です。
あとは、台数が増えても直接つなぐのはサーバーとクライアント間のみになります。なので片方、そもそもクライアント同士だと確実なものが何もない状況で通信を確立させないといけないのですが、サーバーとクライアントという話になれば、サーバーの環境は我々のコントロールがある程度効くので、クライアント側の問題を解決することに集中できます。
なので、そのサーバーにすごく助けられながら通信を管理すればよいというのがサーバーを置くことのメリットですね。チート対策とかはゲームレベルの話が関わってくるので、サーバーがいるからといって確実に解消することは難しいのですが、そもそもの通信量のメトリクスを取ったりデバッグログを出したりとか、怪しいものがあったらそれだけ生ログを取ったり、サーバーがあれば多くのことができるようになります。
というわけで、ネットのリアルタイムサーバーはほしいですね、という話になります。主にネットワーク面の理由から、P2Pモデルではなくてリアルタイムサーバーがほしいという話になります。
リアルタイムサーバーを作るにあたって
それでは次に、リアルタイムサーバーを作るとなったときにどういったものを作っていくかを話したいと思います。
「リアルタイムサーバーを作るぞ!」と、なったのは良しとしてどういうものを作るかとなったときによくあるのが、ゲーム独自のプロトコルとロジックを使ってゲームサーバー、リアルタイムサーバーを作ります。MORPGとかMMORPG、対戦型ゲームでもよくある話です。そもそも全部フルスクラッチでリアルタイムサーバーを作ってしまう。
ただ、私がいたのは共通部門だったので、我々は汎用ネットワークサーバーを作ることにしました。ゲームごとに毎回作るとスキルのあるエンジニアがアサインできて実工数があればもちろんいいんですが、モバイル場合だとそもそも仕様がコロコロ変わったりするので、毎回そこまで作り込む時間がありません。
あとはWeb出身のエンジニアが社内に多くてこの辺のリアルタイムサーバーを作るようなノウハウを持っている人間が少なかったので、なるべくネットワーク周りのところはあまり気にせずにゲームの開発が集中できるように作りたいというところから出発しました。その結果、さまざまな通信のスタイルが考えられます。

例えば1:1もそうですし、1:N、1人のメッセージをたくさんの人に配信することもあります。逆にたくさんの人が1人にメッセージを送り付けたり、そもそも8人部屋で全員が好き放題に喋るし、好き放題に受け取るということもあるので、これらを抽象化して扱える必要が、汎用的なリアルタイムサーバーには求められます。
その結果が、Pub/Subモデルです。
Pub/Subモデルとは何か?
では「そのPub/Subモデルとは何ぞや?」というと、一言で言うとこういう非同期メッセージングモデルの一種という話になります。サブスクライブ……購読と訳されますが、特定のメッセージを購読すると宣言しているユーザに対してメッセージをパブリッシングする。じゃあ、それをどう管理するかと言うと、トピックという単位でサブスクライブする。
「購読したいですよ」というユーザは、例えばXX新聞がある。「XX新聞を購読します」と言っている人たちにXX新聞の社員は記事を配っているわけですよね。実際に誰が記事を読んでいるかは、実はXX新聞の記者はあまり気にせずにXX新聞を購読すると言っている人に記事を配っている。それに近いモデルなのでPub/Subモデルと呼ばれています。
XX新聞という1個のトピックでは大変なので、そこは文字列で管理できるようになっています。なのでパブリッシュ側は、この特定のトピックをサブスクライブしている人たちに対して、「このトピックをメッセージで送りますよ」と言うだけで誰がメッセージを購読しているかを気にせずにメッセージを送れます。このことでパブリッシュ側にしてみれば誰がつながっているとか、誰が既に読んでいるかみたいなことは気にせずにメッセージを送ることができるモデルになってます。
実際にどんなフローになるかを紹介しようと思います。例えば左側3台がメッセージを受け取りたい側です。
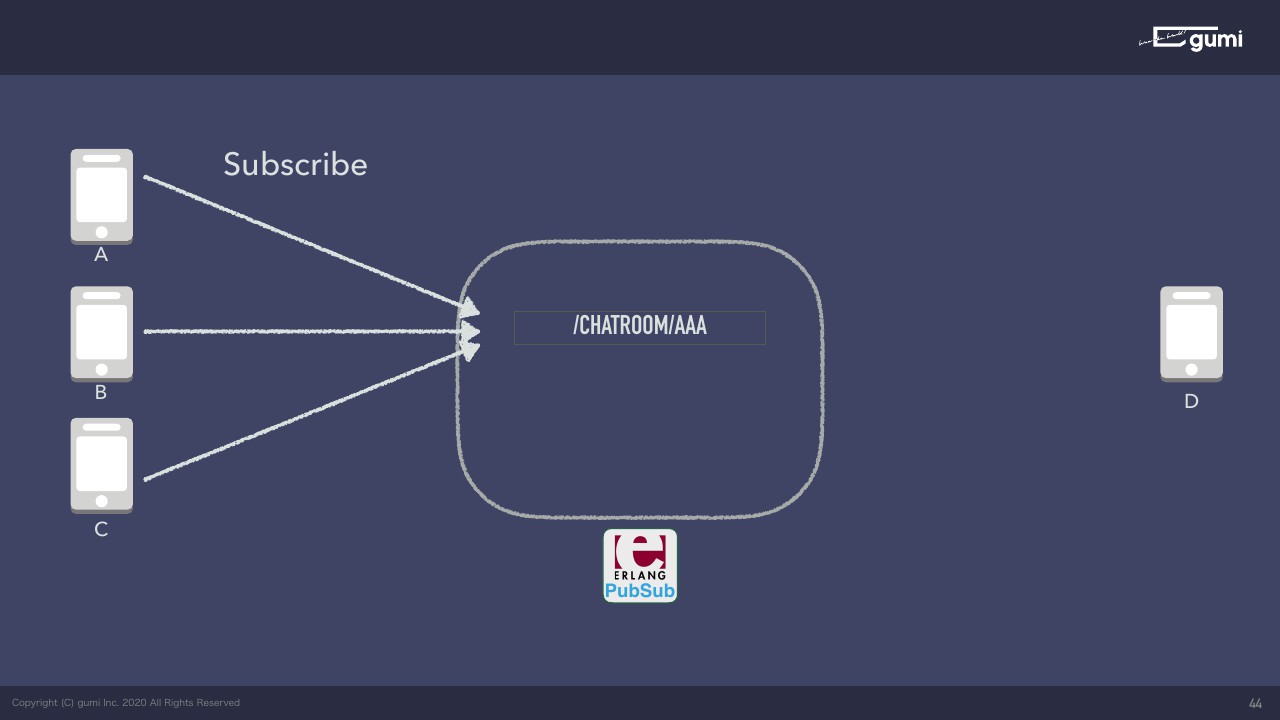
最初に「CHATROOM/AAA」みたいな文字列をサブスクライブしますと、先にクライアントが購読を宣言します。これをサーバーが管理するわけですね。そうしたら端末Dは、そのCHATROOM/AAAを購読している人たちに対してメッセージを送りたいですという指令をサーバーに送ります。
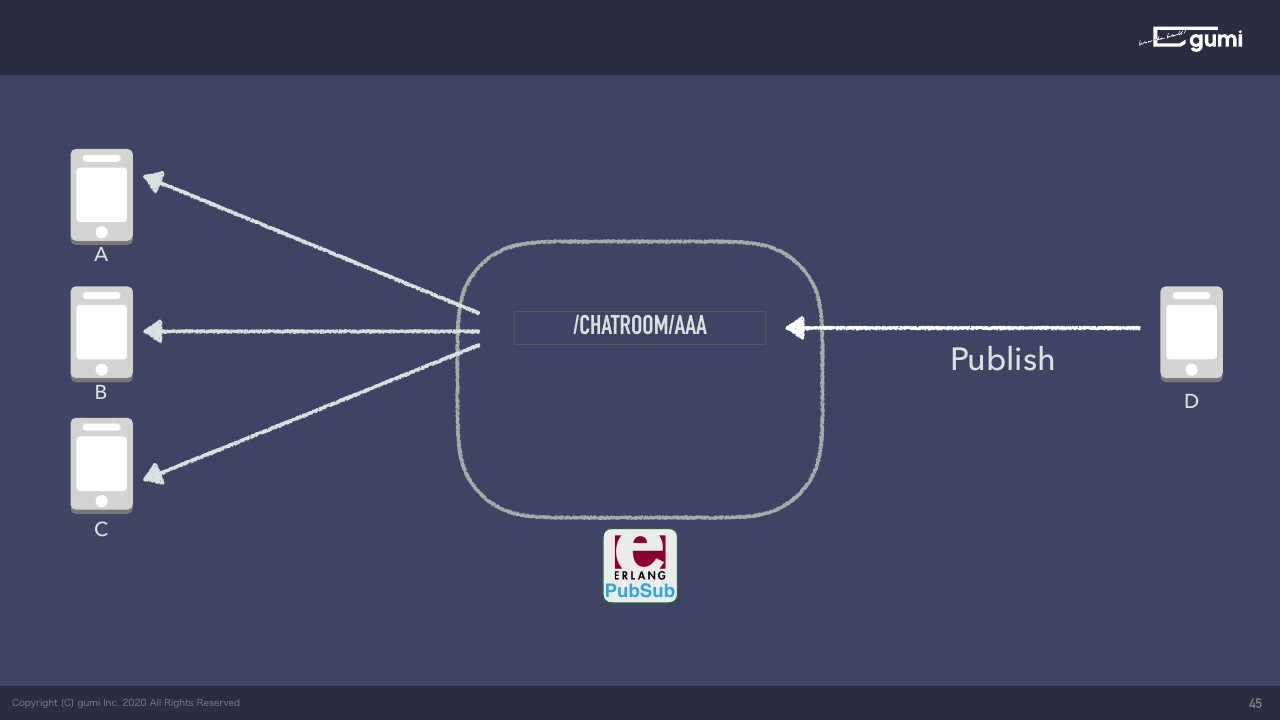
そうすると、サーバーはCHATROOM/AAAをサブスクライブしている人はみんな知っているので、その人にメッセージを送ってくれる。要はPub/Subモデルはこれだけです。別にトピックが1個しかないということはないので、端末CはTOPIC/BBBみたいなところもサブスクライブしたいですよというのを先にやっておけば、DはTOPIC/BBBへパブリッシュすれば、Cにだけメッセージが発信されます。

ROOMモデルとの違い
これがPub/Subモデルなんですけど、よくあるROOMモデルとはどう違うのかですね。

チャットルームというイメージが近いんですが、普通のルームモデルだと1ルームにログインしたら、そのルームにいる人たちにメッセージを発信できるし、そのルームに入っていればメッセージは受信できるという、よくあるかたちです。
ROOMモデルとPub/Subモデルの違いで大きいのは、サブスクライバーがゼロのトピックにもパブリッシュできます。誰も購読していないけどメッセージを送ることができます。これで何がうれしいかと言うと、エラーになりません。パブリッシュ側はとにかく送ればいいだけ。Pub側はトピックをサブスクライブする必要がないんです。
要はルームモデルだと普通は1ルームにログインしましたというときに、ルームへのメッセージを受信するようになってしまうことが多い。ルームに入るということは発信する権利を得ると同時にメッセージを受信してしまうことになるので「いや、俺はみんなにメッセージを配信したいだけなんだ」みたいなことがROOMモデルだと基本的にはほとんどできないことが多いです。
3つ目の便利なところとしては、ルームの管理が不要です。ルームを作るとなると、たいていリアルタイムミドルウェアとかがあると思うのですが、そもそもルームを作成しないとルームに入れないとか、ルームの状態、ルームに今何人いるかであったりMAX人数はなんだかんだということを管理する必要があり、たいていはそれをデータベースか何かで管理する必要が出てきます。
Pub/Subモデルの場合はそもそもサブスクライバーは数人しか管理をしていないので、ルームの作成のようなコマンドがなくなります。なので、その分だけ実際のフローもシンプルになりますし、サーバー側のコードもシンプルになります。
ゲームでの使われ方
では、そのPub/Subモデルを使ってどんなゲームを作るか。実際のゲームではこういうかたちで使っています。
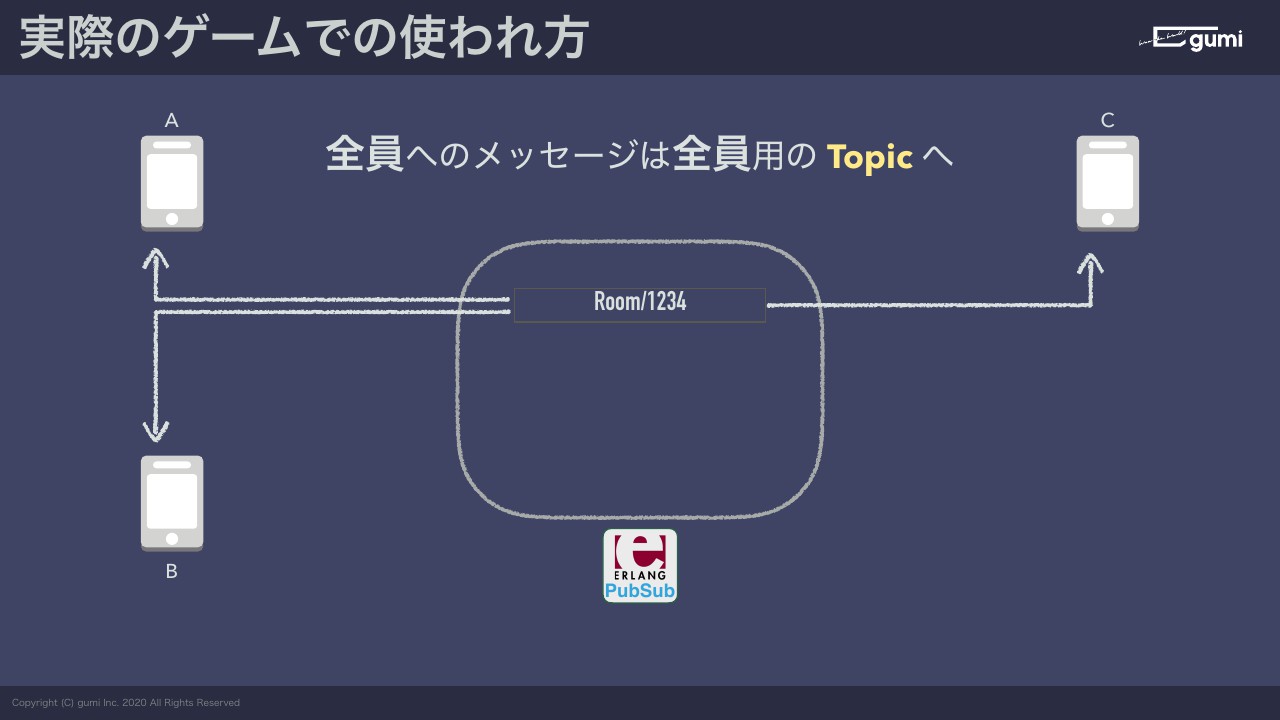
ルームに近いことをPub/Subモデルでやりたいので、どうするかと言うと、Room/1234に入りますという人たちが全員Room/1234をサブスクライブするようにクライアントのコードを書きます。
とはいえ、1人に対してメッセージを送りたいこともあるので、Room/1234にいるユーザAさんというトピックを1個作ってAさんはこれをサブスクライブする。
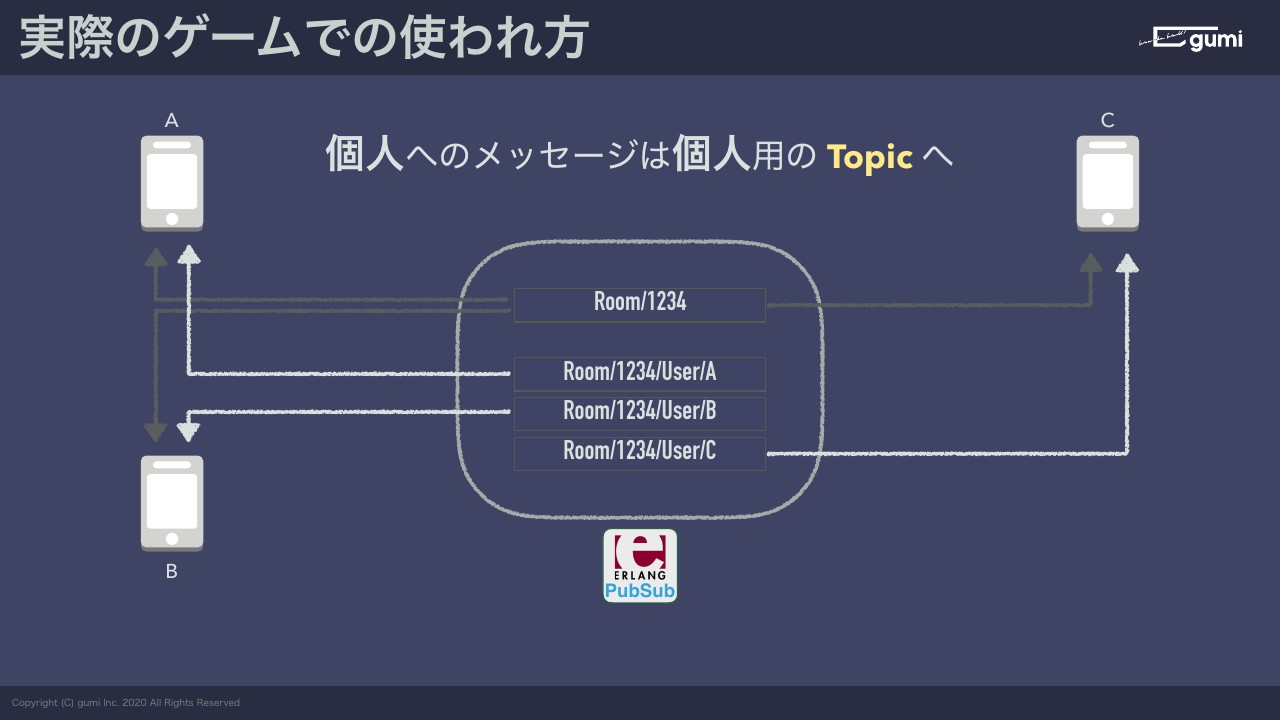
BさんはユーザBのトピックをサブスクライブする、CさんはユーザCのトピックをサブスクライブするというのをクライアント側で作り込んでおく。すると、それぞれの個人向けトピックと全体トピックをそれぞれサブスクライブしている状態になるので、あとは送る側が全体に送りたいのか、誰かに送りたいのかみたいなものを、発信先のトピックを切り替えることでルームとなることができます。
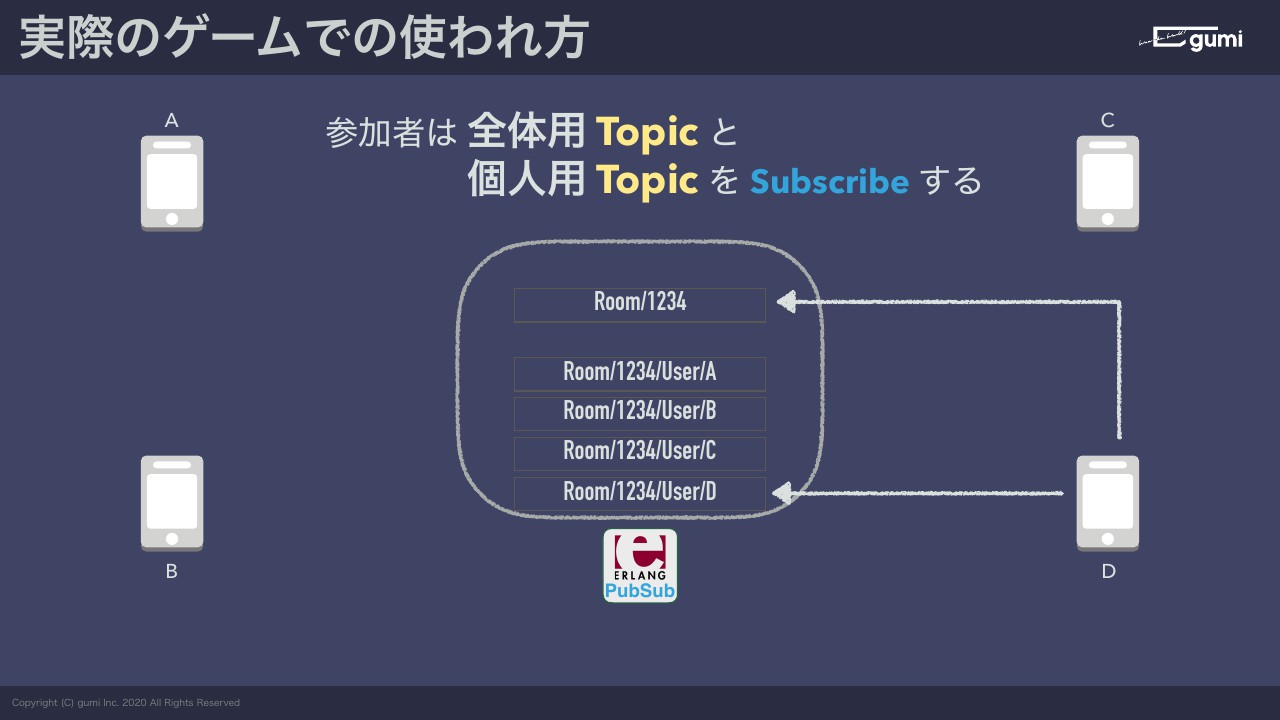
なので、開発者にとってトピックはメッセージの宛先グループの名前みたいなものです。
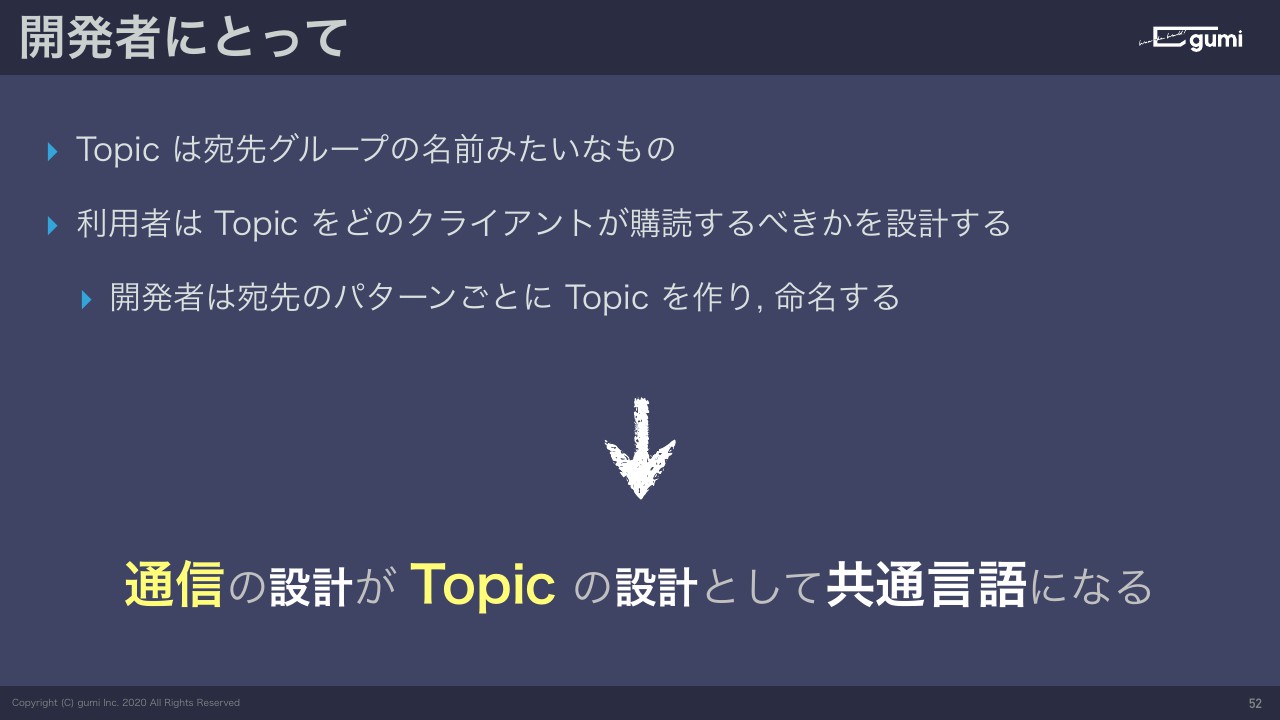
開発者はトピックをどのクライアントが購読するべきか。つまり、誰がメッセージを受け取るべきかというところを設計します。トピックは必ず名前が付くので、宛先があるということはそこにメッセージが向かうというロジックがあるということなので、通信の設計がトピックの設計というかたちで、共通言語になります。
これの何がうれしいのかと言うと、トピックを基準にすべての通信が表現されているので、すべての通信パターンにTopicという名前が付きます。そうすると、トピックをどう設計するかというかたちで通信の表現が統一されるので、別のアプリケーションをまたがってノウハウの横展開が可能になります。
「こういうパターンのときはこういうトピックを設計しました」というかたちで、違うゲームの間で通信のこう作ったというのが表現として統一されるので「なるほど、こういうときにはこういう使い方があるのか。じゃあ、僕もこれだけマネしよう」ということが、容易にできるようになります。
あとは同じ概念モデルでコードが実装されるので、ぜんぜん知らないアプリを見たときにトピックをどう扱っているかに集中してコードを読めば、「このクライアントがこれを読むのか」、「このクライアントはこういうときにここに向かってメッセージを投げるのか」を判別することが容易になります。
サーバー側の実装
では、そのトピックをサーバー側の実装としてどうしているかですが、今日はメインじゃないのでアレなんですが、ErlangというVM言語の上でこれらのリアルタイムサーバーを実装しました。トピックの実態というのはErlangに付属しているETSというオンメモリデータベースに格納されています。

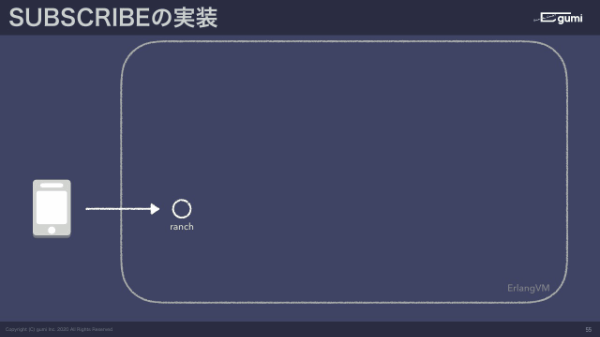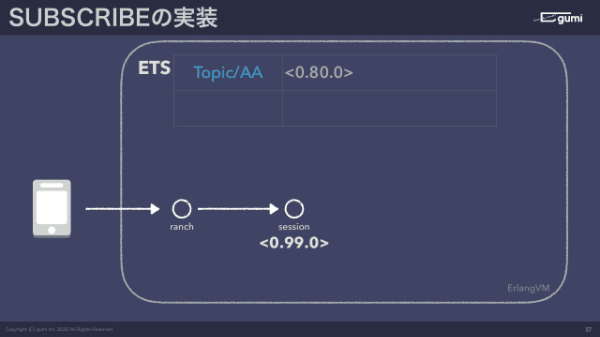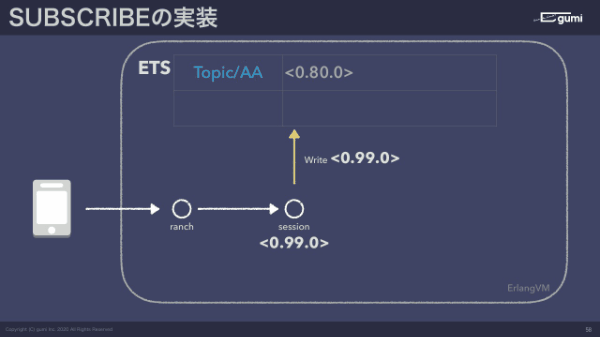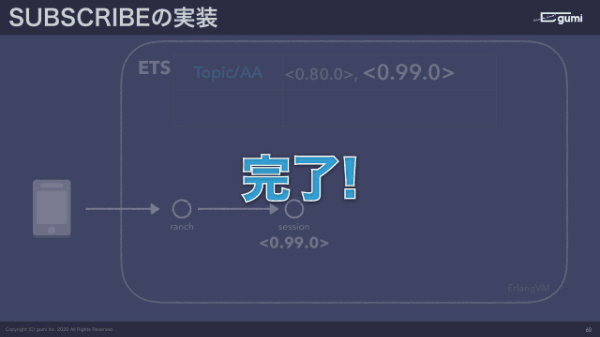
クライアントが1接続すると1プロセス、スレッドみたいなものですね。1スレッドが作られて、スレッドごとにIDがあります。サブスクライブすると何をするかと言うと、トピック名をキーにして自分のスレッドIDを書き込むというかたちをとっています。パブリッシュ側はトピックをキーにしてサブスクライブしているスレッドIDの一覧を取ってきて、そのスレッドに向かってメッセージ送信を行うだけです。
図にして説明すると、端末がサーバーに対して接続するとセッションというスレッドが1個できあがります。これのスレッドのID、PIDが0.99.0だとします。ETSという、オンメモリKVSにTopic/AAをサブスクライブしますよと来たら、この表に自分のスレッドIDを記述します。サブスクライブ中に処理しているのは本当にこれだけです。
パブリッシュするときはどうするかと言うと、つながっているコネクションに対して「Topic/AAにパブリッシュしたいです」と言われたら、このオンメモリKVSのTopic/AAの一覧、バリューを読み込んできて、0.80.0と0.99.0に対してメッセージを送信するだけですね。
一番右側が0.80.0のスレッドですが、そのスレッドの先はもちろんクライアントの端末につながっていて、向こう側のセッションがメッセージを受け取ったら、自分がつながっている端末にメッセージを送りつけるということをやっています。

これでパブリッシュ自体は実装完了です。
このように実装はすごくシンプルですし、何かロックをするようなこともないので非常にパフォーマンスが出やすい構造になっています。
ここまでがPub/Subモデルの話になります。
バイナリプロトコルの例
次にプロトコルですね。こういったことを実現しようと思ったとき、サーバーとクライアントを専用のプロトコルで結びます。みなさんはWebのAPIを書いたことがある方がほとんどだと思うのですが、WebのAPIを作るときも考え方は、このキーでこういうデータを送りたいということをJSONのキーとしてこれが必要で、これがintで……というのを、どんな名前で入れるとか、これはリストにしたいとか、これはディクショナリがいいとか、これはストリングしようかなみたいなものを考えていくと思います。
やるのはそれと大差ないのですが、ちょっと入れ方が細かいです。どういうことかと言うと、これはMQTTというバイナリプロトコルの例なんですが、バイナリプロトコルを表現するときにJSONみたいにスキーマを表現する方法があって、左から1マス、これ1マスが1ビットと思ってください。
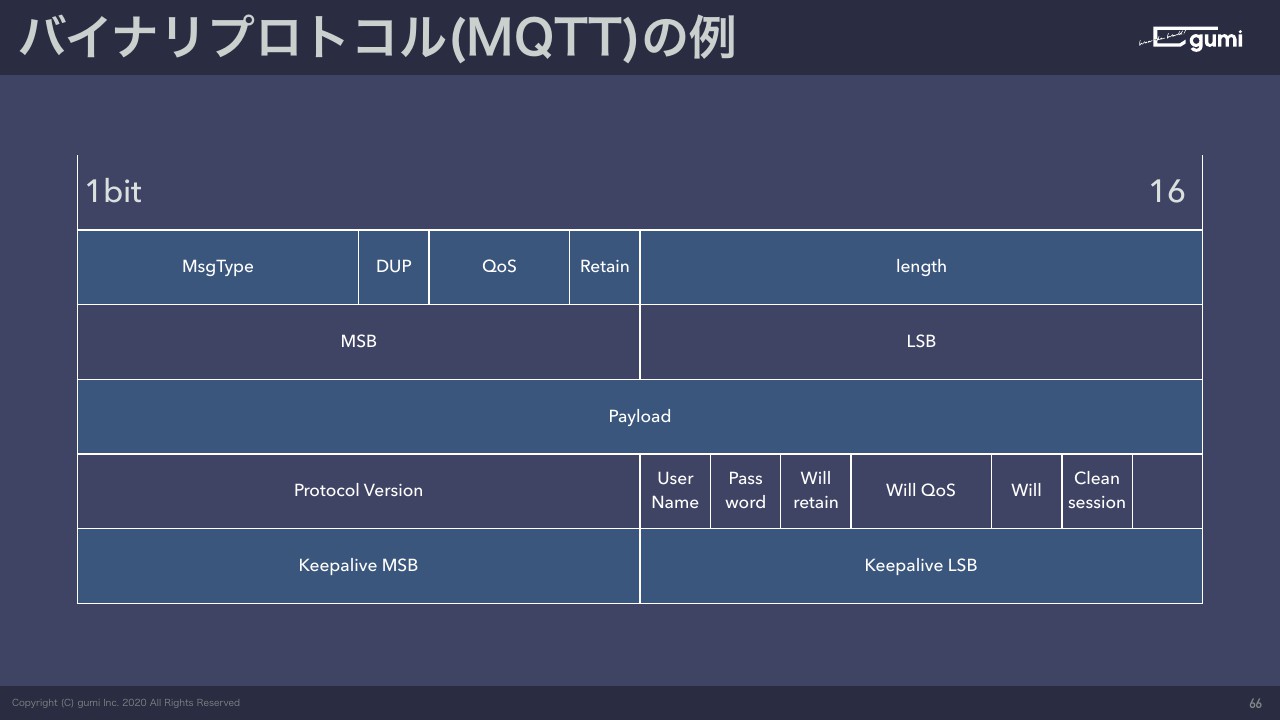
先頭の3ビット分を使ってメッセージタイプという、メッセージの種類ですね。HTTPでいうURLかメソッドみたいなものをここに書きます。これはDUP、あとはQoSというものに3ビット使って、Retainに1ビット使って……ここまでで8ビット分です。つまりJSONでこのキーにはこれを入れるみたいなものを、先頭の何ビットはこれを入れる、この番号にはこれを入れるみたいなのを決めていく作業というのをひたすらやります。
あとは、JSONのAPIでも大きいデータを入れるのに、DATAみたいなキーを使ってテキストを入れたりしますが、バイナリプロトコルの場合は全体のメッセージはどれくらいのサイズなのかを判別する機能が必要です。
全体のメッセージのサイズを数字で、「このメッセージは50バイトあります」みたいなものをここに入れてやり、ヘッダーとPayload、最後は終端、みたいにバイナリプロトコルの設計をします。
こんな感じのことをやっているので、考え方自体は自分たちが普段やっていることと大して変わりません。こんなパラメータが必要だから、32ビットの数字を送りたければ32ビット分のスペースを確保して、ここはダメージの値が入りますみたいなことをひたすらやっていくだけです。
というわけで、MQTTの場合は3ビットとか1ビット単位でデータを扱っていて切り詰めているんですね。なので5種類、6種類とかのデータを8ビット、16ビットの中に収めてる。それで全体のサイズを1ビットでも小さくしようという思想でプロトコルが作られているので、表にするとこんな感じになります。
プロトコルの方針
我々はWebのHTTP APIではそもそも対応ができないけど、1ビットを削らないといけないかと言うとそうではありません。なぜかと言うと、ゲームのデータがそもそも大きいんですよね。なのでここで1ビットを切り詰めるぐらいだったら実装が簡単だったりパースが楽なことのほうが重要です。
なので、プロトコルを設計するときの方針として、数ビットを切り詰めるよりはシンプルになることを優先しました。あとは、ゲームの場合だといろいろな後付けの機能拡張が多くあると思いますが、クラスでパラメータを追加したいみたいなときに困らないように、必要十分な拡張性も求められます。
先ほどの例だと、フラグがすごいいっぱいあるのですが、ここは何も書いていません。ここは予約スペースなんですよね。ここに8ビット分のスペースがあって、7ビットまで使っていて後で何か機能拡張をやるときにここを使えば1ビットフラグが増やせるという設計です。逆に1ビットしか増やせない、次のところには何が入るか決まってしまっているので、この状態だと1ビット以上増やそうと思うと大変です。
ゲームだと急に「ゴールドを増やしたいんです」とか、ゴールド以外にもアイテムを増やしたいとか、配るはずじゃなかったところにガチャ券を配りたいといったことはよくありますが、ここにガチャ券のIDを1ビットで入れるのは絶対に無理なので、そうなるとこういう方針でやっていくのは辛いですね。
なので、そういった機能拡張をするときに困らないようなプロトコルにしたいと思いました。あとはいろいろな言語でシリアライズ・パースがしたい。これはうちの会社特有なのかもしれませんが、そもそもCocos2d-xの頃からUnityに行ったりして、Unityのバージョンが社内でもあまり統一できていなかったり、歴史のあるプロジェクトで古い技術を使っていたりすることがあります。
あとは、サーバー側もC#やPython、Erlang、ElixirやNode.jsなど、いろんな言語が使われているので、バイナリを扱うのが得意な言語とそうでないのがあったりするので、なるべくいろいろな言語でシリアライズやパースがしやすい設計にしようと思っています。
プロトコル構造
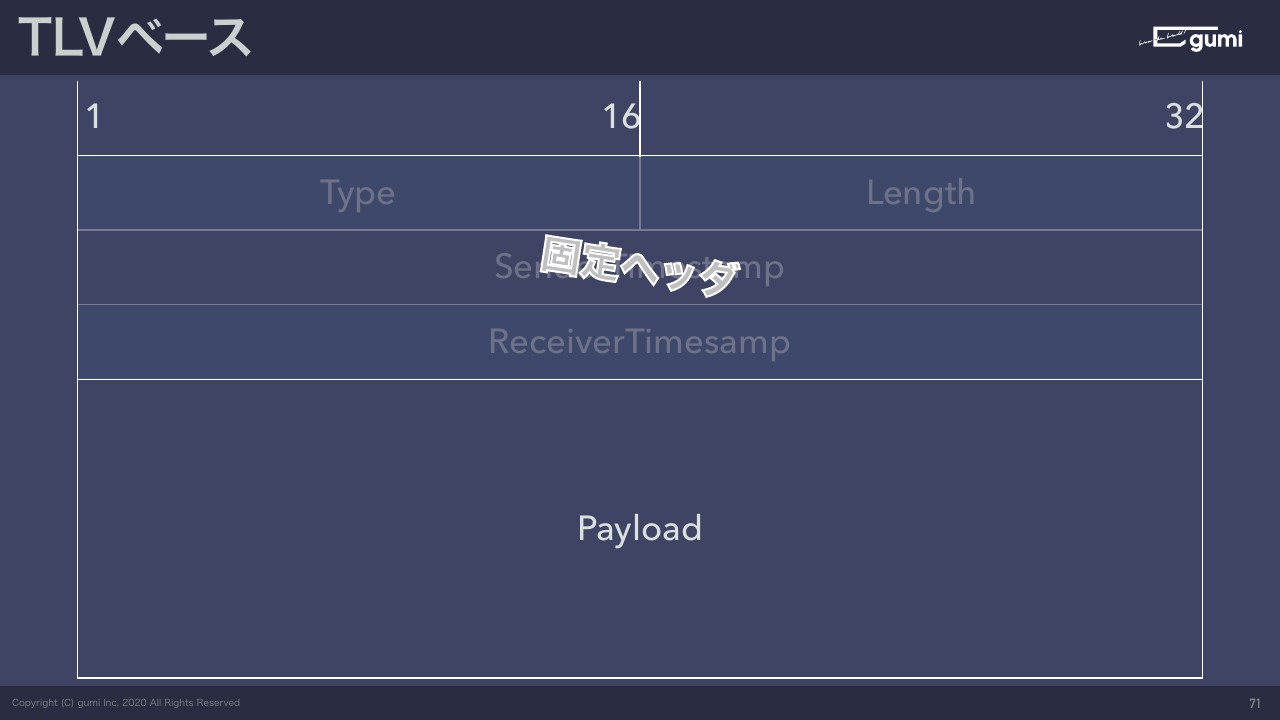
では、実際はどうしたかなんですが、そもそもTCPとUDPのどちらも使う設計にしました。なのでまったく同じコードでいけるようにしてあります。あとで詳しい解説もしますがTLV、Time Length Valueという有名な構造があります。この構造を全面的に採用して作るようにしました。あとは最小限の固定ヘッダ、どんなメッセージにも必ず付く情報をなるべく少なくしました。
あとは4バイト単位。先ほどのMQTTのやつでここの部分のデータは3ビット、ここは1ビットみたいな感じで、ビット単位で切り刻んでいるのですが、ビット単位で切り刻むとバイナリを扱いづらい言語の場合は、そもそも3ビットを取り出すのはすごい大変だったりします。なので、そもそものデータの単位を4バイト単位にしました。データを扱うときは32ビット単位みたいな、すごい大雑把な構造を取っています。
TLV構造を取っている全体のメッセージの構成はどうなっているかという話なんですが、この表はさっきあったMQTTの表とだいたい一緒で、違うのは一番右が32ビットです。

なのでここからここまでは既に16ビットなので、先ほどの表より倍長いです。ですのでスケール感としてはこの上の2行分ぐらいにMQTTの広い表1個分ぐらいの容量を使っています。
TLVはどこのことかと言うと、このTypeですね。メッセージのタイプです。このメッセージはどんな意味を持っているのかというTypeが最初に来ています。ここは16ビット使って数値を入れていく。それに対して次の16ビットでこのメッセージは何バイトあるかというのを、このLengthを16ビットのint値で表して、このメッセージが何バイトあるかをここで表現しています。
なので、全部のメッセージが32バイトだったらこのLengthのところに32と入ります。この後ろに32ビットずつ使って、タイムスタンプの情報が入っている。そしてその後ろにペイロードですね。ここに各メッセージの固有の値がどんどん入ってくるという構造を取りました。
そもそも入っているのがすごい少ない。容量は使っているんですよ? さっきのMQTTはここであれだけの情報を詰めていますから。パラメータ5個だけで、MQTTの4倍ぐらい使っている感じです。
ペイロードの構造について
そのペイロードの構造もTLVにしました。

これがTLVとして一番シンプルなかたちでType、Length、Valueがあります。ValueはLengthが表現している範囲だったら別にいくらでもいい。16ビットなので60,000バイトぐらいしかそもそも表現ができないんですけど、そもそも1メッセージなので、これを秒間10回も送るのを想定しているので、ここで1ギガバイトとか使われても困ります。そのため別にLengthにたくさん入らないと困るということはないです。
先ほどの固定ヘッダ、タイプ、Length、タイムスタンプの2つとペイロードで、上が固定ヘッダなので、このペイロードの中がSectionType、SectionLengthが入っています。
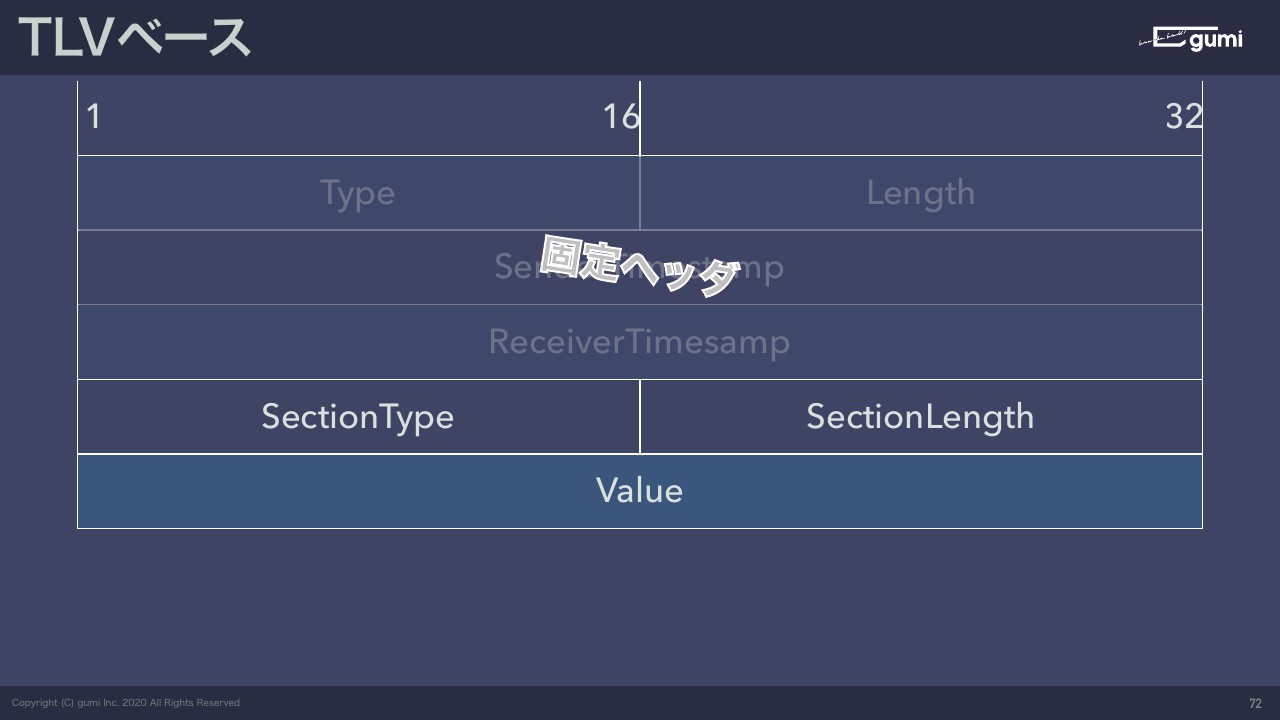
セクションが増えるとそこにつながっていく。右上のLengthがその全体のサイズを常に表現しているという構造を取っています。

なのでセクションは別にいくら増えてもいいなと思っているんですけど、なのでセクションが4つ、5つ必要なメッセージとかも作れます。
この構造のメリットは先ほども言った通り拡張しやすくて、細かいビットの演算をしなくていいので実装が比較的容易です。あとは32ビット単位、4バイト単位なのでintにぶち込めばとりあえずデータをそのままパースできます。逆に言えばintに入れればとりあえずそのまま使えるので実装が楽です。
全体のサイズが合っているかもLengthを見れば一発でわかるしメッセージタイプを見れば必要なセクションがあるかどうかも一発でわかるので、パースはほぼ一発で終わります。
メッセージタイプの一覧
というかたちでメッセージタイプを作ったんですが、全部で20個ぐらいのメッセージタイプを作りました。
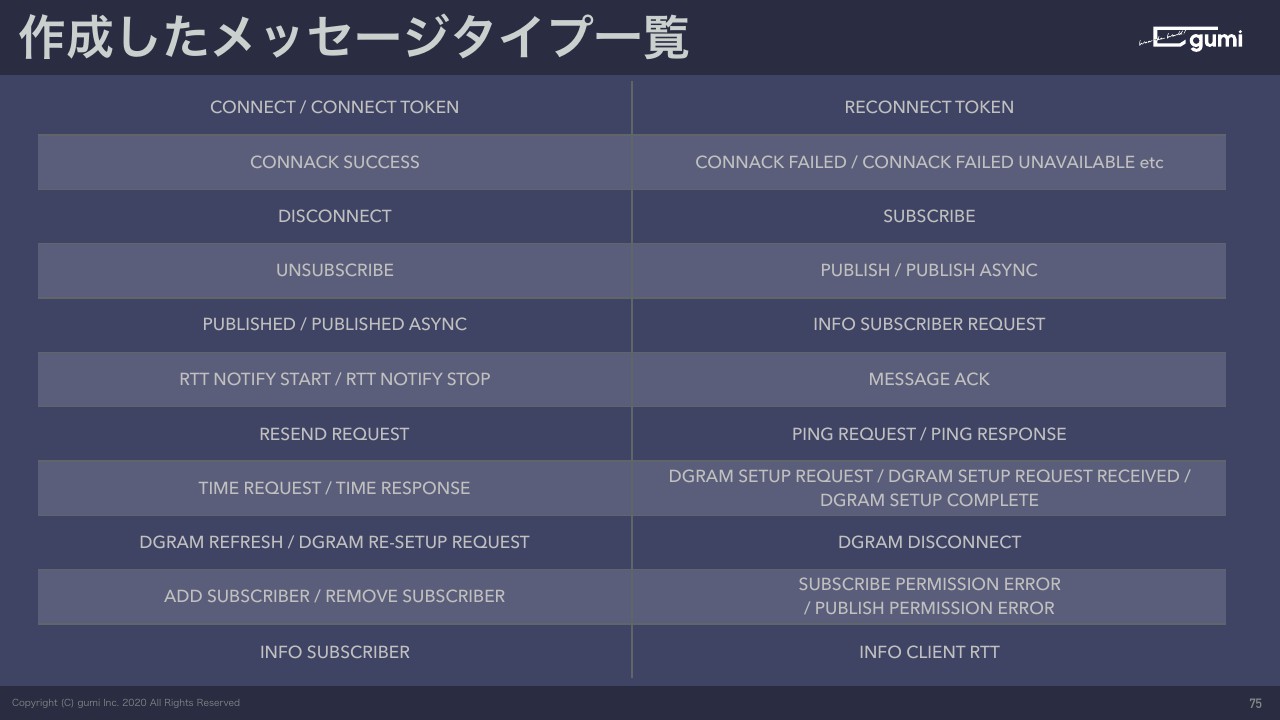
最初に作ったのは10個ぐらいのメッセージだったんですが、あとから「こういうパターンがやりたい」ということでいろいろとメッセージ作っていった結果これぐらいのメッセージ数になっています。
とりあえずサンプルとしてサブスクライブするメッセージの構造を見ていきましょう。
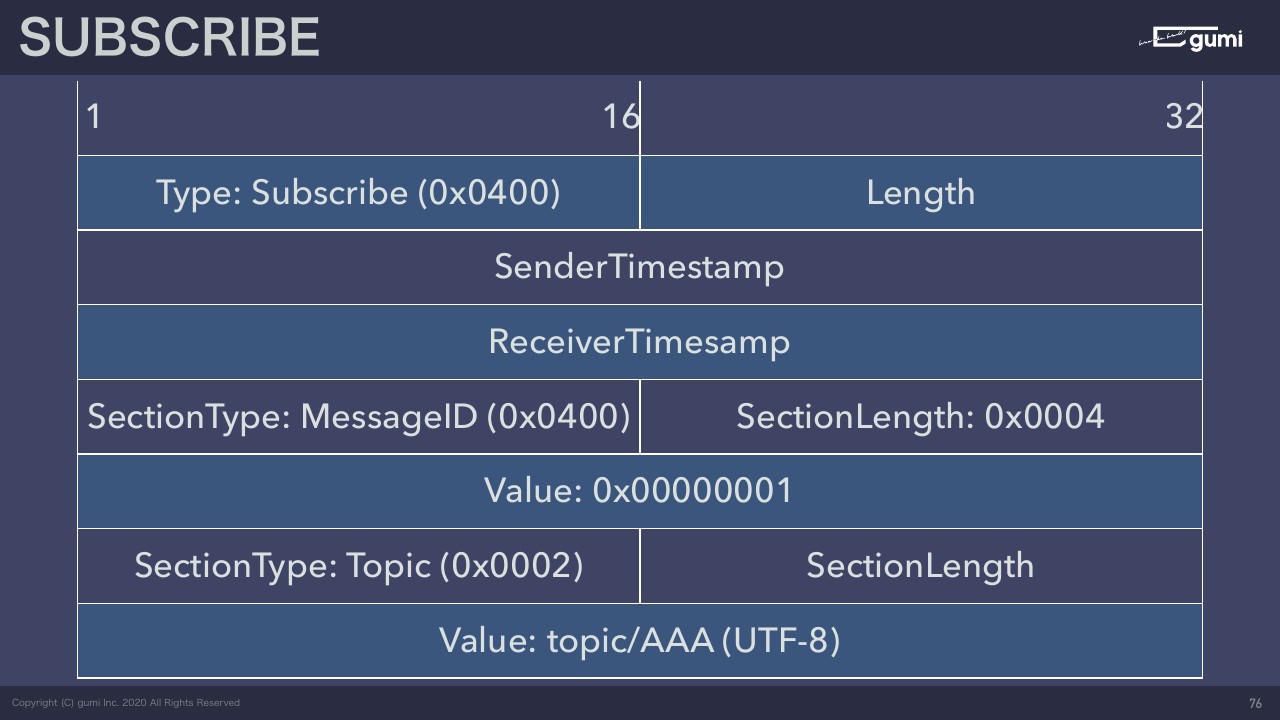
サブスクライブのメッセージタイプに0x0400という数字を割り当てました。これはプロトコルの仕様としてそう決めました。ここに0x0400と入っていたら、ここのメッセージはサブスクライブする。
Lengthに全体のサイズがあって、タイムスタンプが2つくっついて、サブスクライブには必要なセクションが2つあると定義して、セクションはメッセージIDという、今日はあまり詳しく話さないんですが到達保証をするためのメッセージ一個一個につけるIDがある。もしクライアントがメッセージを受け取るのに失敗をしてもサーバー側で再送して必ずクライアントが受け取るようにしますよというためのIDです。
あとは、そもそもどのトピックをサブスクライブするかという、トピック名を入れるセクション。SectionType に0x0002が入ってたら、ここから先のValueにはトピック名が入っていることが確定しているので、ここのSectionLengthを見れば、この文字列の長さがわかって、あとはUTF-8の文字列を普通に解釈してあげればサブスクライブしたいトピックがわかるという感じになります。
一応セクションを同時にいくつもサブスクライブしていいことにしたので、最後のトピック××のセクションが5個とか10個つながっていれば、1回のメッセージでたくさんのトピックをサブスクライブすることもできます。
こんな感じで一個一個のプロトコル、メッセージタイプがAPIの1個で、それに対してどんなパラメータが必要なのかというのをセクションで表現するというのをやっていて、20個ぐらいAPIを作ったらPub/Subすることができるようになりました。