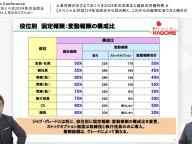
「JSON検索インデックス」の使い方
井上克己氏(以下、井上):さて次ですが、もうちょっと凝った検索をしてみましょう。12.2の新機能を使ってみます。12.2で「JSON検索インデックス」という機能が追加されました。

実体はOracle Text索引をJSON用に拡張したような機能です。この機能を使って検索をしてみたいと思います。
ステミングという動詞の変化形などをひっかける機能があるんですが、そこをお見せできればと思います。
編集のときは、Ctrl+Aにdeleteで全部消えます。ここでJSON Text Indexを作っていきます。「create search index インデックス名 on テーブル名 (カラム名) for JSON」で、Ctrl+Enterですね。これでJSON検索インデックスが作られます。「Index created」と。
なので、例えばセッションタイトルを検索していきす。「テーブル名」、新しいオペレーターがあります「json_textcontains(カラム名, 」、JSONのキー名「’$.title’ , 」。タイトルというのはJSONのキーでしたよね。
そしてステミングでどういう単語でひっかけたいかというと、ストリーミングに関するもの、またはコンテナに関するもの。
先ほどもコンテナの話がありましたが、こういったタイトルのストリーミングに関するもの、またコンテナに関するOracle Codeのセッションがどれぐらいあるかを出してみました。けっこうありますね。

セッションタイトルなので、基本的に頭文字が大文字になっているのでステミング検索をしてみました。複数形、streams、sがついたかたちや、動名詞、ingがついたかたちでもひっかかります。もちろん複数形も大丈夫です。
けっこうcontainerとかstreamに関するセッションがありますね。
Oracle Codeのセッションの傾向を調べてみる
次の例ですが、全般的にOracle Codeのセッションにどういった内容が多いのかを見ていきたいと思います。
今、Schemaをクリックしました。すると、「DR$」というテーブルがいくつかありますね。

これは、実際にはJSON検索インデックスが内部的に使うテーブルです。なので、通常はここを見ることはないんですが、今回おもしろいところがありますので、見ていきたいと思います。
「DR$HOGE$I」テーブル。これ内部テーブルですが、このテーブルに単語、JSONテキストが300件ぐらいありましたが、そのなかでどの単語が頻出しているか、だいたいの傾向を見ることができます。

5番目のカラムに「TOKEN_COUNT」とありますので、ある単語が何回出てきているのか、ここに集計されているはずです。なので、このテーブルに対してQueryをかけて見ていきます。
「where token_type=0 order by 5」でCtrl+Enter。
日本語も入っていますね。

ただ、上のほうは頻出度が少ない単語、下のほうにいきますと、頻出度が多い単語です。
「CLOUD」「JAVA」「DEVOPS」「MICROSERVICES」といった単語がOracle Codeのセッションで使われていることがわかりました。
ここまでがJSON検索インデックスですね。
PL/SQLも使えます
次にPL/SQLのデモをお見せしたいと思います。
今まではSQL文しかお見せしてないんですが、PL/SQLも当然試すことができます。PL/SQLの例はすでにアップロードしてありますので開いてみます。PL/SQLは、トリガーやストアド・プロシージャ、パッケージなどで書かれる方が多いと思うんですが、無名のブロックでも書けまして、Pythonに埋め込むことも可能です。Live SQLでも無名PL/SQLブロックを動かすことが可能です。
ここではいったんコピペしてやってみます。Ctrl+Cでコピーして、SQL Worksheetでやってみます。

ここでやろうとしていることは、先ほどのoracle_codeというテーブルで、セッション名に位置情報、geospatialな関連するセッションがあったら、companyキーの値の文字列を変えてあげましょう。
つまりJSON文字列の一部だけを更新する例です。これは現時点ではSQLだけではできないのでPL/SQLでやる必要があります。
実行してみます。実際のテーブルを見にいって、1行だけあったデータのこのcompanyキーの文字列を変えました。

このセッションはこの部屋で16時40分からやることになっていますが、そのデータの値を書き換えました。テーブルの値をUPDATE文で更新することも可能です。
今の例では、dbms_output、SQL*Plusでもよくやることがあると思うんですが、そのput_line関数を画面に出してみたという例でした。
あとはすこし戻りますがこれも12.2の新機能で、メソッドとしてはこういうものがあります。
あまり説明していないのが、オブジェクトの型名ですが、オブジェクトの型名としては、JSON_ELEMENT_Tタイプと、JSON_OBJECT_Tタイプ、あとJSON_ARRAY_Tという、3つのオブジェクトの型が12.2から使えるようになっています。
他の言語をSQLに埋め込む
ここまででJSONが終わりですね。次の例ですが、RubyやJava、Pythonの言語にSQLを埋め込んでみましょう、という例になります。
このスライドは見たことある方もいらっしゃると思います。

オラクル社で各言語に対応するOracle database access driverというものを出しているところが、この青と赤のところですね。ただ、青のところはオープンソースになっています。
あとはオラクル社員じゃなくてサードパーティの方がaccess driverを出しているのをご存じの方も多いと思うんですが、RubyやPerlになります。
Live SQLもこれに関連する機能がありますので試してみます。サンプルコードを表示してくれる機能があります。
ハンバーガーメニューのSchemaで、対象オブジェクトがテーブルの場合には、右下にサンプルコードへのリンクが出てきます。

例えば、今Schemaでテーブルを開いていますね。するとこの右のハンバーガーメニューのところで「Java」が出てきます。

このサンプルではSELECT、INSERTが出てきます。これを実際に使ってアプリケーションを作ってみたいと思います。

今、開いたのはNetBeansというツールです。これで単体のアプリケーションを作っていきます。すこし時間がないかもしれないので、説明なしでいってしまいます。
今、import文がありましたが、import文をここにコピーします。

次に、本体もコピーします。
実はいくつか間違いがありますので訂正していきます。where句は今回は使いません。ユーザー名パスワードは合わせます。接続文字列も変えます。
今、NetBeansというIDEを使っていますので、コンパイルできないとコンパイルする前にエラーがわかります。赤いところですね。

(画面には)「JDBCパッケージが見つかりません」。パッケージのプロパティでJDBCドライバのJavaファイル、最新版は「ojdbc8」ですね。するとエラーが消えました。
こんな感じで作っていって、「Connectionクラスが見つかりません」というエラーがあります。なので、import java……自動補完もします。Connectionですね。
こんな感じで作っていくと比較的短時間でできます。これを実行していきます。
まだエラーありますね。最低限の変更で動かそうとしていますので、若干読みづらいんですが、これでできると思います。少し結果があれなんですが、NetBeansを使えば比較的少ない変更で実行できます。
あと、1点説明し忘れたんですが、Live SQLは、今作ったデータにSQL*Netでアクセスできないという注意点がございます。RESTインターフェースでもアクセスすることができません。
なので、あくまでも先ほどINSERT文で作ったデータは、このブラウザ内のエディタ画面で各SQLでしかアクセスできないという注意点がございます。
Pythonに挑戦
次にPythonとRubyですね。Pythonというリンクをクリックしますと、Pythonの例、スニペットというか、コードサンプルが出てきます。

今回使ってみたのは、複数行まとめてINSERTするところです。複数行まとめてやるので、Pythonの配列オブジェクトを使います。
実際にはそのままでは動かなかったんですが、少し編集したものをお見せします。非常に短いサンプルなんですが、こんな感じですね。
「cx_Oracle」というのは、Pythonでのaccess driver名です。

次に、接続して、Pythonの中で配列を作ります。INSERTしたいデータを2つ配列で書きます。配列なので角括弧で始まって角括弧で終わります。
実際のバインド変数は1つです。1つなんですが、Pythonですと若干めんどくさい書き方ですね。配列の中にシーケンスを2個書く必要があります。配列の中の要素がシーケンスである必要があります。
こんなかたちで変更して作ってあります。これを実際にPythonで実行してみます。Pythonでの実行に必要なのはドライバですね。これはすでに入っています。
それを確認していきますが、Pythonパッケージ管理コマンドのpipコマンドで見ますと、ここに「cx_Oracle」って入ってますね。

cx_Oracleがすでに入っていますので、先ほどのスクリプトは動きます。
実際にやってみます。環境変数が設定されていないので環境変数を設定してやると、データが2行インサートされました。
これを少しSQL*Plusで確認してみますね。ローカルデータベースに入れました。Live SQLのデータベースは使えないので、別途データベースを用意します。今、INSERTしたデータはこの下の2行ですね。Pythonに関する行が入っています。

RubyとPythonの違いは?
次はRubyをやってみます。RubyはLive SQLではまだ対応していません。
ただ、試しにやってみたので実行してみます。今回はWindowsでやってみます。「ruby -V」とやると、これはCygwinというWindowsのツールの中のRubyですね。そこでやっています。

RubyでOracleにアクセスするのに必要なRubyのgemはすでに入っています。「gem list」とやると、ここにありますね。「ruby-oci8」と入っています。なので、できるはずです。

すでにRubyは作ってありまして。なにを参考にしたかと言いますと、Rubyのマスターのリポジトリの中にtest_ array.dml.rbという名前のユニットテスト用のファイルがありましたので、そこを参考に書き換えてみました。

書き換えた結果が、Pythonをもとに書き換えました。なので、PythonとRubyなのでけっこう違いがありますね。横に並べてみたところですけど、左がPythonで、右がRubyです。

似ているところもありますが、いくつか違います。一番違うのはたぶんこのメソッド名ですかね。Pythonではexecutemanyメソッドです。Rubyだとexec_arrayメソッドというかたちです。

ここでRubyを実行してみます。
ruby.exe……exeは本当はいらないです。Rubyファイルがこのフォルダに1個しかないので。
今、スクリプトを実行しています。2行にインサートされました。なのでデータベースを見ますと、これは先ほどと同じテーブルなんですが、Rubyからインサートした行が入っています。

ということで、お時間になってしまいましたので、ここまでとさせていただきます。本日はご清聴ありがとうございました。