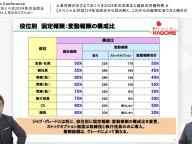
パラレル化で複数CPUコアを駆使
柴田長氏:続いていきましょう。

「パラレル化で複数CPUコアを使いこなせ!」、ミッション3です。先ほどパーティション化したCPUバウンドのSQLのアクティビティを見きました。8つのCPUコアがありますが、どうしても1CPUコアのボトルネックになっていました。これ、もったいないですよね。

なぜ起きるかと言うと、SQLの実行ではCPUコアが1つしか使えません。なぜならば、クライアントからSQLが投げられるとOracleのInstance上ではSever Processが1人だけフォークされます。
その1つのプロセスが全データを読み取って演算処理を行うので、1つのプロセスしかないわけです。そのため、1つのCPUしか使えないです。これはもったいない。

これを解決するのが、みなさんご存知だと思いますが、パラレル実行がありますね。これはクライアントからSQLが投げられると、Query Coordinatorというプロセスが、コーディネータープロセスが1つ立ち上がります。
その下に子分、Parallel Execution ServersというPROCESS文が起動しますので、子分たちが実際にデータを読んで演算処理をする。こういうことができますので、1つのSQLで、SQL文を書き換えることなく、複数のCPUコアを同時に使うことができます。
おもしろいのは、下のTableですね。重複して読まないんですよ。子どもたちのプロセスたちは同じデータを一切読みません。これはパーティション化していない表であっても、きれいに分割して子分たちが読みます。
なので、パラレルクエリを使うことによってデータの読み込み量が増えるといったことは絶対にないです。これは安心してください。
パラレルクエリを実施
では実際にどうやってパラレルクエリを使うのか。どうやってパラレル実行を使うのか。本日は2つの方法をご紹介しましょう。

1つは、手動です。手動で強制的にパラレルの指示が、「alter session force parallel query parallel n」です。このnには数字を書きます。パラレル度ですね。これをSELECT文を実行する前に1発打つ。これだけですね。そうすると、そのあとで実行するSELECT文がパラレル化する。
もう1つは、パラレル度をいくつにしたらいいかがわからない場合には、自動パラレル度設定があります。これはOracle Database Instanceの初期化パラメータPARALLEL_DEGREE_POLICYといったパラメータがありますので、これがデフォルトのマニュアルです。
無効になっています。これをLIMITED,AUTO,ADAPTIVEという3つのどれかに変更することで、1度パラレル設定が有効化していきます。
それによって実際に大量のデータを読む。パラレル化したほうがいいとOracle Database自身が判断した場合にパラレル化される機能があります。小さいデータなのでパラレル化しないほうがいい場合にはパラレル化されません。Oracle Databaseに完全に任せるのが画面の下ですね。
ほかにもパラレル関連のパラメータはホワイトペーパーにも記載がありますので、ぜひ参考にしてみてくださいね。

実際に、今回は手動で一気にやっちゃいましょう。alter session force parallel query parallel と打ちます。1コアしかないんですけども、ハイパースレッドオンなので、16にしてみましょう。16にして、@query_CPUでポンと打つ。これだけ!
 これでもうパラレルクエリが動いているんですね。SQLは変えていません。本当かと不安な方はEnterprise Managerです。Enterprise ManagerでどんなSQLが今流れているのかと見ると、流れています。実行されています。
これでもうパラレルクエリが動いているんですね。SQLは変えていません。本当かと不安な方はEnterprise Managerです。Enterprise ManagerでどんなSQLが今流れているのかと見ると、流れています。実行されています。
1CPUコアボトルネックを突破
パラレル化されているかどうかは、この一覧でパラレルという列で16と入っています。先ほどalter sessionでパラレル16と強制したので、今、このSELECT文はパラレルで動いています。
SQL文はcq2ですよね。CPUバウンドです。なんと、もともと1.1分かかっていたものが19秒で終わるようなことが起きます! すごいですね。

本当かどうか見てみましょう。実行時間が19秒。データベース時間が19秒ではなくなっています。これは19秒のうちに、たくさんの子分が動いたので、その累積がデータベース時間になっていますね。
IOバイト数6ギガバイトで変わってないです。パラレル化してもI/O量が変わらない、増えないと最初に私が言った通り、変わっていません。

では1CPUコアボトルネックだったのか。これはどう変わったのか。小さくて見えないですけども、緑色がCPU使ったところです。同時にハイパースレッド込みの16ギガバイトを使っている傾向が見えます。
なので1CPUコアボトルネックを突破して、壁を突破して複数CPUを同時に使ったことをこの画面からも見てとれると思います。
パラレルクエリの効果と恩恵
もう1つ、I/Oバウンドもあります。これも@query_IOと投げます。こちらはもともとI/Oがボトルネックの状態です。いくら複数のCPUを同時に使えたとしても、I/Oがボトルネックですから、ほとんど改善しません。

所要時間が72秒から20秒になりました。CPUバウンドで1CPUコアがボトルネックでしたからね。パラレルクエリの効果恩恵が非常に高かったです。こういう状態だったのが、CPUが緑色のところが増えました。
ただ、暗い緑色というかブルーありますよね。これがI/O待ちです。I/O待機を示していますので、この時間がまだまだ長いのがここから見てとれます。
I/Oバウンドは、実際にデモではお見せしていませんでしたけども、あまり変わりません。20秒です。こんな感じでほぼI/Oバウンドのほうが今回のSQLはパラレルの効果がない。そのため、SQLによって機能に効果があったりなかったりします。それを少しお見せしたかったのです。

なぜならば、ここにある通り、データベース時間の青いところはユーザーI/Oの待機時間が多い。つまりユーザーI/Oがボトルネック。複数CPUを使いこなすことはできません。

CPUバウンドのSQLは20秒まで、5.4倍まで高速化しました。
データ圧縮でI/O量をより削減
続いてのライブチャレンジいきましょう。
次のミッション4は、「データ圧縮でさらなるI/O量の削減を狙え!」です。CPUバウンドのSQLもI/OバウンドのSQLもどちらも、まだまだIO待機時間が長かったですよね。それをなんとかしたい。そこで登場するのが、表圧縮機能になります。

Oracle Databaseはいくつかの表圧縮の方法をサポートしています。圧縮というと、どうしてもディスクスペースを節約する話になります。今回はそうではないです。今回はパフォーマンス観点で圧縮が効く話をしたいです。
圧縮すると、Oracleのレコードを管理しているデータブロック……例えば1つのブロックの中に10レコードしか入らなかったもの圧縮すると30レコード入るんですよね。
つまり3倍圧縮されていますから、I/Oする回数が3分の1で済みます。そういうことが圧縮で行われます。そのため、総ディスクI/O回数が削減してディスク待機時間が減ります。
もう1つ、今回は関係ないですけども、キャッシュヒット率が向上します。なぜならば、左側の絵でまず非圧縮の表をOracle Database 、DBサーバ側に読みこみます。そこでI/Oがボトルネックになってしまうという図です。
I/Oがボトルネックということは、DBサーバ側のCPUで演算処理しているデータが届かないので、CPUが使えません。待っている状態なんです。メーターがぜんぜん回ってない状態です。
一方、圧縮してしまえば、ディスクI/O時間が短いです。圧縮されたままDBサーバのメモリ上に持ってきます。その上で展開しますから、ディスクI/O時間は短いです。もう手元にデータがすぐ来ますから、CPUをブン回すことができるということで、メーターが回っている。そんなイメージですね。
データ圧縮の方法

圧縮の方法はたくさんあるんですよ。小さいですけども、マニュアルの抜粋です。基本圧縮、高度な行圧縮、ウェアハウス圧縮、アーカイブ圧縮。たくさんあるんですけども、本日はこの赤いところで印を付けた高度な行圧縮をお見せしましょう。
これはなぜかと言うと、圧縮レベルが高いです。CPUオーバーヘッドが低いです。向いているアプリケーションはOLTPとDSS、Decision Support System。だからデータウェアハウス系ですね。どちらにも向いている圧縮形式がありますので、こちらを使ってみましょう。
実際にこれは圧縮しましょう。ただコマンドはそんな難しくはないんですが、「@Enable_Compression」と打っていきます。
alter table SALESのmove partition、あるpartitionをrow store compress advancedという圧縮形式に変えます。しかもonlineで、という句を付けています。

少しご紹介しますね。圧縮表はもともと、初めて表を作るケースでCREATE TABLEと打ちます。その際にrow store compress advancedと付けていただければ、高度な行圧縮、表圧縮が有効な表を作れます。もともと表があり、データが入っている場合には2種類の方法があります。
今後、INSERTされてくる新規のデータのみを圧縮する場合には、その表の属性を変えるのでalter table modify partition compress。partitionと書いているのは、今回は表全体ではなくて、パーティションで紹介したある特定の分割された部分、ある部分だけを圧縮することができますので、参考に書いています。
すみません、脱線しました。もう1つは、既存の格納されている表の中に入っているレコードも含めて圧縮したい場合には、alter table move partition compress ~と書いていただければいいです。
さらに、ここにonlineという句を付ければ、圧縮中にも更新処理アップデート、インサート、デリート処理を受け付けられるようになっています。これも12cの機能ですね。これは便利です。
もともと表のオンライン再定義という、一番下に小さく書いてあり、これを使ってもできます。コマンド一発でできるonline句は非常に便利ですから、使ってみてください。
I/Oバイト数、ディスクI/O時間が削減

(画面を見て)どうでしょう。圧縮が終わっています。まだクエリは変えません。@query_CPUと実行してみましょう。これはEMに切り替えてなくても、すぐ終わると思っているんですけども……はい、終わりました! 9秒ですね。8.57秒。CPUバウンドのほうも結局はまだまだI/O待機時間が長かったので、圧縮の効果があったということです。

あとで見ますけどね。@query_IO、こちらも実行しておきましょう。こちらもおそらく同じくらいの速度で返ってくるはず。はい、7秒ちょっとですね。

少し整理します。せっかくですから、EMで見ましょうか。実行したCPUバウンドは、alter sessionを先ほどパラレルクエリで有効化していますから、そのままパラレル実行されています。16で付いています。

CPUはcq2でしたよね。こちらです。実行時間が約9秒です。どうでしょう。I/O時間がだいぶ減っていますよね。というのも、I/Oバイト数はもともと30ギガ。パーティション化して6ギガですね。さらに今回圧縮をして2ギガまで縮んでいる。縮小できています。
ディスクI/O時間がもともと30ギガまで読んでたものが2ギガです。もうその時点で15倍くらい、ディスクI/O時間が短縮できていることがわかります。非常に便利ですね。

もう1つ、I/Oバウンドのほうも同じです。I/Oバウンドも、もともとSALES表の30ギガを読んでいましたけど、これがパーティション化して、さらにそのパーティション部分を圧縮することで高速化を実現しています。7秒ですね。IOバイト数は2ギガまで縮んでいます。
ただ、まだこれ見てくださいね。データベース時間の内訳は、このI/OバウンドのSQLがまだまだユーザーI/Oが93パーセントなんですよ。CPUが6パーセントなので、ここからはディスクを速くすればいい場合もあります。
ただ、ここでもう1つチャレンジしていきましょう。

ここまで整理すると、CPUバウンドのSQLは108秒から9秒です。12倍速くなっています。I/OバウンドのSQLは90秒から7秒、こちらも12倍まで速くなっている。ただし、まだまだI/Oバウンドは、I/O待機時間が90何パーセントを占めていますので、これをなんとかしたい。
インメモリ化で1秒を切る

ここで出てくるのがミッション5、最後ですね。「インメモリ化で1秒の壁を越えろ!」です。越えられるか!? Database In-Memoryという機能がOracle Database 12c Release 1から使えるようになりました。これは技術者として非常におもしろい機能です。従来のOracle Databaseと変わりません。
右に絵がありますけど、SALES表がディスクストレージ上にのっていますけども、これはこれまで通りです。右側にバッファキャッシュという枠がありますけども、これもみなさんが使っていただいているOracle Databaseのキャッシュ領域ですね。
それとは別に右側にNewと書いています。In-Memory Column Storeとありますね。これがDatabase In-Memoryで使用するメモリ領域です。
これを見ていただくとわかる通り、ディスク上はこれまで通りロー型なんですよ。レコード型で持っているんですよ。あくまでトランザクションもバッファキャッシュで売上データとかインサートされてきて、更新できます。
けれど、それと別でカラム型、分析用に便利な列型でメモリ上だけで列型を実現してアナリティクスで使うことができるハイブリッドですね。データベースを変える必要はないです。同時に利用できます。
売上データがどんどん入ってくる、それを右側の列カラム型で分析をかける。Database In-Memoryを使えば、これが実現できるんですね。SQLは制限ないです。どちらのデータを使った方がSQLの処理が速いのかも、Oracle Databaseが勝手に判断しますので便利ですよ。

さらにIn-Memory独自のデータスキャンの高速化、ジョインの高速化、インメモリーの集計の高速化。こういったものもIn-Memory独自の高速化を提供しています。
 どう使うのかが重要ですよね。このIn-Memory Column Store用のメモリー容量を指定しないといけないです。それが初期化パラメータのinmemory_sizeなんですけど、これを設定する。どれだけのキャッシュ領域、In-Memory Column Storeでキャッシュするかという領域ですね。
どう使うのかが重要ですよね。このIn-Memory Column Store用のメモリー容量を指定しないといけないです。それが初期化パラメータのinmemory_sizeなんですけど、これを設定する。どれだけのキャッシュ領域、In-Memory Column Storeでキャッシュするかという領域ですね。
では、そこにどの表を乗せようか。2番のステップに書いてある通りalter table文でinmemoryの属性をmodifyで変えてもらえればいいです。このSALESは今回30ギガくらいあるんですけども、そのうち今回のクエリで使用するパーティションだけをインメモリ化している例です。
不要な索引を消すべし

それでは、さっそく打っていきましょう。@Enable_DBIMに予約を書いていたので、こんなかたちで、alter table SALES modify partition パーティション名 inmemory priority high。
少し優先的にあげてね。キャッシュしてね。インメモリ化してね……。もうこれだけで終わりです。ピピピと終わりましたよね。
もう1つ、よくDatabase In-Memoryを紹介を受けると分析クエリで使用していた不要索引を削除できると謳っています。

この効果を改めて補足説明させてもらうと、分析クエリを高速化するために索引を作るケースが多いと思います。Database In-Memoryを使うことで、その索引は分析クエリには使用しなくなります。
そのため、ぜんぜん使わないので放置してもいいんですよ。ただ、放置しているとなにが起こるかと言うと、このDatabase In-Memoryはデュアルフォーマットといって、ロー型も残っていますよね。売上データがどんどんインサートされてくるわけです。
そのときに索引があると、レコードが挿入されてくるために索引のメンテナンスが行われるんですよ。例えばSALES表に100個も索引があったら、1レコード入るたびに100個の索引をメンテナンスしないといけないんですね。これは無駄です。非常に無駄です。
不要な索引を消すことでなにが速くなるかと言うと、オンライン・トランザクションのインサートです。索引を消したからといって、分析のクエリが速くなるわけではないです。あくまでオンライン・トランザクション側の高速化が見られます。
ではどの索引を消したらいいのか。12.2だとDBA_INDEX_USAGE ビューが提供されています。従来通りalter index monitoring usage ; usageというコマンドも使えますので、ぜひマニュアルを読んでみてください。
デモが終了

ということで、実際に実行してみましょう。@query_CPUは変えません。どうでしょう? こちらはCPUがボトルネックで、I/O待機時間がなかったのでそれほど改善しません。7秒です。

一方、@query_IO側はどうでしょうか。 0.66! 0.41! こんな感じで、Database In-Memoryを使うことでI/OバウンドのSQLが1秒を見事に切りました。よかった! デモが全部終わった(笑)。そんな感じです。

少し整理すると、CPUバウンドのSQLは、直前まで9秒だったのが7秒くらいまで改善しています。EMの画面を見ていただくといいんですけれども、IOバイトが圧縮することで2ギガまでI/O量を減らすことができていましたが、これが34メガバイトまで削減できています。
0を目指したかったんですけども、SQLの中で一時表にIOする部分がどうしても34メガだけ、残ってしまいました。ただCPUバウンドなので、もともとCPU時間の割合が高いですよね。そのため、改善幅は大きくないです。
一方、I/Oバウンドは、7秒が1秒以内、今0.41まで改善しましたね。これもI/O時間がゼロですから、ほぼゼロ。DBIMの効果が非常に高くなったと言えます。

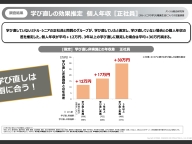
整理します。Live Challenge! CPUバウンドのSQLは108秒からスタートしましたけれども、14倍まで高速化できました。1秒の壁は無理でしたね。CPUを積んでもっとパラレル度を上げるようなことが必要かもしれないですね。
I/OバウンドのSQLは、90秒だったものが0.41、214倍まで高速化することができます。SQLを変えてないですからね! SQL文を一切変えずにここまで高速化できると今デモでお見せしたので、ぜひみなさんもチャレンジしてもらいたいと思います。
「時間=道のり/速さ」が肝要

簡単に言うとパフォーマンス・チューニングは、SQL文を書き直して効率的なSQL文の書き方もあると思います。私、実はそんなに書けないんです。しかし、超有名な公式ですね。時間=道のり/速さ、小学校で習いましたよね? こういう考え方です。
SQLの実行時間を短くして下げたいならば、分子である処理量を下げる。もしくは分母である速さを上げる。こういうシンプルな考え方ですよね。
例えば、処理時間を下げる方法は今回お伝えしたようにパーティショニングを使ってディスクI/Oをする、データアクセス範囲を絞るなど、コンプレッションをすることで実際にディスクから読み込むデータを減らす。処理量を減らすことですよね。
高速化、速度を速くするためには、ハードディスクが低速ですから、メモリーの圧倒的な速度を使うDatabase In-Memory。並列化は1つのCPUだけでは処理がいっぱいいっぱいですから、複数のCPUを同時に使う並列化ということでパラレルクエリがいけると思います。

Oracle Database 12c Release 2、機能がけっこう充実してきています。実はこういう話って6年前にもしているんですが、そのときはEnterprise Editionを使わないといけないとか、オプションを使わないといけないとか、けっこうお金がかかる機能を紹介していたと反省しています。
最近だとようやくOracle Database Cloudサービスで安く、高級な機能を使うことができるようになっています。30日間のトライアルが出来ますので、ぜひ申し込んでチャレンジしてみてくださいね(トライアル申込みはこちら)。
ということで、私のセッションは以上となります。ご静聴ありがとうございました。
(会場拍手)